อัลกอริทึมการจัดประเภทข้อความเป็นหัวใจสําคัญของระบบซอฟต์แวร์ต่างๆ ที่ประมวลผลข้อมูลข้อความจํานวนมาก ซอฟต์แวร์อีเมลจะใช้การแยกประเภทข้อความเพื่อพิจารณาว่าอีเมลขาเข้าจะส่งไปยังกล่องจดหมายหรือกรองไปไว้ในโฟลเดอร์จดหมายขยะหรือไม่ ฟอรัมการสนทนาจะใช้การแยกประเภทข้อความเพื่อพิจารณาว่าควรแจ้งความคิดเห็นว่าไม่เหมาะสมหรือไม่
ต่อไปนี้เป็นตัวอย่างการจัดประเภทหัวข้อ 2 หัวข้อซึ่งจัดหมวดหมู่เอกสารข้อความให้เป็นชุดหัวข้อที่กําหนดไว้ล่วงหน้าชุดหนึ่ง ในปัญหาด้านการแยกหัวข้อหลายรายการ การจัดหมวดหมู่นี้ขึ้นอยู่กับคีย์เวิร์ดในข้อความเป็นหลัก
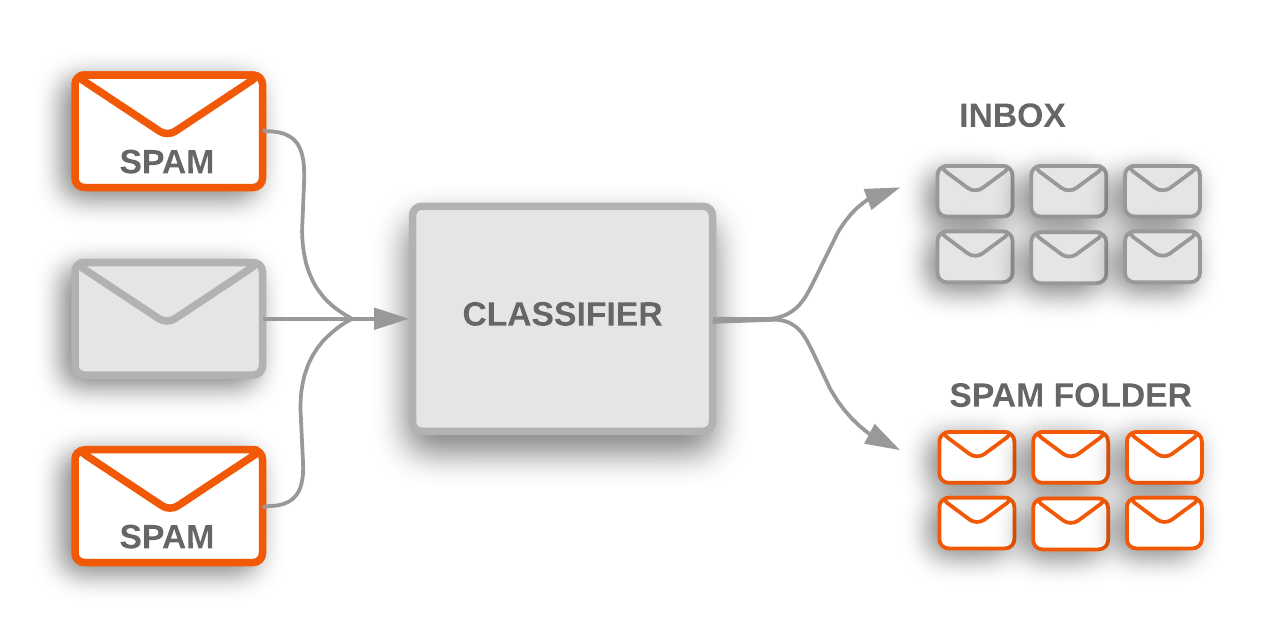
รูปที่ 1: การแยกประเภทหัวข้อใช้เพื่อทําเครื่องหมายอีเมลสแปมที่เข้ามาใหม่ และถูกกรองออกจากโฟลเดอร์จดหมายขยะ
การแยกประเภทข้อความที่พบบ่อยอีกประเภทหนึ่งคือการวิเคราะห์ความเห็น ซึ่งมีเป้าหมายที่จะเปลี่ยนขั้วของเนื้อหาข้อความ ซึ่งก็คือประเภทของความคิดเห็นที่แสดงออก โดยอาจอยู่ในรูปแบบไบนารีชอบ/ไม่ชอบ หรือชุดตัวเลือกเพิ่มเติม เช่น การให้ดาวตั้งแต่ 1 ถึง 5 ตัวอย่างของการวิเคราะห์ความเห็นรวมถึงการวิเคราะห์โพสต์ Twitter เพื่อพิจารณาว่าผู้คนชอบภาพยนตร์ของ Black Panther หรือไม่ หรือคาดคะเนความคิดเห็นของสาธารณชนทั่วไปเกี่ยวกับรองเท้า Nike แบรนด์ใหม่จากรีวิวใน Walmart
คู่มือนี้จะสอนแนวทางปฏิบัติแนะนําสําหรับแมชชีนเลิร์นนิงที่สําคัญสําหรับการแก้ปัญหาการจัดประเภทข้อความ สิ่งที่คุณจะได้เรียนรู้มีดังนี้
- เวิร์กโฟลว์ระดับสูงตั้งแต่ต้นจนจบสําหรับการแก้ปัญหาการจัดประเภทข้อความ โดยใช้แมชชีนเลิร์นนิง
- วิธีเลือกรูปแบบที่เหมาะสมกับปัญหาการจัดประเภทข้อความ
- วิธีใช้รูปแบบที่คุณเลือกโดยใช้ TensorFlow
เวิร์กโฟลว์การแยกประเภทข้อความ
ต่อไปนี้เป็นภาพรวมระดับสูงของเวิร์กโฟลว์ที่ใช้ในการแก้ปัญหาแมชชีนเลิร์นนิง
- ขั้นตอนที่ 1: รวบรวมข้อมูล
- ขั้นตอนที่ 2: สํารวจข้อมูลของคุณ
- ขั้นตอนที่ 2.5: เลือกรุ่น*
- ขั้นตอนที่ 3: เตรียมข้อมูล
- ขั้นตอนที่ 4: สร้าง ฝึก และประเมินโมเดล
- ขั้นตอนที่ 5: ปรับแต่งไฮเปอร์พารามิเตอร์
- ขั้นตอนที่ 6: ทําให้โมเดลใช้งานได้

รูปที่ 2: เวิร์กโฟลว์สําหรับการแก้ปัญหาแมชชีนเลิร์นนิง
ส่วนต่อไปนี้จะอธิบายแต่ละขั้นตอนโดยละเอียด และวิธีใช้งานขั้นตอนเหล่านี้สําหรับข้อความ