Prima di poter essere inviati a un modello, i dati devono essere trasformati in un formato il modello può comprendere.
Per prima cosa, i campioni di dati che abbiamo raccolto potrebbero trovarsi in un ordine specifico. Apprezziamo non vuoi che alcuna informazione associata all'ordine dei campioni influenzi la relazione tra testi ed etichette. Ad esempio, se un set di dati è ordinato per classe e poi suddivisi in insiemi di addestramento/convalida, rappresentativo della distribuzione complessiva dei dati.
Una semplice best practice per assicurarsi che il modello non sia interessato dall'ordine dei dati è esegui sempre lo shuffling dei dati prima di fare qualsiasi altra cosa. Se i tuoi dati sono già suddivisi in set di addestramento e convalida, assicurati di trasformare i valori nello stesso modo in cui li trasformi. Se non hai ancora set di addestramento e convalida separati, puoi suddividere i campioni shuffling; si utilizza l'80% dei campioni per l'addestramento e il 20% dei dati.
In secondo luogo, gli algoritmi di machine learning prendono i numeri come input. Ciò significa che dovrà convertire i testi in vettori numerici. Devi eseguire due passaggi questo processo:
Tokenizzazione: dividi i testi in parole o in sottotesti più piccoli, in modo da permettono una buona generalizzazione della relazione tra i testi e le etichette. Questo determina il "vocabolario" del set di dati (insieme di token univoci presenti in i dati).
Vettoretizzazione: definisci una buona misura numerica per caratterizzare questi elementi. SMS.
Vediamo come eseguire questi due passaggi sia per i vettori n-grammi sia per le sequenze vettori, nonché su come ottimizzare le rappresentazioni vettoriali utilizzando tecniche di selezione e normalizzazione.
Vettori di n-grammi [Opzione A]
Nei paragrafi successivi, vedremo come eseguire la tokenizzazione vettoriale per i modelli n-grammi. Vedremo anche come ottimizzare n- utilizzando tecniche di normalizzazione e selezione delle caratteristiche.
In un vettore di n-grammi, il testo è rappresentato come una raccolta di n-grammi unici:
gruppi di n token adiacenti (di solito, parole). Considera il testo The mouse ran
up the clock. Qui:
- La parola unigrammi (n = 1) sono
['the', 'mouse', 'ran', 'up', 'clock']. - La parola bigram (n = 2) è
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'] - e così via.
Tokenizzazione
Abbiamo scoperto che la tokenizzazione in unigrammi + bigram fornisce una buona con tempi di calcolo inferiori.
Vettorizzazione
Una volta suddivisi i nostri campioni di testo in n-grammi, dobbiamo trasformare questi n-grammi in vettori numerici che i nostri modelli di machine learning sono in grado di elaborare. L'esempio sotto sono riportati gli indici assegnati agli unigrammi e ai bigram generati per due SMS.
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
Una volta assegnati gli indici agli n-grammi, tipicamente vettorializziamo utilizzando uno di le seguenti opzioni.
Codifica one-hot: ogni testo di esempio è rappresentato come un vettore che indica la presenza o l'assenza di un token nel testo.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
Conteggio codifica: ogni testo di esempio è rappresentato come un vettore che indica la
di un token nel testo. Nota che l'elemento corrispondente
unigram "the" è ora rappresentato come 2 perché la parola "il"
appare due volte nel testo.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
Codifica Tf-idf: il problema con i due approcci precedenti è che le parole comuni che si ripetono in frequenza in tutti i documenti (ovvero parole che non sono particolarmente specifiche esempi di testo nel set di dati) non vengono penalizzati. Ad esempio, parole come "a" riporteranno molto spesso in tutti i testi. Quindi un conteggio dei token più alto per "the" per altre parole più significative non è molto utile.
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
(vedi TfidfTransformer di Scikit-learn)
Esistono molte altre rappresentazioni vettoriali, ma le tre precedenti sono più comunemente utilizzate.
Abbiamo osservato che la codifica tf-idf è leggermente migliore delle altre due in termini di accuratezza (in media: 0,25-15% in più) e consigliamo di utilizzare questo metodo per vettorializzare gli n-grammi. Tuttavia, tieni presente che occupa più memoria (come utilizza la rappresentazione in virgola mobile) e richiede più tempo per il calcolo, soprattutto per set di dati di grandi dimensioni (in alcuni casi può richiedere il doppio del tempo).
Selezione delle caratteristiche
Quando convertiamo tutti i testi di un set di dati in token uni+bigrammi di parole, può terminare con decine di migliaia di token. Non tutti questi token/funzionalità contribuiscono alla previsione delle etichette. Possiamo rilasciare determinati token, ad esempio che si verificano in modo estremamente raro nel set di dati. Possiamo anche misurare l'importanza delle caratteristiche (in che misura ogni token contribuisce alle previsioni delle etichette) che includano solo i token più informativi.
Esistono molte funzioni statistiche che prendono le caratteristiche e i le etichette e restituisce il punteggio di importanza delle caratteristiche. Due funzioni di uso comune sono f_classif e chi2. Le nostre gli esperimenti dimostrano che entrambe le funzioni hanno lo stesso rendimento.
Ma soprattutto, abbiamo visto che la precisione raggiunge il picco di circa 20.000 caratteristiche per molti (vedi Figura 6). L'aggiunta di altre caratteristiche oltre questa soglia contribuisce molto poco e a volte porta persino a overfitting e ne peggiora le prestazioni.

Figura 6: confronto tra funzionalità Top-K e accuratezza. Nei set di dati, si registrano altissimi livelli di accuratezza intorno alle 20.000 caratteristiche principali.
Normalizzazione
La normalizzazione converte tutti i valori delle caratteristiche/dei campioni in valori piccoli e simili. Ciò semplifica la convergenza della discesa del gradiente negli algoritmi di apprendimento. Da cosa che abbiamo visto, la normalizzazione durante la pre-elaborazione dei dati non sembra aggiungere il valore nei problemi di classificazione del testo; consigliamo di saltare questo passaggio.
Il seguente codice include tutti i passaggi precedenti:
- tokenizza campioni di testo in uni+bigrammi di parole,
- Vettorizza utilizzando la codifica tf-idf,
- Seleziona solo le 20.000 caratteristiche principali dal vettore di token scartando di token che appaiono meno di 2 volte e che utilizza f_classif per calcolare la caratteristica l'importanza.
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
Con la rappresentazione vettoriale n-grammi, scartiamo molte informazioni sulla ordine e grammatica (nella migliore delle ipotesi, possiamo mantenere alcune informazioni parziali quando n > 1) Questo approccio è chiamato "bag-of-words". Questa rappresentazione viene utilizzata in combinazione con modelli che non tengono conto dell'ordinamento, come regressione logistica, percetroni multilivello, macchine per l'aumento del gradiente il supporto di macchine vettoriali.
Vettori di sequenza [Opzione B]
Nei paragrafi successivi, vedremo come eseguire la tokenizzazione vettoriale per i modelli di sequenza. Vedremo anche come ottimizzare rappresentazione in sequenza usando tecniche di selezione e normalizzazione delle caratteristiche.
Per alcuni esempi di testo, l'ordine delle parole è fondamentale per il significato del testo. Per ad esempio: "Odiavo il mio tragitto giornaliero. La mia nuova bici ha cambiato la situazione completamente" possono essere comprese solo quando vengono lette in ordine. Modelli come CNN/RNN può dedurre il significato dall'ordine delle parole in un campione. Per questi modelli, rappresentare il testo come una sequenza di token, mantenendo l'ordine.
Tokenizzazione
Il testo può essere rappresentato come una sequenza di caratteri o una sequenza di parole. Abbiamo scoperto che l'utilizzo della rappresentazione a livello di parola offre rispetto ai token carattere. Questa è anche la norma generale seguito dal settore. L'utilizzo di token di carattere ha senso solo se i testi hanno molti di errori di battitura, cosa che normalmente non accade.
Vettoriazione
Una volta convertiti i nostri campioni di testo in sequenze di parole, dobbiamo trasformare queste sequenze in vettori numerici. L'esempio seguente mostra gli indici agli unigrammi generati per due testi, quindi la sequenza indici in cui viene convertito il primo testo.
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
Indice assegnato a ogni token:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
NOTA: la parola "the" si verifica più frequentemente, quindi il valore di indice 1 è assegnate a quest'ultimo. Alcune librerie prenotano l'indice 0 per i token sconosciuti, così come questo caso.
Sequenza degli indici di token:
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
Sono disponibili due opzioni per vettorializzare le sequenze di token:
Codifica one-hot: le sequenze sono rappresentate utilizzando vettori di parole in n- spazio dimensionale in cui n = dimensione del vocabolario. Questa rappresentazione funziona benissimo quando tokenizzando come caratteri e il vocabolario è quindi piccolo. Quando si tokenizza come parole, il vocabolario di solito ha decine migliaia di token, rendendo i vettori one-hot molto sparsi e inefficienti. Esempio:
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
Incorporamenti di parole: alle parole sono associati significati. Di conseguenza, può rappresentare token di parole in uno spazio vettoriale denso (~qualche centinaio di numeri reali), dove la posizione e la distanza tra le parole indica il loro grado di somiglianza semanticamente (vedi la Figura 7). Questa rappresentazione prende il nome incorporamenti di parole.
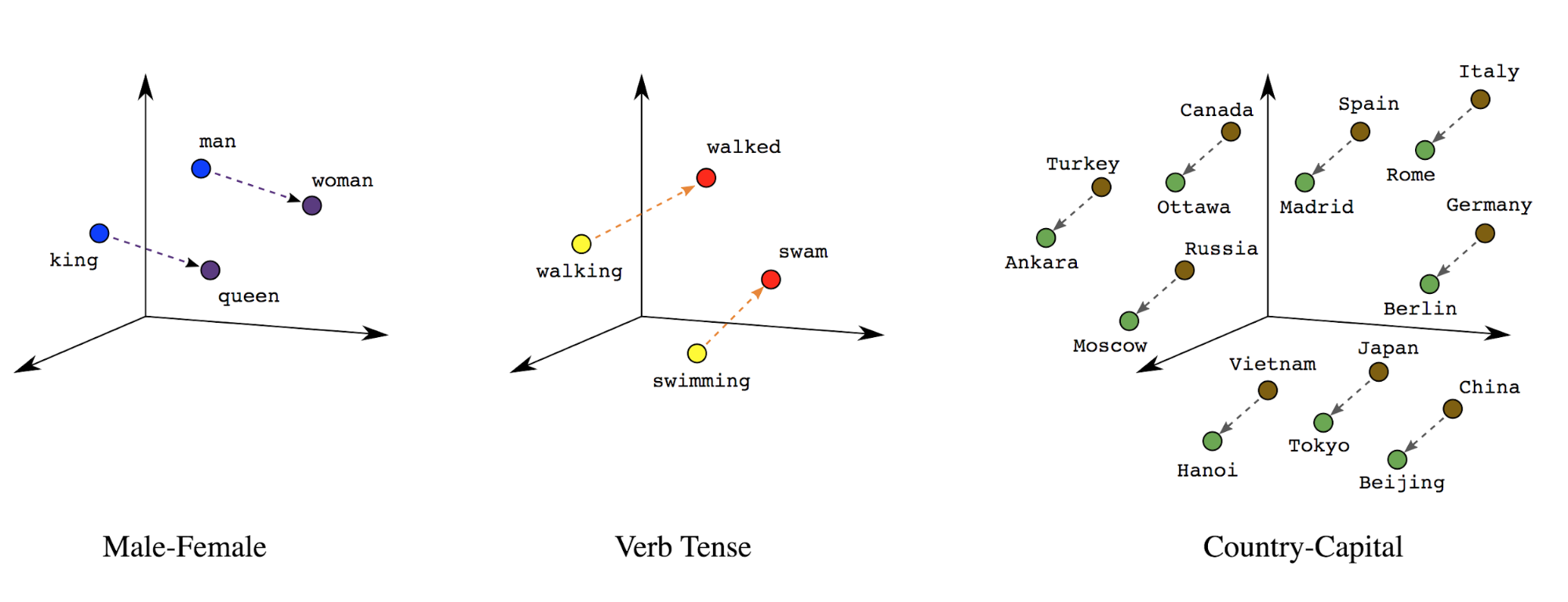
Figura 7: incorporamenti di parole
I modelli di sequenza spesso hanno uno strato di incorporamento come primo strato. Questo strato impara a trasformare le sequenze di indici di parole in vettori di incorporamento di parole durante di addestramento, in modo che ogni indice parola venga mappato su un vettore denso valori reali che rappresentano la posizione di quella parola nello spazio semantico (vedi Figura 8).
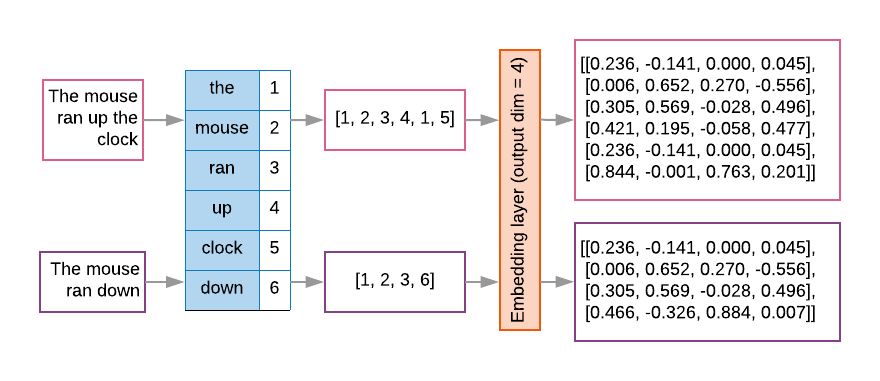
Figura 8: strato di incorporamento
Selezione delle caratteristiche
Non tutte le parole nei nostri dati contribuiscono alle previsioni delle etichette. Possiamo ottimizzare i nostri processo di apprendimento, eliminando le parole rare o irrilevanti dal nostro vocabolario. Nella osserviamo infatti che l'utilizzo delle 20.000 caratteristiche più frequenti è generalmente sufficienti. Questo vale anche per i modelli n-grammi (vedi Figura 6).
Mettiamo insieme tutti i passaggi precedenti nella vettore di sequenza. La seguente codice esegue queste attività:
- Tokenizza i testi in parole
- Crea un vocabolario utilizzando i primi 20.000 token
- Converte i token in vettori di sequenza
- Applica un pad alle sequenze fino a una lunghezza fissa
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
Vettoriazione delle etichette
Abbiamo visto come convertire dati di testo di esempio in vettori numerici. Una procedura simile
devono essere applicate alle etichette. Possiamo semplicemente convertire le etichette in valori compresi nell'intervallo
[0, num_classes - 1]. Ad esempio, se ci sono 3 classi, possiamo usare
0, 1 e 2 per rappresentarli. Internamente, la rete utilizzerà one-hot
per rappresentare questi valori (per evitare di dedurre una relazione errata
tra le etichette). Questa rappresentazione dipende dalla funzione di perdita e dall'ultimo parametro
funzione di attivazione degli strati che usiamo nella nostra rete neurale. Scopriremo di più
e li vedrai nella prossima sezione.