Trong bài này, bạn sẽ tìm hiểu thuật toán phân tách đơn giản và phổ biến nhất, tạo ra các điều kiện ở dạng $\mathrm{feature}_i \geq t$ trong chế độ cài đặt sau:
- Tác vụ phân loại nhị phân
- Không thiếu giá trị trong các ví dụ
- Không có chỉ mục được tính toán trước trên các ví dụ
Giả sử một tập hợp gồm $n$ ví dụ có một đặc điểm dạng số và nhãn nhị phân "cam" và "xanh dương". Theo cách chính thức, hãy mô tả tập dữ liệu $D$ như sau:
trong đó:
- $x_i$ là giá trị của một đặc điểm số trong $\mathbb{R}$ (tập hợp số thực).
- $y_i$ là giá trị nhãn phân loại nhị phân trong {orange, blue}.
Mục tiêu của chúng ta là tìm một giá trị ngưỡng $t$ (ngưỡng) sao cho việc chia các ví dụ $D$ thành các nhóm $T(rue)$ và $F(alse)$ theo điều kiện $x_i \geq t$ sẽ cải thiện khả năng phân tách các nhãn; ví dụ: nhiều ví dụ "cam" hơn trong $T$ và nhiều ví dụ "xanh dương" hơn trong $F$.
Entropy Shannon là một chỉ số đo lường mức độ hỗn loạn. Đối với nhãn nhị phân:
- Độ hỗn loạn Shannon ở mức tối đa khi các nhãn trong ví dụ được cân bằng (50% màu xanh dương và 50% màu cam).
- Độ hỗn loạn Shannon ở mức tối thiểu (giá trị bằng 0) khi các nhãn trong ví dụ là thuần tuý (100% màu xanh dương hoặc 100% màu cam).

Hình 8. Ba cấp độ entropy khác nhau.
Về mặt hình thức, chúng ta muốn tìm một điều kiện làm giảm tổng trọng số của entropi của các phân phối nhãn trong $T$ và $F$. Điểm tương ứng là mức tăng thông tin, là chênh lệch giữa entropi của $D$ và entropi của {$T$,$F$}. Sự khác biệt này được gọi là mức tăng thông tin.
Hình sau đây cho thấy một sự phân tách không tốt, trong đó entropy vẫn cao và thông tin thu được thấp:

Hình 9. Việc phân tách không tốt không làm giảm entropy của nhãn.
Ngược lại, hình sau đây cho thấy một cách phân tách tốt hơn, trong đó entropy trở nên thấp (và thông tin thu được cao):

Hình 10. Một phần phân tách tốt sẽ làm giảm entropy của nhãn.
Chính thức:
\[\begin{eqnarray} T & = & \{ (x_i,y_i) | (x_i,y_i) \in D \ \textrm{with} \ x_i \ge t \} \\[12pt] F & = & \{ (x_i,y_i) | (x_i,y_i) \in D \ \textrm{with} \ x_i \lt t \} \\[12pt] R(X) & = & \frac{\lvert \{ x | x \in X \ \textrm{and} \ x = \mathrm{pos} \} \rvert}{\lvert X \rvert} \\[12pt] H(X) & = & - p \log p - (1 - p) \log (1-p) \ \textrm{with} \ p = R(X)\\[12pt] IG(D,T,F) & = & H(D) - \frac {\lvert T\rvert} {\lvert D \rvert } H(T) - \frac {\lvert F \rvert} {\lvert D \rvert } H(F) \end{eqnarray}\]
trong đó:
- $IG(D,T,F)$ là lợi ích thông tin của việc chia $D$ thành $T$ và $F$.
- $H(X)$ là entropy của tập hợp các ví dụ $X$.
- $|X|$ là số phần tử trong tập hợp $X$.
- $t$ là giá trị ngưỡng.
- $pos$ là giá trị nhãn dương, ví dụ: "xanh dương" trong ví dụ trên. Việc chọn một nhãn khác làm "nhãn dương" sẽ không làm thay đổi giá trị của entropy hoặc thông tin thu được.
- $R(X)$ là tỷ lệ giá trị nhãn dương trong các ví dụ $X$.
- $D$ là tập dữ liệu (như đã xác định trước đó trong bài này).
Trong ví dụ sau, chúng ta xem xét một tập dữ liệu phân loại nhị phân với một tính năng số duy nhất $x$. Hình sau đây cho thấy các giá trị ngưỡng $t$ khác nhau (trục x):
- Biểu đồ của đặc điểm $x$.
- Tỷ lệ ví dụ "xanh dương" trong tập hợp $D$, $T$ và $F$ theo giá trị ngưỡng.
- Entropy trong $D$, $T$ và $F$.
- Mức tăng thông tin; tức là delta entropy giữa $D$ và {$T$,$F$} được điều chỉnh theo số lượng ví dụ.
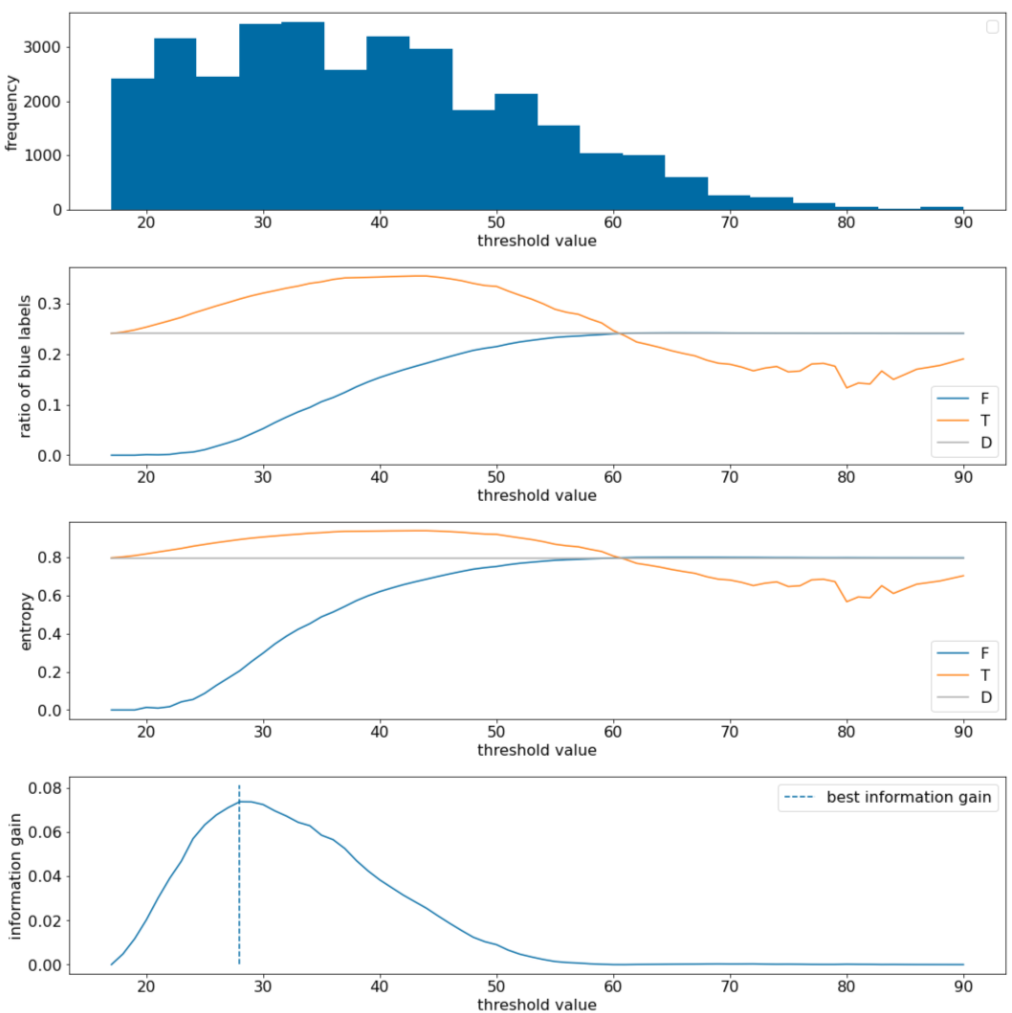
Hình 11. Bốn biểu đồ ngưỡng.
Các biểu đồ này cho thấy những thông tin sau:
- Biểu đồ "tần suất" cho thấy các quan sát được phân bố tương đối tốt với nồng độ từ 18 đến 60. Phạm vi giá trị rộng có nghĩa là có nhiều điểm phân tách tiềm năng, điều này rất tốt cho việc huấn luyện mô hình.
Tỷ lệ nhãn "xanh dương" trong tập dữ liệu là ~25%. Biểu đồ "tỷ lệ nhãn màu xanh dương" cho thấy rằng đối với các giá trị ngưỡng từ 20 đến 50:
- Tập hợp $T$ chứa nhiều ví dụ về nhãn "xanh dương" (lên đến 35% đối với ngưỡng 35).
- Tập hợp $F$ chứa một mức thiếu hụt bổ sung của các ví dụ về nhãn "xanh dương" (chỉ 8% đối với ngưỡng 35).
Cả biểu đồ "tỷ lệ nhãn màu xanh dương" và "entropy" đều cho thấy rằng các nhãn có thể được phân tách tương đối tốt trong phạm vi ngưỡng này.
Quan sát này được xác nhận trong biểu đồ "mức tăng thông tin". Chúng ta thấy rằng giá trị lợi tức thông tin tối đa được thu được với t~=28 cho giá trị lợi tức thông tin là ~0,074. Do đó, điều kiện do trình phân tách trả về sẽ là $x \geq 28$.
Mức tăng thông tin luôn dương hoặc rỗng. Giá trị này hội tụ về 0 khi giá trị ngưỡng hội tụ về giá trị tối đa / tối thiểu. Trong những trường hợp đó, $F$ hoặc $T$ sẽ trống trong khi dữ liệu còn lại chứa toàn bộ tập dữ liệu và cho thấy entropy bằng với entropy trong $D$. Mức tăng thông tin cũng có thể bằng 0 khi $H(T)$ = $H(F)$ = $H(D)$. Ở ngưỡng 60, tỷ lệ nhãn "xanh dương" cho cả $T$ và $F$ giống với tỷ lệ nhãn của $D$ và mức tăng thông tin bằng 0.
Các giá trị đề xuất cho $t$ trong tập hợp số thực ($\mathbb{R}$) là vô hạn. Tuy nhiên, với một số lượng hữu hạn ví dụ, chỉ có một số lượng hữu hạn phân chia $D$ thành $T$ và $F$. Do đó, chỉ có một số lượng giá trị hữu hạn của $t$ có ý nghĩa để kiểm thử.
Một phương pháp cổ điển là sắp xếp các giá trị xi theo thứ tự tăng dần xs(i) sao cho:
Sau đó, kiểm thử $t$ cho mọi giá trị ở giữa các giá trị được sắp xếp liên tiếp của $x_i$. Ví dụ: giả sử bạn có 1.000 giá trị dấu phẩy động của một đặc điểm cụ thể. Sau khi sắp xếp, giả sử hai giá trị đầu tiên là 8,5 và 8,7. Trong trường hợp này, giá trị ngưỡng đầu tiên cần kiểm thử sẽ là 8,6.
Về mặt hình thức, chúng ta xem xét các giá trị đề xuất sau đây cho t:
Độ phức tạp thời gian của thuật toán này là $\mathcal{O} ( n \log n) $ với $n$ là số lượng ví dụ trong nút (do việc sắp xếp các giá trị đặc điểm). Khi áp dụng trên cây quyết định, thuật toán trình phân tách sẽ được áp dụng cho từng nút và từng đặc điểm. Xin lưu ý rằng mỗi nút nhận được khoảng 1/2 ví dụ mẹ. Do đó, theo théo luận chính, độ phức tạp về thời gian của việc huấn luyện cây quyết định bằng bộ chia này là:
trong đó:
- $m$ là số lượng đặc điểm.
- $n$ là số lượng ví dụ huấn luyện.
Trong thuật toán này, giá trị của các đặc điểm không quan trọng; chỉ thứ tự mới quan trọng. Vì lý do này, thuật toán này hoạt động độc lập với quy mô hoặc mức phân phối của các giá trị đặc điểm. Đây là lý do chúng ta không cần chuẩn hoá hoặc điều chỉnh theo tỷ lệ các đặc điểm dạng số khi huấn luyện cây quyết định.