Obiettivo
Il tutorial Convalida indirizzi ad alto volume ti ha guidato attraverso diversi scenari in cui è possibile utilizzare la convalida indirizzi ad alto volume. In questo tutorial, ti presenteremo diversi pattern di progettazione all'interno di Google Cloud per l'esecuzione della convalida degli indirizzi ad alto volume.
Inizieremo con una panoramica sull'esecuzione della convalida degli indirizzi ad alto volume in Google Cloud con Cloud Run, Compute Engine o Google Kubernetes Engine per le esecuzioni una tantum. Vedremo poi come questa funzionalità può essere inclusa in una pipeline di dati.
Al termine di questo articolo, dovresti avere una buona comprensione delle diverse opzioni per eseguire la convalida degli indirizzi in volumi elevati nel tuo ambiente Google Cloud.
Architettura di riferimento su Google Cloud
Questa sezione analizza più nel dettaglio diversi pattern di progettazione per la convalida degli indirizzi ad alto volume utilizzando Google Cloud Platform. Se utilizzi Google Cloud Platform, puoi integrarti con i processi e le pipeline di dati esistenti.
Esecuzione una tantum di High Volume Address Validation su Google Cloud
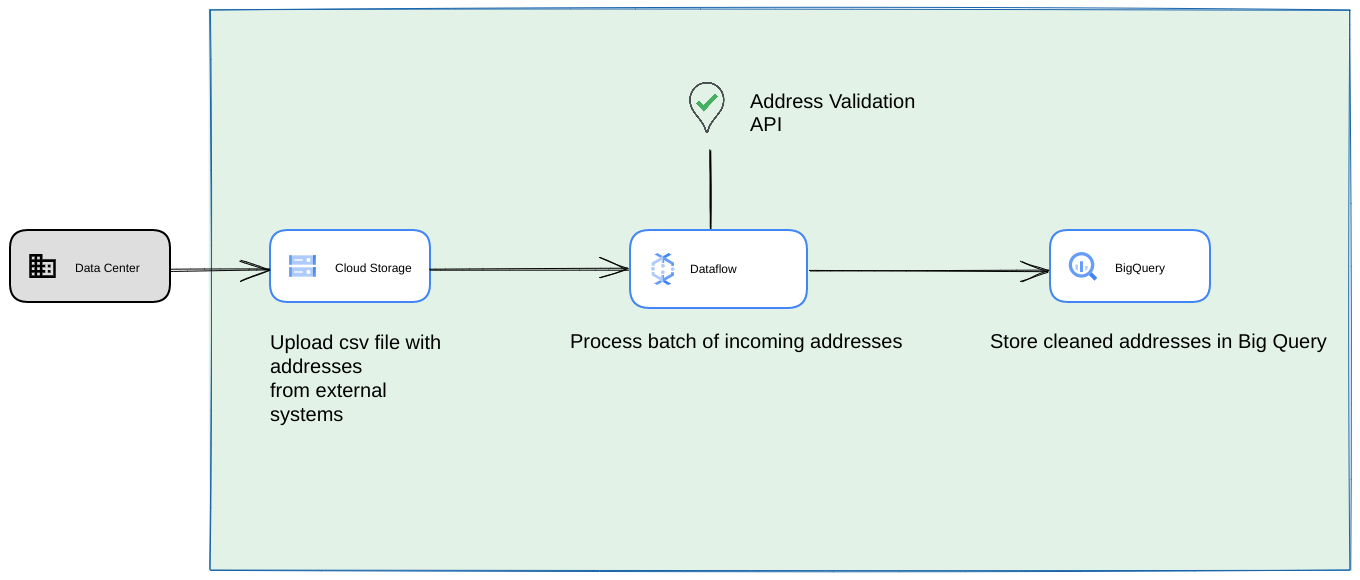
Di seguito è riportata un'architettura di riferimento su come creare un'integrazione su Google Cloud Platform più adatta a operazioni o test una tantum.

In questo caso, ti consigliamo di caricare il file CSV in un bucket Cloud Storage. Lo script di convalida degli indirizzi ad alto volume può quindi essere eseguito da un ambiente Cloud Run. Tuttavia, puoi eseguirlo in qualsiasi altro ambiente di runtime come Compute Engine o Google Kubernetes Engine. Il file CSV di output può essere caricato anche nel bucket Cloud Storage.
Esecuzione come pipeline di dati di Google Cloud Platform
Il pattern di deployment mostrato nella sezione precedente è ideale per testare rapidamente la convalida degli indirizzi ad alto volume per un utilizzo una tantum. Tuttavia, se devi utilizzarlo regolarmente nell'ambito di una pipeline di dati, puoi sfruttare al meglio le funzionalità native di Google Cloud per renderlo più solido. Alcune delle modifiche che puoi apportare includono:
- In questo caso, puoi scaricare i file CSV nei bucket Cloud Storage.
- Un job Dataflow può recuperare gli indirizzi da elaborare e memorizzarli nella cache in BigQuery.
- La libreria Python di Dataflow può essere estesa per includere la logica per la convalida degli indirizzi ad alto volume per convalidare gli indirizzi del job Dataflow.
Esecuzione dello script da una pipeline di dati come processo ricorrente di lunga durata
Un altro approccio comune è convalidare un batch di indirizzi nell'ambito di una pipeline di dati di streaming come processo ricorrente. Potresti anche avere gli indirizzi in un datastore BigQuery. In questo approccio vedremo come creare una pipeline di dati ricorrente (che deve essere attivata giornalmente/settimanalmente/mensilmente)
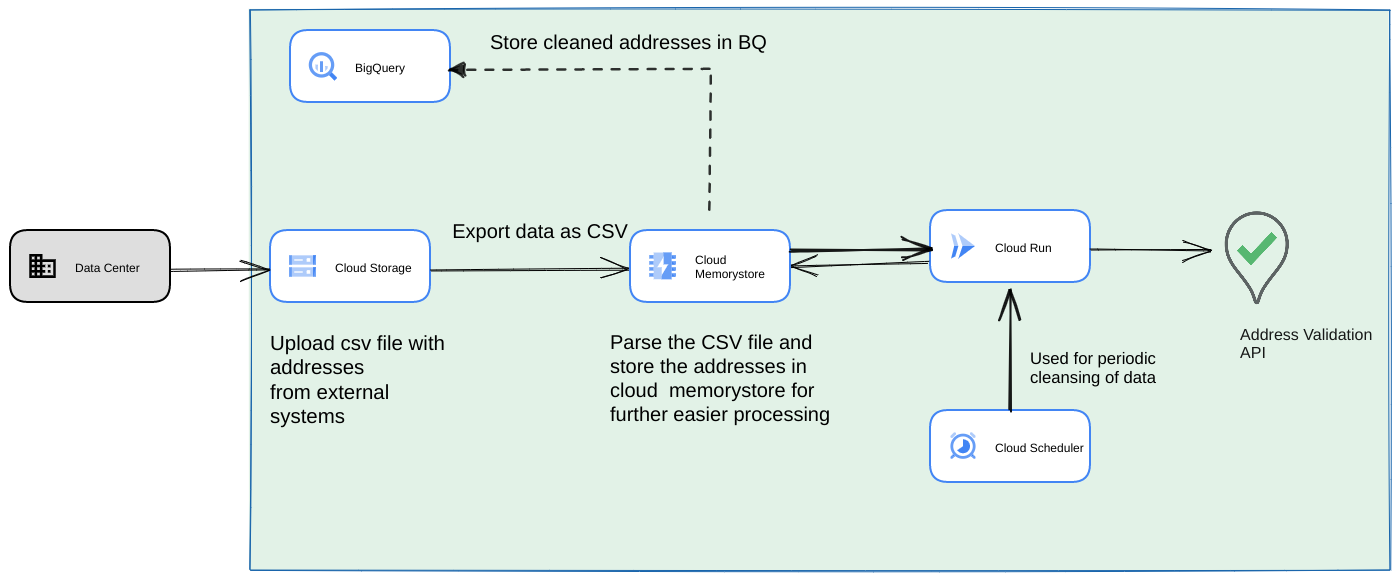
- Carica il file CSV iniziale in un bucket Cloud Storage.
- Utilizza Memorystore come datastore persistente per mantenere lo stato intermedio per il processo a esecuzione prolungata.
- Memorizza nella cache gli indirizzi finali in un datastore BigQuery.
- Configura Cloud Scheduler per eseguire lo script periodicamente.
Questa architettura presenta i seguenti vantaggi:
- Utilizzando Cloud Scheduler, la convalida dell'indirizzo può essere eseguita periodicamente. Ti consigliamo di convalidare nuovamente gli indirizzi su base mensile o di convalidare i nuovi indirizzi su base mensile/trimestrale. Questa architettura aiuta a risolvere questo caso d'uso.
Se i dati dei clienti si trovano in BigQuery, gli indirizzi convalidati o i flag di convalida possono essere memorizzati direttamente nella cache. Nota: cosa può essere memorizzato nella cache e come è descritto in dettaglio nell'articolo Convalida indirizzi ad alto volume.
L'utilizzo di Memorystore offre una maggiore resilienza e la possibilità di elaborare più indirizzi. Questo passaggio aggiunge uno stato all'intera pipeline di elaborazione, necessario per la gestione di set di dati di indirizzi molto grandi. Possono essere utilizzate anche altre tecnologie di database come Cloud SQL[https://cloud.google.com/sql] o qualsiasi altro tipo di database offerto da Google Cloud Platform. Tuttavia, riteniamo che Memorystore bilanci perfettamente le esigenze di scalabilità e semplicità, quindi dovrebbe essere la prima scelta.
Conclusione
Applicando i pattern descritti qui, puoi utilizzare l'API Address Validation per diversi casi d'uso e da diversi casi d'uso su Google Cloud Platform.
Abbiamo scritto una libreria Python open source per aiutarti a iniziare con i casi d'uso descritti sopra. Può essere richiamato da una riga di comando sul computer o da Google Cloud Platform o altri provider cloud.
Scopri di più su come utilizzare la raccolta in questo articolo.
Passaggi successivi
Scarica il white paper Migliora pagamento, consegna e operazioni con indirizzi affidabili e guarda il webinar Migliorare pagamento, consegna e operazioni con la convalida dell'indirizzo .
Letture consigliate:
- Documentazione dell'API Address Validation
- Geocoding e convalida dell'indirizzo
- Esplora la demo di Address Validation
Collaboratori
Google gestisce questo articolo. I seguenti collaboratori lo hanno scritto originariamente.
Autori principali:
Henrik Valve | Solutions Engineer
Thomas Anglaret | Solutions Engineer
Sarthak Ganguly | Solutions Engineer