في هذه المرحلة، قمنا بتجميع مجموعة البيانات الخاصة بنا واكتسبنا رؤى حول الخصائص الرئيسية لبياناتنا. بعد ذلك، بناءً على المقاييس التي جمعناها في الخطوة 2، يجب أن نفكر في نموذج التصنيف الذي يجب أن نستخدمه. هذا يعني طرح أسئلة مثل:
- كيف تقدم البيانات النصية إلى خوارزمية تتوقع إدخال رقمي؟ (وهذا ما يسمى بالمعالجة المسبقة للبيانات والاتجاه العمودي).
- ما نوع النموذج الذي يجب أن تستخدمه؟
- ما هي مَعلمات الضبط التي يجب استخدامها للنموذج؟
بفضل عقود من البحث، تمكنا من الوصول إلى مجموعة كبيرة من خيارات المعالجة المسبقة للبيانات وإعداد النماذج. ومع ذلك، فإن توفر مجموعة كبيرة جدًا من الخيارات القابلة للتطبيق للاختيار من بينها يمكن أن يزيد بشكل كبير تعقيد ونطاق مشكلة معينة. وبالنظر إلى أن أفضل الخيارات قد لا تكون واضحة، فإن الحل البسيط هو تجربة كل خيار ممكن على نحو شامل، مع تقليص بعض الخيارات من خلال الحدس. ومع ذلك، سيكون ذلك مكلفًا للغاية.
نحاول في هذا الدليل تبسيط عملية اختيار نموذج تصنيف النص بشكل كبير. بالنسبة إلى أي مجموعة بيانات معينة، يتمثل هدفنا في إيجاد الخوارزمية التي تحقق أقصى دقة ممكنة مع تقليل وقت العمليات الحسابية اللازمة للتدريب. أجرينا عددًا كبيرًا (حوالي 450 ألف) من التجارب على مستوى مسائل من مختلف الأنواع (خاصة تحليل الآراء ومشاكل تصنيف المواضيع)، وباستخدام 12 مجموعة بيانات، بالتناوب مع كل مجموعة بيانات بين تقنيات المعالجة المسبقة للبيانات وبُنى نماذج مختلفة. ساعدنا هذا في تحديد معلمات مجموعة البيانات التي تؤثر على الخيارات المثلى.
تعد خوارزمية اختيار النموذج والمخطط الانسيابي أدناه ملخصًا لتجربتنا. لا تقلق إذا لم تفهم جميع المصطلحات المستخدمة فيها حتى الآن، فالأقسام التالية من هذا الدليل ستشرحها بالتفصيل.
خوارزمية إعداد البيانات وبناء النموذج
- احسب عدد العيّنات/عدد الكلمات لكل نسبة عيّنة.
- إذا كانت هذه النسبة أقل من 1, 500، يمكنك تحويل النص إلى رمز مميّز على أنّه
n-grams واستخدام نموذج بسيط متعدد الطبقات (MLP) لتصنيف النص (الفرع الأيسر في الرسم البياني الانسيابي أدناه):
- قسِّم العينات إلى كلمات ن جرام، ونحول ن جرام إلى متجهات.
- سجل أهمية المتجهات ثم حدد أعلى 20 ألفًا باستخدام الدرجات.
- إنشاء نموذج MLP:
- إذا كانت النسبة أكبر من 1500، يمكنك إنشاء رمز مميّز للنص على شكل تسلسلات واستخدام نموذج
sepCNN
لتصنيفها (الفرع الأيمن في الرسم البياني الانسيابي أدناه):
- قسِّم النماذج إلى كلمات، ثم اختَر أعلى 20 ألف كلمة حسب معدّل تكرارها.
- تحويل العينات إلى متجهات تسلسل الكلمات.
- إذا كان العدد الأصلي للعينات/عدد الكلمات لكل نسبة عينة أقل من 15 ألفًا، فإن استخدام تضمين مدرَّب مسبقًا مع نموذج sepCNN سيؤدي على الأرجح إلى تحقيق أفضل النتائج.
- قم بقياس أداء النموذج باستخدام قيم وفرص مختلفة لإيجاد أفضل إعداد نموذج لمجموعة البيانات.
في المخطط الانسيابي أدناه، تشير المربعات الصفراء إلى عمليات إعداد البيانات والنموذج. تشير المربعات الرمادية والمربعات الخضراء إلى الخيارات التي نأخذها في الاعتبار لكل عملية. تشير المربعات الخضراء إلى اختيارنا الموصى به لكل عملية.
يمكنك استخدام هذا المخطط الانسيابي كنقطة بداية لإنشاء تجربتك الأولى، حيث سيعطيك دقة جيدة بتكاليف حسابية منخفضة. يمكنك بعد ذلك الاستمرار في تحسين نموذجك الأولي عبر التكرارات اللاحقة.
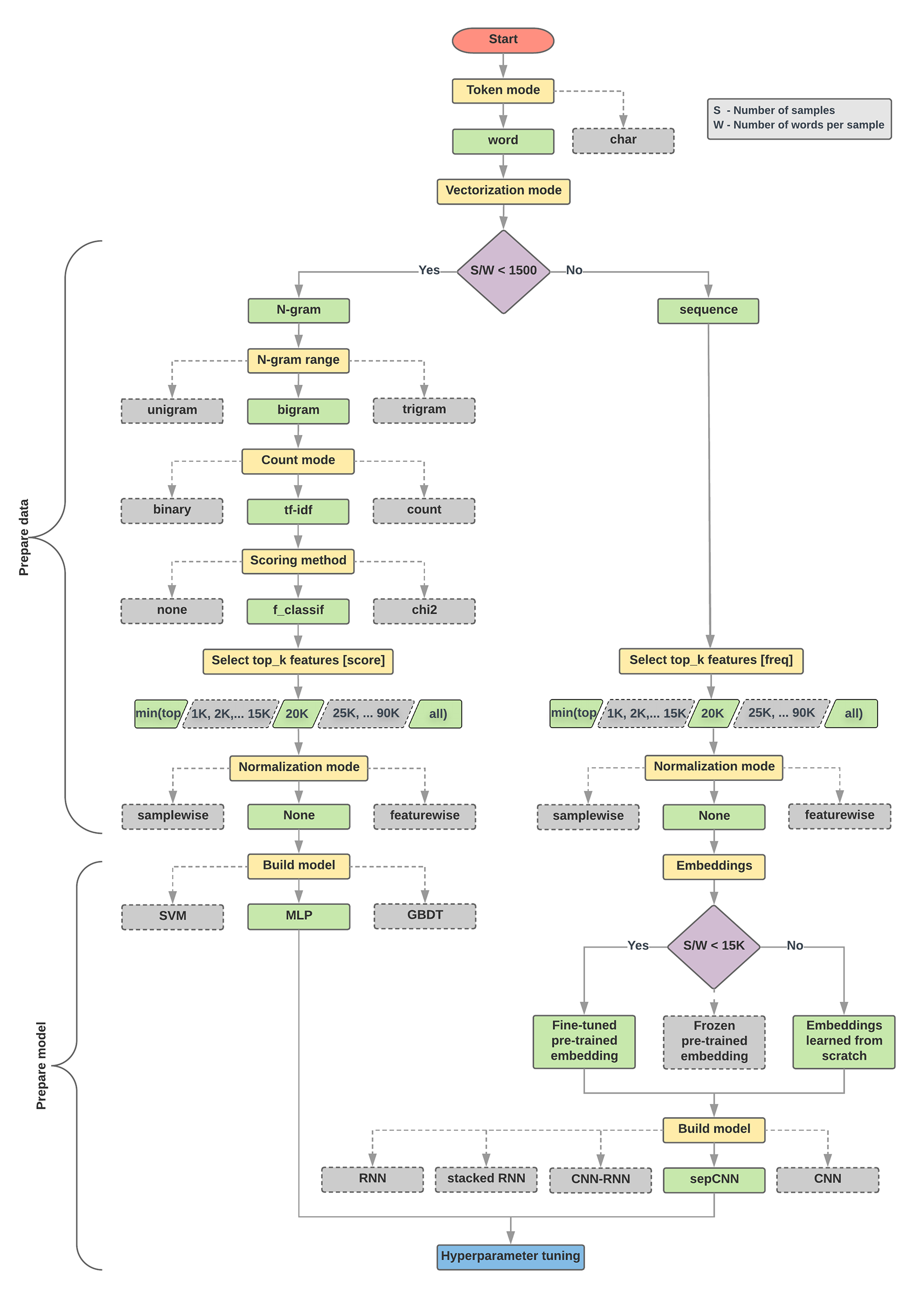
الشكل 5: رسم بياني انسيابي لتصنيف النص
يجيب هذا المخطط الانسيابي على سؤالين رئيسيين:
- ما هي خوارزمية أو نموذج التعلُّم الذي يجب أن تستخدمه؟
- كيف يجب عليك إعداد البيانات لمعرفة العلاقة بين النص والتسمية بكفاءة؟
تعتمد الإجابة عن السؤال الثاني على الإجابة عن السؤال الأول، وتعتمد الطريقة التي نتبعها في المعالجة المسبقة للبيانات لإدخالها في النموذج على النموذج الذي نختاره. يمكن تصنيف النماذج على نطاق واسع إلى فئتين: تلك التي تستخدم معلومات ترتيب الكلمات (نماذج التسلسلات)، وتلك التي ترى النص فقط على أنه "أكياس" (مجموعات) من الكلمات (نماذج الغرام). تتضمن أنواع نماذج التسلسل الشبكات العصبية الالتفافية (CNN) والشبكات العصبية المتكررة (RNN) وتبايناتها. تشمل أنواع نماذج الغرام ما يلي:
- الانحدار اللوجستي
- مكتشفات بسيطة متعددة الطبقات (MLP، أو الشبكات العصبونية المتصلة بالكامل)
- أشجار معزَّزة متدرجة
- آلات متجه الدعم
لاحظنا من تجاربنا أنّ نسبة "عدد العيّنات" إلى "عدد الكلمات في كل عيّنة" (W) ترتبط بالنموذج ذو الأداء الجيد.
عندما تكون قيمة هذه النسبة صغيرة (أقل من 1500)، يكون أداء المحالفات الصغيرة متعددة الطبقات التي تتعامل مع n غرام كمدخل (والذي سنطلق عليه الخيار A) أفضل أو على الأقل كأداء نماذج التسلسلات. من السهل تحديد وفهم MLP، وتستغرق وقتًا حاسوبيًا أقل بكثير من نماذج التسلسل. عندما تكون قيمة هذه النسبة كبيرة (>= 1500)، استخدِم نموذج تسلسل (الخيار ب). في الخطوات التالية، يمكنك التخطّي إلى الأقسام الفرعية ذات الصلة (المسماة أ أو ب) لنوع النموذج الذي اخترته بناءً على نسبة العينات/الكلمات لكل عيّنة.
في حالة مجموعة بيانات مراجعة IMDb، تكون نسبة العينات/الكلمات لكل عينة 144 تقريبًا. وهذا يعني أننا سننشئ نموذج MLP.