Phần này sẽ tìm hiểu 3 câu hỏi sau:
- Sự khác biệt giữa tập dữ liệu cân bằng theo lớp và tập dữ liệu không cân bằng theo lớp là gì?
- Tại sao việc huấn luyện một tập dữ liệu không cân bằng lại khó khăn?
- Làm cách nào để khắc phục các vấn đề về việc huấn luyện tập dữ liệu không cân bằng?
Tập dữ liệu cân bằng về loại so với tập dữ liệu bất cân đối về loại
Hãy xem xét một tập dữ liệu chứa nhãn phân loại có giá trị là lớp dương hoặc lớp âm. Trong tập dữ liệu cân bằng theo lớp, số lượng lớp dương và lớp âm gần bằng nhau. Ví dụ: một tập dữ liệu chứa 235 lớp dương và 247 lớp âm là một tập dữ liệu cân bằng.
Trong tập dữ liệu bất cân đối về loại, một nhãn phổ biến hơn đáng kể so với nhãn còn lại. Trong thế giới thực, tập dữ liệu bất cân đối về loại phổ biến hơn nhiều so với tập dữ liệu cân đối về loại. Ví dụ: trong một tập dữ liệu giao dịch bằng thẻ tín dụng, các giao dịch mua gian lận có thể chiếm dưới 0, 1% số ví dụ. Tương tự, trong một tập dữ liệu chẩn đoán y tế, số lượng bệnh nhân mắc một loại virus hiếm gặp có thể ít hơn 0,01% tổng số mẫu. Trong tập dữ liệu bất cân đối về loại:
- Nhãn phổ biến hơn được gọi là lớp đa số.
- Nhãn ít phổ biến được gọi là lớp thiểu số.
Khó khăn trong việc huấn luyện các tập dữ liệu bất cân đối nghiêm trọng về loại
Huấn luyện nhằm mục đích tạo ra một mô hình phân biệt thành công lớp dương tính với lớp âm tính. Để làm như vậy, các lô cần có đủ số lượng cả lớp dương và lớp âm. Đó không phải là vấn đề khi huấn luyện trên một tập dữ liệu có sự mất cân bằng nhẹ giữa các lớp vì ngay cả các lô nhỏ thường chứa đủ ví dụ về cả lớp dương và lớp âm. Tuy nhiên, một tập dữ liệu bất cân đối nghiêm trọng về loại có thể không chứa đủ ví dụ về loại thiểu số để huấn luyện đúng cách.
Ví dụ: hãy xem xét tập dữ liệu bất cân đối về loại được minh hoạ trong Hình 6, trong đó:
- 200 nhãn thuộc lớp đa số.
- 2 nhãn thuộc lớp thiểu số.
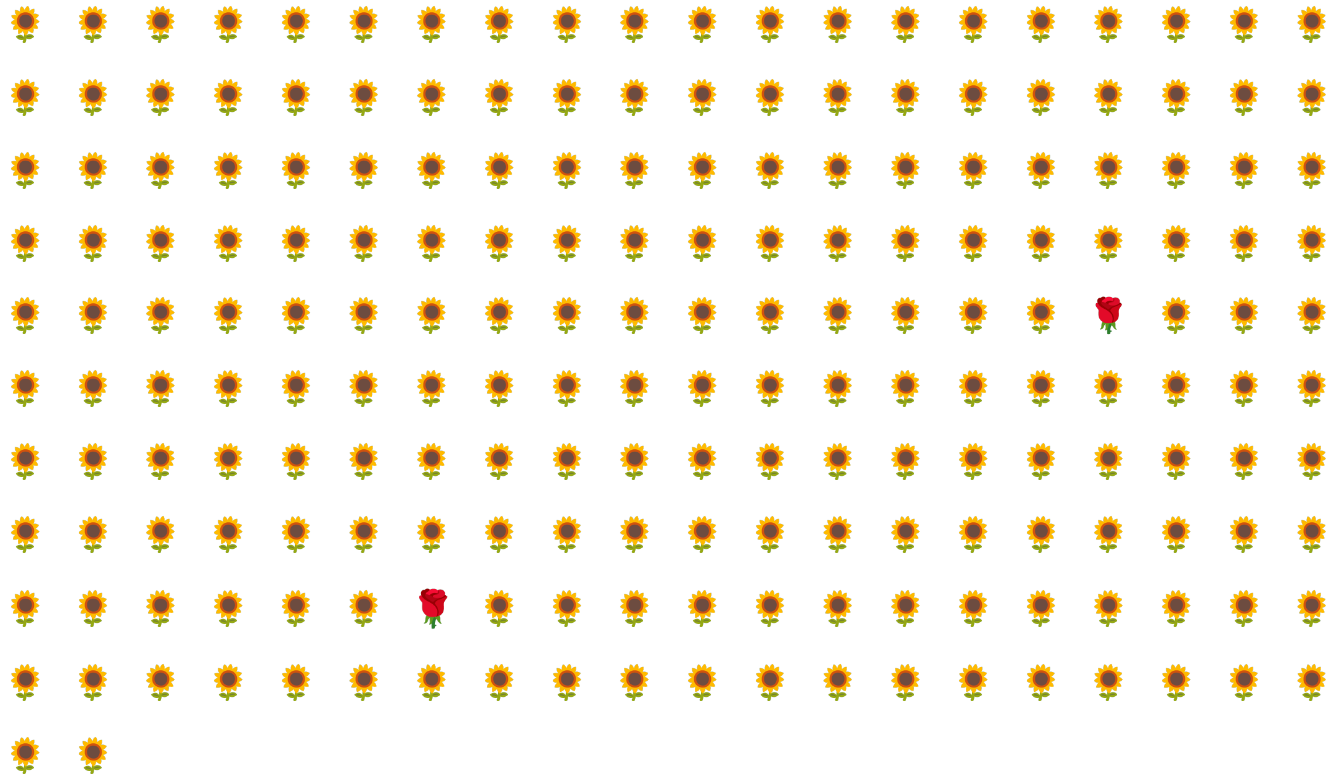
Nếu kích thước lô là 20, thì hầu hết các lô sẽ không chứa ví dụ nào về lớp thiểu số. Nếu kích thước lô là 100, thì mỗi lô sẽ chỉ chứa trung bình một ví dụ về lớp thiểu số, không đủ để huấn luyện đúng cách. Ngay cả khi kích thước lô lớn hơn nhiều, tỷ lệ mất cân bằng như vậy vẫn sẽ tạo ra và mô hình có thể không huấn luyện đúng cách.
Huấn luyện tập dữ liệu bất cân đối về loại
Trong quá trình huấn luyện, mô hình cần học hai điều:
- Mỗi lớp trông như thế nào; tức là giá trị của đặc điểm tương ứng với lớp nào?
- Mức độ phổ biến của từng lớp; tức là phân phối tương đối của các lớp là bao nhiêu?
Hoạt động huấn luyện tiêu chuẩn kết hợp hai mục tiêu này. Ngược lại, kỹ thuật gồm hai bước sau đây được gọi là giảm mẫu và tăng trọng số cho lớp đa số sẽ tách hai mục tiêu này, cho phép mô hình đạt được cả hai mục tiêu.
Bước 1: Giảm mẫu lớp đa số
Giảm mẫu có nghĩa là huấn luyện trên một tỷ lệ phần trăm thấp không cân xứng của các ví dụ về lớp đa số. Tức là bạn buộc một tập dữ liệu bất cân đối về loại trở nên cân đối hơn bằng cách bỏ qua nhiều ví dụ về loại đa số trong quá trình huấn luyện. Việc giảm mẫu giúp tăng đáng kể khả năng mỗi lô chứa đủ ví dụ về lớp thiểu số để huấn luyện mô hình một cách phù hợp và hiệu quả.
Ví dụ: tập dữ liệu mất cân bằng về lớp xuất hiện trong Hình 6 bao gồm 99% ví dụ về lớp đa số và 1% ví dụ về lớp thiểu số. Việc giảm mẫu lớp đa số theo hệ số 25 sẽ tạo ra một tập hợp huấn luyện cân bằng hơn một cách nhân tạo (80% lớp đa số so với 20% lớp thiểu số) như đề xuất trong Hình 7:

Bước 2: Tăng trọng số cho lớp được lấy mẫu xuống
Việc giảm mẫu sẽ tạo ra thiên kiến dự đoán bằng cách cho mô hình thấy một thế giới nhân tạo nơi các lớp cân bằng hơn so với thế giới thực. Để khắc phục độ lệch này, bạn phải "tăng trọng số" cho các lớp đa số theo hệ số mà bạn đã giảm mẫu. Tăng trọng số có nghĩa là xử lý tổn thất trên một ví dụ về lớp đa số nghiêm trọng hơn so với tổn thất trên một ví dụ về lớp thiểu số.
Ví dụ: chúng tôi đã giảm mẫu lớp đa số theo hệ số 25, vì vậy, chúng tôi phải tăng trọng số lớp đa số theo hệ số 25. Tức là khi mô hình dự đoán nhầm lớp đa số, hãy coi tổn thất như thể có 25 lỗi (nhân tổn thất thông thường với 25).

Bạn nên giảm mẫu và tăng trọng số bao nhiêu để cân bằng lại tập dữ liệu? Để xác định câu trả lời, bạn nên thử nghiệm với các hệ số giảm mẫu và tăng trọng số khác nhau giống như khi bạn thử nghiệm với các siêu tham số khác.
Lợi ích của kỹ thuật này
Việc giảm mẫu và tăng trọng số cho lớp đa số mang lại những lợi ích sau:
- Mô hình tốt hơn: Mô hình kết quả "biết" cả hai điều sau:
- Mối liên hệ giữa các đối tượng và nhãn
- Phân phối thực tế của các lớp
- Hội tụ nhanh hơn: Trong quá trình huấn luyện, mô hình sẽ thấy lớp thiểu số thường xuyên hơn, điều này giúp mô hình hội tụ nhanh hơn.