In questa sezione ci occuperemo dello sviluppo, della formazione e della valutazione
un modello di machine learning. Nel Passaggio 3,
abbiamo scelto di utilizzare un modello n-grammi o un modello di sequenza, utilizzando il rapporto S/W.
A questo punto occorre scrivere il nostro algoritmo di classificazione e addestrarlo. Utilizzeremo
TensorFlow con
tf.keras
API per questo comando.
La creazione di modelli di machine learning con Keras consiste nell'assemblare a strati, componenti di base per l'elaborazione dei dati, un po' come assemblare i Lego mattoncini. Questi strati ci consentono di specificare la sequenza di trasformazioni che vogliamo da eseguire in base al nostro input. Poiché il nostro algoritmo di apprendimento acquisisce un singolo input di testo, e genera una singola classificazione, possiamo creare una pila lineare di strati utilizzando Modello sequenziale tramite Google Cloud CLI o tramite l'API Compute Engine.
Figura 9: pila lineare di strati
Lo strato di input e quello intermedio saranno realizzati in modo diverso, a seconda che stiamo creando un modello n-gram o un modello di sequenza. Ma indipendentemente dal tipo di modello, l'ultimo strato sarà lo stesso per un determinato problema.
Costruzione dell'ultimo strato
Quando abbiamo solo due classi (classificazione binaria), il modello dovrebbe restituire una
singolo punteggio di probabilità. Ad esempio, restituisce 0.2 per un determinato campione di input
significa "il 20% di fiducia che questo campione sia nella prima classe (classe 1), l'80%
è della seconda classe (classe 0)." Per restituire questo punteggio di probabilità,
funzione di attivazione
dell'ultimo strato dovrebbe essere
funzione sigmoidea,
e ai
funzione di perdita
usati per addestrare il modello,
entropia incrociata binaria.
(vedi la Figura 10, a sinistra).
Se ci sono più di due classi (classificazione multiclasse), il nostro modello
dovrebbe restituire un punteggio di probabilità per classe. La somma di questi punteggi deve essere
1. Ad esempio, l'output {0: 0.2, 1: 0.7, 2: 0.1} significa "20% di confidenza che
questo campione è nella classe 0, il 70% è nella classe 1 e il 10% è nella
classe 2." Per restituire questi punteggi, la funzione di attivazione dell'ultimo strato
deve essere softmax e la funzione di perdita usata per addestrare il modello
l'entropia incrociata categorica. (vedi la Figura 10, a destra).
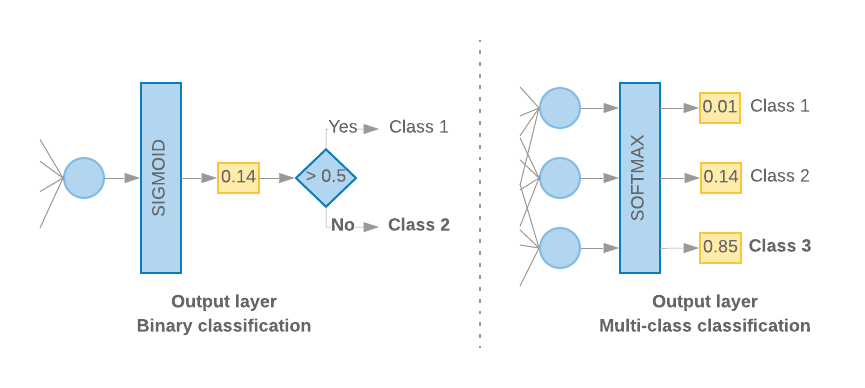
Figura 10: ultimo livello
Il seguente codice definisce una funzione che prende il numero di classi come input, e restituisce il numero appropriato di unità di livello (1 unità per i per la classificazione; altrimenti 1 unità per ogni corso) e l'attivazione appropriata :
def _get_last_layer_units_and_activation(num_classes):
"""Gets the # units and activation function for the last network layer.
# Arguments
num_classes: int, number of classes.
# Returns
units, activation values.
"""
if num_classes == 2:
activation = 'sigmoid'
units = 1
else:
activation = 'softmax'
units = num_classes
return units, activation
Le due sezioni seguenti illustrano la creazione del modello rimanente. per i modelli n-gram e per i modelli di sequenza.
Quando il rapporto S/W è ridotto, abbiamo riscontrato che i modelli con n-grammi hanno un rendimento migliore
rispetto ai modelli di sequenza. I modelli di sequenza sono migliori quando sono presenti
di vettori piccoli e densi. Questo perché le relazioni di incorporamento vengono apprese
spazio denso e questo avviene meglio con molti campioni.
Crea un modello n-gram [Opzione A]
Ci riferiamo a modelli che elaborano i token in modo indipendente (senza prendere account delle parole) come modelli n-grammi. Percetroni a più strati semplici (tra cui regressione logistica macchine per il gradient boosting, e supportano i modelli di macchine vettoriali) rientrano tutti in questa categoria: non possono usare alcuna informazione l'ordinamento del testo.
Abbiamo confrontato le prestazioni di alcuni dei modelli n-grammi menzionati sopra e osservato che i perceptroni multi-strato (MLP) in genere hanno un rendimento migliore rispetto altre opzioni. Gli MLP sono semplici da definire e comprendere, offreno una buona accuratezza, e richiedono un calcolo relativamente ridotto.
Il codice seguente definisce un modello MLP a due livelli in tf.keras, aggiungendo un paio di Livelli di abbandono per la regolarizzazione per evitare overfitting ai campioni di addestramento.
from tensorflow.python.keras import models
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import Dropout
def mlp_model(layers, units, dropout_rate, input_shape, num_classes):
"""Creates an instance of a multi-layer perceptron model.
# Arguments
layers: int, number of `Dense` layers in the model.
units: int, output dimension of the layers.
dropout_rate: float, percentage of input to drop at Dropout layers.
input_shape: tuple, shape of input to the model.
num_classes: int, number of output classes.
# Returns
An MLP model instance.
"""
op_units, op_activation = _get_last_layer_units_and_activation(num_classes)
model = models.Sequential()
model.add(Dropout(rate=dropout_rate, input_shape=input_shape))
for _ in range(layers-1):
model.add(Dense(units=units, activation='relu'))
model.add(Dropout(rate=dropout_rate))
model.add(Dense(units=op_units, activation=op_activation))
return model
Crea un modello sequenza [Opzione B]
Ci riferiamo a modelli che possono apprendere dall'adiacenza dei token come sequenza di grandi dimensioni. Sono incluse le classi dei modelli CNN e RNN. I dati vengono pre-elaborati come di sequenza per questi modelli.
I modelli sequenza in genere hanno un numero maggiore di parametri da apprendere. Il primo in questi modelli è uno strato di incorporamento, che apprende la relazione tra le parole in uno spazio vettoriale denso. Imparare le relazioni con le parole funziona migliore rispetto a molti campioni.
Molto probabilmente le parole in un determinato set di dati non sono univoche per quel set di dati. Possiamo quindi Apprendere la relazione tra le parole nel nostro set di dati utilizzando altri set di dati. Per farlo, possiamo trasferire un incorporamento appreso da un altro set di dati nel nostro di incorporamento. Questi incorporamenti sono detti preaddestrati rappresentazioni distribuite. L'utilizzo di un incorporamento preaddestrato offre al modello un vantaggio che aiutano a guidare il processo di apprendimento.
Sono disponibili incorporamenti preaddestrati che sono stati addestrati utilizzando come GloVe. GloVe ha addestrato su più corpora (principalmente Wikipedia). Abbiamo testato l'addestramento usando una versione degli incorporamenti GloVe e abbiamo osservato che, ha bloccato i pesi degli incorporamenti preaddestrati e ha addestrato solo il resto i modelli non hanno avuto un buon rendimento. Ciò potrebbe essere dovuto al fatto che il contesto che lo strato di incorporamento è stato addestrato potrebbe essere stato diverso dal contesto in cui la stavamo utilizzando.
Gli incorporamenti GloVe addestrati sui dati di Wikipedia potrebbero non allinearsi con la lingua pattern nel nostro set di dati IMDb. Le relazioni dedotte possono richiedere In fase di aggiornamento, ovvero i pesi di incorporamento potrebbero richiedere un'ottimizzazione contestuale. Lo facciamo in in due fasi:
Nella prima esecuzione, con i pesi degli strati di incorporamento bloccati, consentiamo agli altri della rete per imparare. Al termine di questa esecuzione, i pesi del modello raggiungono uno stato molto meglio dei loro valori non inizializzati. Per la seconda esecuzione, consente anche allo strato di incorporamento di apprendere, apportando regolazioni precise a tutte le ponderazioni nella rete. Questo processo viene definito come un incorporamento perfezionato.
Gli incorporamenti ottimizzati offrono una maggiore accuratezza. Tuttavia, questo si verifica spesa dell'aumento della potenza di calcolo necessaria per addestrare la rete. Data un un numero sufficiente di campioni, potremmo fare altrettanto imparare un incorporamento partendo da zero. Abbiamo osservato che, per
S/W > 15K, partire da zero in modo efficace produce all'incirca la stessa accuratezza dell'utilizzo dell'incorporamento perfezionato.
Abbiamo confrontato diversi modelli di sequenza come CNN, sepCNN, RNN (LSTM e GRU), CNN-RNN e RNN impilato, delle architetture dei modelli. Abbiamo scoperto che le sepCNN, una variante di rete convoluzionale spesso è più efficiente nei dati e nel calcolo, ha prestazioni migliori e altri modelli.
Il codice seguente genera un modello sepCNN a quattro livelli:
from tensorflow.python.keras import models from tensorflow.python.keras import initializers from tensorflow.python.keras import regularizers from tensorflow.python.keras.layers import Dense from tensorflow.python.keras.layers import Dropout from tensorflow.python.keras.layers import Embedding from tensorflow.python.keras.layers import SeparableConv1D from tensorflow.python.keras.layers import MaxPooling1D from tensorflow.python.keras.layers import GlobalAveragePooling1D def sepcnn_model(blocks, filters, kernel_size, embedding_dim, dropout_rate, pool_size, input_shape, num_classes, num_features, use_pretrained_embedding=False, is_embedding_trainable=False, embedding_matrix=None): """Creates an instance of a separable CNN model. # Arguments blocks: int, number of pairs of sepCNN and pooling blocks in the model. filters: int, output dimension of the layers. kernel_size: int, length of the convolution window. embedding_dim: int, dimension of the embedding vectors. dropout_rate: float, percentage of input to drop at Dropout layers. pool_size: int, factor by which to downscale input at MaxPooling layer. input_shape: tuple, shape of input to the model. num_classes: int, number of output classes. num_features: int, number of words (embedding input dimension). use_pretrained_embedding: bool, true if pre-trained embedding is on. is_embedding_trainable: bool, true if embedding layer is trainable. embedding_matrix: dict, dictionary with embedding coefficients. # Returns A sepCNN model instance. """ op_units, op_activation = _get_last_layer_units_and_activation(num_classes) model = models.Sequential() # Add embedding layer. If pre-trained embedding is used add weights to the # embeddings layer and set trainable to input is_embedding_trainable flag. if use_pretrained_embedding: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0], weights=[embedding_matrix], trainable=is_embedding_trainable)) else: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0])) for _ in range(blocks-1): model.add(Dropout(rate=dropout_rate)) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(MaxPooling1D(pool_size=pool_size)) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(GlobalAveragePooling1D()) model.add(Dropout(rate=dropout_rate)) model.add(Dense(op_units, activation=op_activation)) return model
Addestra il modello
Ora che abbiamo creato l'architettura del modello, dobbiamo addestrare il modello. L'addestramento prevede la previsione basata sullo stato attuale del modello, calcolare l'errata previsione e aggiornare le ponderazioni parametri della rete per ridurre al minimo questo errore e fare in modo che il modello meglio. Il processo viene ripetuto finché il modello non è convergente e non può più imparano. È possibile scegliere tre parametri chiave per questo processo (vedi Tabella 2.
- Metrica: come misurare le prestazioni del modello utilizzando una metrica. Abbiamo usato l'accuratezza come metrica nei nostri esperimenti.
- Funzione di perdita: una funzione utilizzata per calcolare un valore di perdita. che il processo di addestramento tenta di minimizzare ottimizzando delle ponderazioni di rete. Per i problemi di classificazione, la perdita di entropia incrociata funziona bene.
- Ottimizzatore: una funzione che stabilisce come saranno le ponderazioni della rete. viene aggiornato in base all'output della funzione loss. Abbiamo usato il popolare ottimizzatore Adam nei nostri esperimenti.
In Keras, possiamo passare questi parametri di apprendimento a un modello utilizzando compilare .
Tabella 2: Parametri di apprendimento
| Parametro di apprendimento | Valore |
|---|---|
| Metrica | accuracy |
| Funzione di perdita: classificazione binaria | binary_crossentropy |
| Funzione di perdita: classificazione multiclasse | sparse_categorical_crossentropy |
| Ottimizzatore | Adamo |
L'addestramento reale avviene utilizzando
fit.
In base alle dimensioni del
questo è il metodo in cui verrà spesa la maggior parte dei cicli di calcolo. In ogni
iterazione di addestramento, batch_size numero di campioni dai tuoi dati di addestramento
utilizzata per calcolare la perdita e le ponderazioni vengono aggiornate una volta in base a questo valore.
Il processo di addestramento completa un epoch una volta che il modello ha esaminato l'intero
set di dati di addestramento. Alla fine di ogni epoca, utilizziamo il set di dati di convalida
valutare il livello di apprendimento del modello. Ripetiamo l'addestramento usando il set di dati
per un numero prestabilito di epoche. Potremmo ottimizzare l'aggiornamento fermandosi in anticipo,
quando l'accuratezza della convalida si stabilizza tra epoche consecutive, dimostrando che
non è più in corso l'addestramento del modello.
| Iperparametro di addestramento | Valore |
|---|---|
| Tasso di apprendimento | 1e-3 |
| Epoche | 1000 |
| Dimensione del batch | 512 |
| Interruzione anticipata | parametro: val_loss, pazienza: 1 |
Tabella 3: iperparametri di addestramento
Il seguente codice Keras implementa il processo di addestramento utilizzando i parametri scelte nelle tabelle 2 e 3 sopra:
def train_ngram_model(data, learning_rate=1e-3, epochs=1000, batch_size=128, layers=2, units=64, dropout_rate=0.2): """Trains n-gram model on the given dataset. # Arguments data: tuples of training and test texts and labels. learning_rate: float, learning rate for training model. epochs: int, number of epochs. batch_size: int, number of samples per batch. layers: int, number of `Dense` layers in the model. units: int, output dimension of Dense layers in the model. dropout_rate: float: percentage of input to drop at Dropout layers. # Raises ValueError: If validation data has label values which were not seen in the training data. """ # Get the data. (train_texts, train_labels), (val_texts, val_labels) = data # Verify that validation labels are in the same range as training labels. num_classes = explore_data.get_num_classes(train_labels) unexpected_labels = [v for v in val_labels if v not in range(num_classes)] if len(unexpected_labels): raise ValueError('Unexpected label values found in the validation set:' ' {unexpected_labels}. Please make sure that the ' 'labels in the validation set are in the same range ' 'as training labels.'.format( unexpected_labels=unexpected_labels)) # Vectorize texts. x_train, x_val = vectorize_data.ngram_vectorize( train_texts, train_labels, val_texts) # Create model instance. model = build_model.mlp_model(layers=layers, units=units, dropout_rate=dropout_rate, input_shape=x_train.shape[1:], num_classes=num_classes) # Compile model with learning parameters. if num_classes == 2: loss = 'binary_crossentropy' else: loss = 'sparse_categorical_crossentropy' optimizer = tf.keras.optimizers.Adam(lr=learning_rate) model.compile(optimizer=optimizer, loss=loss, metrics=['acc']) # Create callback for early stopping on validation loss. If the loss does # not decrease in two consecutive tries, stop training. callbacks = [tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=2)] # Train and validate model. history = model.fit( x_train, train_labels, epochs=epochs, callbacks=callbacks, validation_data=(x_val, val_labels), verbose=2, # Logs once per epoch. batch_size=batch_size) # Print results. history = history.history print('Validation accuracy: {acc}, loss: {loss}'.format( acc=history['val_acc'][-1], loss=history['val_loss'][-1])) # Save model. model.save('IMDb_mlp_model.h5') return history['val_acc'][-1], history['val_loss'][-1]
Puoi trovare esempi di codice per l'addestramento del modello di sequenza qui.