Ziel
Im Tutorial zur Adressvalidierung mit hohem Volumen wurden verschiedene Szenarien beschrieben, in denen die Adressvalidierung mit hohem Volumen verwendet werden kann. In dieser Anleitung stellen wir Ihnen verschiedene Designmuster in der Google Cloud Platform für die Ausführung der Adressvalidierung mit hohem Volumen vor.
Wir beginnen mit einem Überblick über die Ausführung der Adressvalidierung mit hohem Volumen in der Google Cloud Platform mit Cloud Run, Compute Engine oder Google Kubernetes Engine für einmalige Ausführungen. Anschließend sehen wir uns an, wie diese Funktion in eine Datenpipeline eingebunden werden kann.
Am Ende dieses Artikels sollten Sie die verschiedenen Optionen zum Ausführen der Adressvalidierung in großen Mengen in Ihrer Google Cloud-Umgebung gut kennen.
Referenzarchitektur in der Google Cloud Platform
In diesem Abschnitt werden verschiedene Designmuster für die Adressvalidierung mit hohem Volumen mithilfe der Google Cloud Platform näher erläutert. Da die Lösung auf der Google Cloud Platform ausgeführt wird, können Sie sie in Ihre bestehenden Prozesse und Datenpipelines einbinden.
Einmalige Ausführung der Adressüberprüfung mit hohem Volumen auf der Google Cloud Platform
Nachfolgend ist eine Referenzarchitektur dargestellt, die zeigt, wie eine Integration auf der Google Cloud Platform erstellt werden kann und die sich besser für einmalige Operationen oder Tests eignet.

In diesem Fall empfehlen wir, die CSV-Datei in einen Cloud Storage-Bucket hochzuladen. Das Script für die Adressvalidierung mit hohem Volumen kann dann in einer Cloud Run-Umgebung ausgeführt werden. Sie können sie jedoch in jeder anderen Laufzeitumgebung wie Compute Engine oder Google Kubernetes Engine ausführen. Die CSV-Ausgabedatei kann auch in den Cloud Storage-Bucket hochgeladen werden.
Als Google Cloud-Datenpipeline ausführen
Das im vorherigen Abschnitt gezeigte Bereitstellungsmuster eignet sich hervorragend, um die High Volume Address Validation für die einmalige Verwendung schnell zu testen. Wenn Sie es jedoch regelmäßig als Teil einer Datenpipeline verwenden müssen, können Sie die nativen Funktionen der Google Cloud Platform besser nutzen, um es robuster zu machen. Sie können unter anderem folgende Änderungen vornehmen:
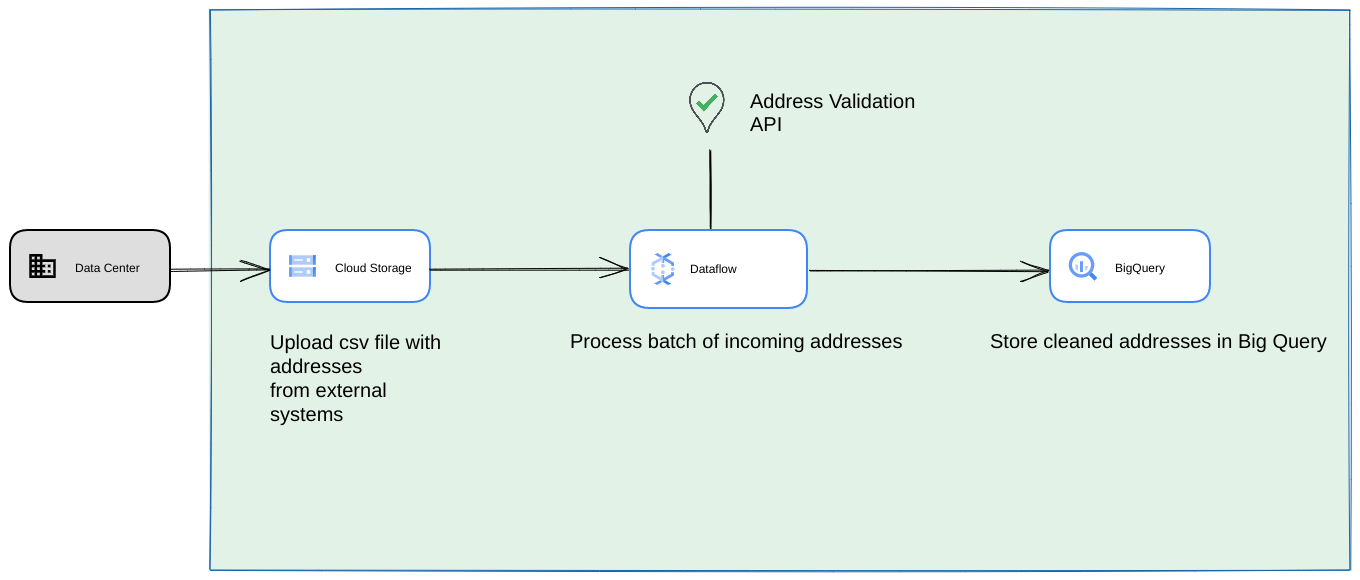
- In diesem Fall können Sie CSV-Dateien in Cloud Storage-Buckets ablegen.
- Ein Dataflow-Job kann die zu verarbeitenden Adressen abrufen und dann in BigQuery zwischenspeichern.
- Die Dataflow Python-Bibliothek kann erweitert werden, um Logik für die High Volume Address Validation zu enthalten, mit der die Adressen aus dem Dataflow-Job validiert werden.
Skript aus einer Datenpipeline als langfristigen wiederkehrenden Prozess ausführen
Ein weiterer gängiger Ansatz ist die Validierung eines Batches von Adressen als Teil einer Streaming-Datenpipeline als wiederkehrender Prozess. Möglicherweise sind die Adressen auch in einem BigQuery-Datenspeicher vorhanden. In diesem Ansatz wird gezeigt, wie eine wiederkehrende Datenpipeline erstellt wird, die täglich, wöchentlich oder monatlich ausgelöst werden muss.
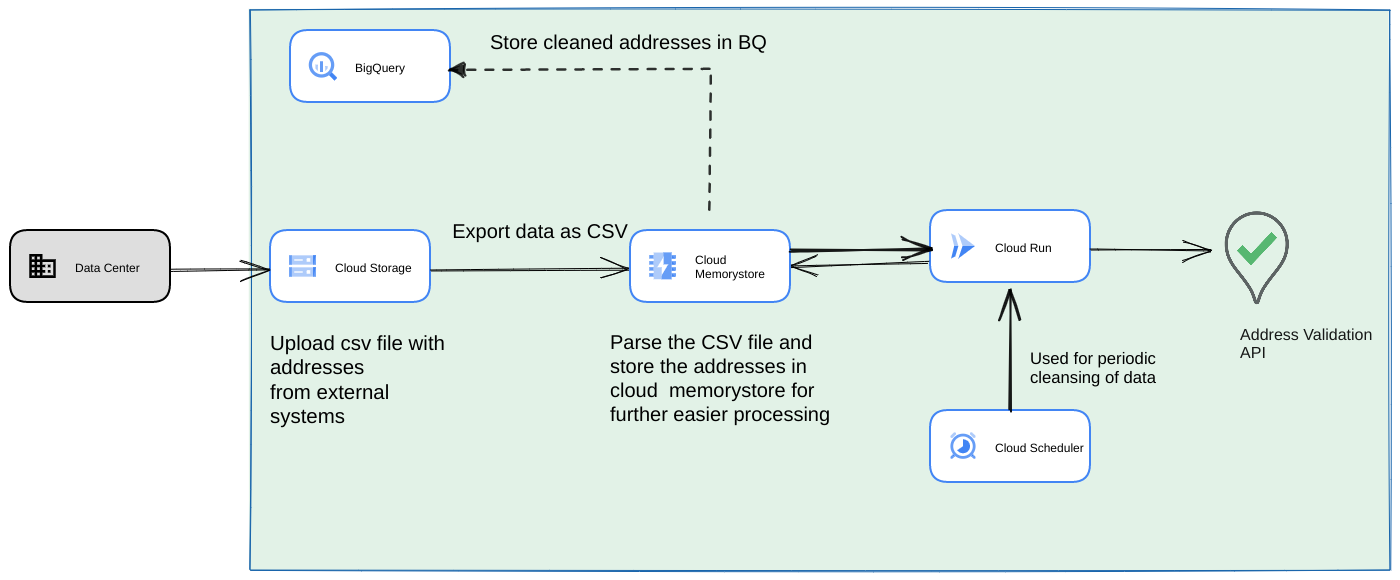
- Laden Sie die ursprüngliche CSV-Datei in einen Cloud Storage-Bucket hoch.
- Verwenden Sie Memorystore als persistenten Datenspeicher, um den Zwischenzustand für den langlaufenden Prozess zu erhalten.
- Die endgültigen Adressen werden in einem BigQuery-Datenspeicher zwischengespeichert.
- Richten Sie Cloud Scheduler ein, um das Skript regelmäßig auszuführen.
Diese Architektur bietet folgende Vorteile:
- Mithilfe von Cloud Scheduler kann die Adressvalidierung regelmäßig durchgeführt werden. Möglicherweise möchten Sie die Adressen monatlich neu validieren oder neue Adressen monatlich/vierteljährlich validieren. Diese Architektur trägt zur Lösung dieses Anwendungsfalls bei.
Wenn sich die Kundendaten in BigQuery befinden, können die validierten Adressen oder die Validierungsflags direkt dort zwischengespeichert werden. Hinweis: Was gecacht werden kann und wie, wird im Artikel Adressvalidierung mit hohem Volumen ausführlich beschrieben.
Die Verwendung von Memorystore bietet eine höhere Ausfallsicherheit und die Möglichkeit, mehr Adressen zu verarbeiten. Dieser Schritt fügt der gesamten Verarbeitungspipeline einen Zustandszustand hinzu, der für die Verarbeitung sehr großer Adressdatensätze erforderlich ist. Andere Datenbanktechnologien wie Cloud SQL[https://cloud.google.com/sql] oder jede andere Variante der Datenbank, die die Google Cloud Platform anbietet, können hier ebenfalls verwendet werden. Wir sind jedoch der Ansicht, dass memorystore perfectless die Anforderungen an Skalierbarkeit und Einfachheit in Einklang bringt und daher die erste Wahl sein sollte.
Fazit
Durch die Anwendung der hier beschriebenen Muster können Sie die Address Validation API für verschiedene Anwendungsfälle und aus verschiedenen Anwendungsfällen auf der Google Cloud Platform verwenden.
Wir haben eine Open-Source-Python-Bibliothek geschrieben, die Ihnen den Einstieg in die oben beschriebenen Anwendungsfälle erleichtert. Es kann über die Kommandozeile Ihres Computers oder über die Google Cloud Platform oder andere Cloud-Anbieter aufgerufen werden.
Mehr über die Verwendung der Bibliothek erfahren Sie in diesem article.
Nächste Schritte
Laden Sie das Whitepaper zum Optimieren von Bezahlvorgang, Lieferung und Betrieb mit gültigen Adressen herunter und sehen Sie sich das Webinar zum Optimieren von Bezahlvorgang, Lieferung und Betrieb mit Address Validation an.
Empfohlene Artikel:
- Dokumentation zur Address Validation API
- Geocoding und Adressbestätigung
- Address Validation-Demo ansehen
Beitragende
Dieser Artikel wird von Google verwaltet. Die folgenden Mitwirkenden haben den Artikel ursprünglich verfasst.
Hauptautoren:
Henrik Valve | Solutions Engineer
Thomas Anglaret | Solutions Engineer
Sarthak Ganguly | Solutions Engineer