Os algoritmos de classificação de texto são essenciais em vários sistemas de software que processam dados de texto em escala. O software de e-mail usa a classificação de texto para determinar se os e-mails recebidos são enviados para a Caixa de entrada ou filtrados na pasta de spam. Os fóruns de discussão usam a classificação de texto para determinar se os comentários devem ser sinalizados como inadequados.
Veja dois exemplos de classificação de tópicos, categorizando um documento de texto em um de um conjunto predefinido de temas. Em muitos problemas de classificação de tópicos, essa categorização é baseada principalmente em palavras-chave no texto.
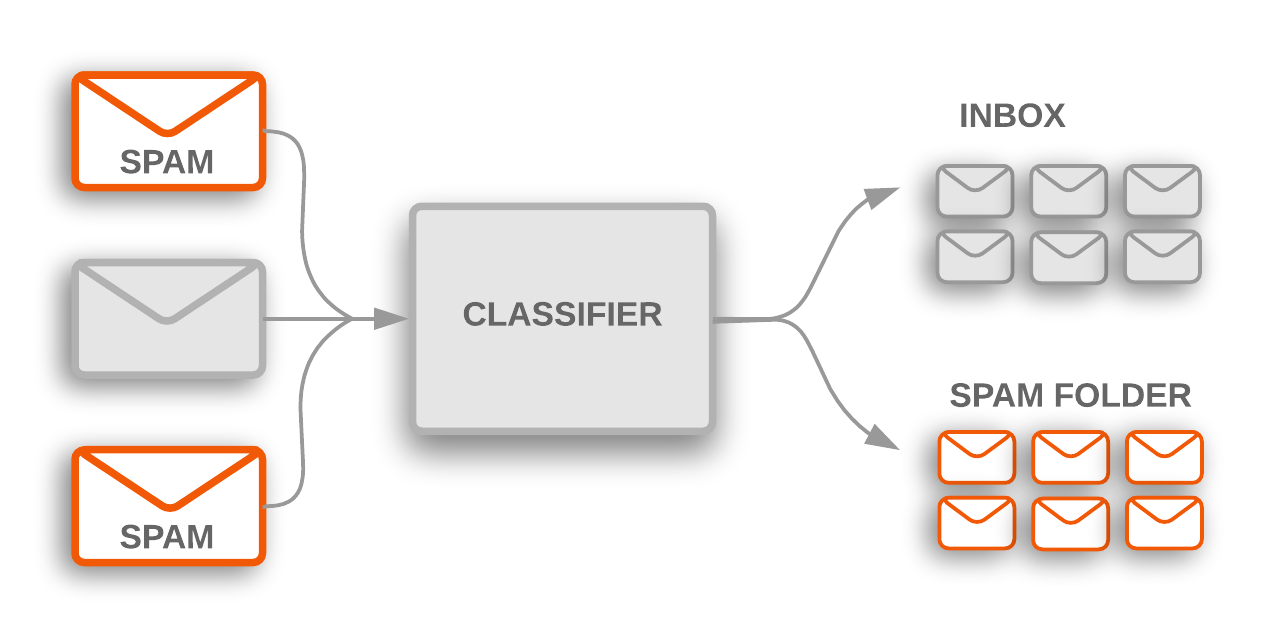
Figura 1: a classificação de tópicos é usada para sinalizar e-mails de spam recebidos, que são filtrados em uma pasta de spam.
Outro tipo comum de classificação de texto é a análise de sentimento. O objetivo é identificar a polaridade do conteúdo de texto: o tipo de opinião que ele expressa. Isso pode assumir a forma de uma classificação binária de "Gostei"/"Não gostei" ou um conjunto de opções mais granular, como uma nota de 1 a 5. Exemplos de análise de sentimento incluem a análise de postagens do Twitter para determinar se as pessoas gostaram do filme da Pantera Negra ou extrapolar a opinião do público em geral sobre uma nova marca de calçados Nike nas avaliações do Walmart.
Veja neste guia algumas práticas recomendadas para o aprendizado de máquina importantes para resolver problemas de classificação de texto. Dessa forma, você será capaz de:
- O fluxo de trabalho completo de alto nível para resolver problemas de classificação de texto usando machine learning
- Como escolher o modelo certo para seu problema de classificação de texto
- Como implementar o modelo escolhido usando o TensorFlow.
Fluxo de trabalho de classificação de texto
Confira uma visão geral de alto nível do fluxo de trabalho usado para resolver problemas de machine learning:
- Etapa 1: coletar dados
- Etapa 2: analise seus dados
- Etapa 2.5: escolher um modelo*
- Etapa 3: preparar os dados
- Etapa 4: criar, treinar e avaliar o modelo
- Etapa 5: ajuste os hiperparâmetros
- Etapa 6: implantar o modelo

Figura 2: fluxo de trabalho para resolver problemas de machine learning
As seções a seguir explicam cada etapa em detalhes e como implementá-las em dados de texto.