
연결된 시트를 사용하면 Google Sheets 내에서 직접 페타바이트 규모의 데이터를 분석할 수 있습니다. 스프레드시트를 BigQuery 데이터 웨어하우스 또는 Looker에 연결하고 피벗 테이블, 차트, 수식과 같은 익숙한 Sheets 도구를 사용하여 분석할 수 있습니다.
BigQuery 데이터 소스 관리
이 섹션에서는 BigQuery Shakespeare 공개 데이터 세트를 사용하여 연결된 시트를 사용하는 방법을 보여줍니다. 데이터 세트에는 다음 정보가 포함됩니다.
| 필드 | 유형 | 설명 |
|---|---|---|
| word | STRING |
코퍼스에서 추출한 고유한 단어 하나입니다 (공백이 구분자임). |
| word_count | INTEGER |
이 단어가 이 말뭉치에 표시되는 횟수입니다. |
| corpus | STRING |
이 단어가 추출된 작품입니다. |
| corpus_date | INTEGER |
이 말뭉치가 게시된 연도입니다. |
애플리케이션이 BigQuery 연결된 시트 데이터를 요청하는 경우 일반 Google Sheets API 요청에 필요한 다른 범위 외에도 bigquery.readonly 범위를 부여하는 OAuth 2.0 토큰을 제공해야 합니다. 자세한 내용은 Google Sheets API 범위 선택을 참고하세요.
데이터 소스는 데이터가 있는 외부 위치를 지정합니다. 그러면 데이터 소스가 스프레드시트에 연결됩니다.
BigQuery 데이터 소스 추가
데이터 소스를 추가하려면 spreadsheets.batchUpdate 메서드를 사용하여 AddDataSourceRequest를 제공합니다. 요청 본문은 DataSource 객체 유형의 dataSource 필드를 지정해야 합니다.
"addDataSource":{
"dataSource":{
"spec":{
"bigQuery":{
"projectId":"PROJECT_ID",
"tableSpec":{
"tableProjectId":"bigquery-public-data",
"datasetId":"samples",
"tableId":"shakespeare"
}
}
}
}
}
PROJECT_ID를 유효한 Google Cloud 프로젝트 ID로 바꿉니다.
데이터 소스를 만들면 최대 500개의 행을 미리 볼 수 있는 연결된 DATA_SOURCE 시트가 생성됩니다. 미리보기를 즉시 사용할 수 있는 것은 아닙니다. BigQuery 데이터를 가져오기 위해 비동기적으로 실행이 트리거됩니다.
AddDataSourceResponse에는 다음 필드가 포함됩니다.
dataSource: 생성된DataSource객체입니다.dataSourceId은 스프레드시트 범위의 고유 ID입니다. 데이터 소스에서 각DataSource객체를 만들기 위해 채워지고 참조됩니다.dataExecutionStatus: BigQuery 데이터를 미리보기 시트로 가져오는 실행의 상태입니다. 자세한 내용은 데이터 실행 상태 섹션을 참고하세요.
BigQuery 데이터 소스 업데이트 또는 삭제
spreadsheets.batchUpdate 메서드를 사용하고 UpdateDataSourceRequest 또는 DeleteDataSourceRequest 요청을 적절하게 제공합니다.
BigQuery 데이터 소스 객체 관리
데이터 소스가 스프레드시트에 추가되면 데이터 소스 객체를 만들 수 있습니다. 데이터 소스 객체는 연결된 시트와 통합되어 데이터 분석을 지원하는 피벗 테이블, 차트, 수식과 같은 일반 시트 도구입니다.
객체에는 네 가지 유형이 있습니다.
- 테이블
DataSource개 DataSourcepivotTableDataSource차트DataSource수식
BigQuery 데이터 소스 테이블 추가
Sheets 편집기에서 '추출'이라고 하는 테이블 객체는 데이터 소스의 정적 데이터 덤프를 Sheets로 가져옵니다. 피벗 테이블과 마찬가지로 테이블이 지정되고 왼쪽 상단 셀에 고정됩니다.
다음 코드 샘플은 spreadsheets.batchUpdate 메서드와 UpdateCellsRequest를 사용하여 두 열 (word 및 word_count)의 행이 최대 1,000개인 데이터 소스 테이블을 만드는 방법을 보여줍니다.
"updateCells":{
"rows":{
"values":[
{
"dataSourceTable":{
"dataSourceId":"DATA_SOURCE_ID",
"columns":[
{
"name":"word"
},
{
"name":"word_count"
}
],
"rowLimit":{
"value":1000
},
"columnSelectionType":"SELECTED"
}
}
]
},
"fields":"dataSourceTable"
}
DATA_SOURCE_ID를 데이터 소스를 식별하는 스프레드시트 범위의 고유 ID로 바꿉니다.
데이터 소스 테이블이 생성된 후에는 데이터를 바로 사용할 수 없습니다. Sheets 편집기에서는 미리보기로 표시됩니다. BigQuery 데이터를 가져오려면 데이터 소스 테이블을 새로고침해야 합니다. 동일한 batchUpdate 내에서 RefreshDataSourceRequest를 지정할 수 있습니다. 모든 데이터 소스 객체는 유사하게 작동합니다.
자세한 내용은 데이터 소스 객체 새로고침을 참고하세요.
새로고침이 완료되고 BigQuery 데이터가 가져와지면 데이터 소스 표가 다음과 같이 채워집니다.

BigQuery 데이터 소스 피벗 테이블 추가
일반적인 피벗 테이블과 달리 데이터 소스 피벗 테이블은 데이터 소스를 기반으로 하며 열 이름으로 데이터를 참조합니다. 다음 코드 샘플은 spreadsheets.batchUpdate 메서드와 UpdateCellsRequest를 사용하여 코퍼스별 총 단어 수를 보여주는 피벗 테이블을 만드는 방법을 보여줍니다.
"updateCells":{
"rows":{
"values":[
{
"pivotTable":{
"dataSourceId":"DATA_SOURCE_ID",
"rows":{
"dataSourceColumnReference":{
"name":"corpus"
},
"sortOrder":"ASCENDING"
},
"values":{
"summarizeFunction":"SUM",
"dataSourceColumnReference":{
"name":"word_count"
}
}
}
}
]
},
"fields":"pivotTable"
}
DATA_SOURCE_ID를 데이터 소스를 식별하는 스프레드시트 범위의 고유 ID로 바꿉니다.
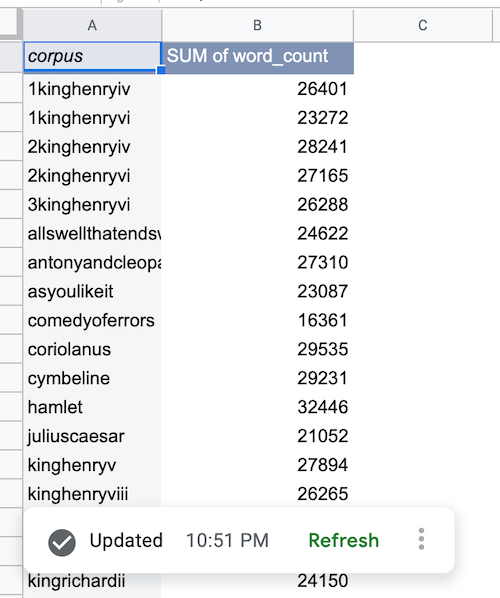
BigQuery 데이터를 가져오면 데이터 소스 피벗 테이블이 다음과 같이 채워집니다.
BigQuery 데이터 소스 차트 추가
다음 코드 샘플은 spreadsheets.batchUpdate 메서드와 AddChartRequest를 사용하여 코퍼스별 총 단어 수를 보여주는 chartType이 COLUMN인 데이터 소스 차트를 만드는 방법을 보여줍니다.
"addChart":{
"chart":{
"spec":{
"title":"Corpus by word count",
"basicChart":{
"chartType":"COLUMN",
"domains":[
{
"domain":{
"columnReference":{
"name":"corpus"
}
}
}
],
"series":[
{
"series":{
"columnReference":{
"name":"word_count"
},
"aggregateType":"SUM"
}
}
]
}
},
"dataSourceChartProperties":{
"dataSourceId":"DATA_SOURCE_ID"
}
}
}
DATA_SOURCE_ID를 데이터 소스를 식별하는 스프레드시트 범위의 고유 ID로 바꿉니다.
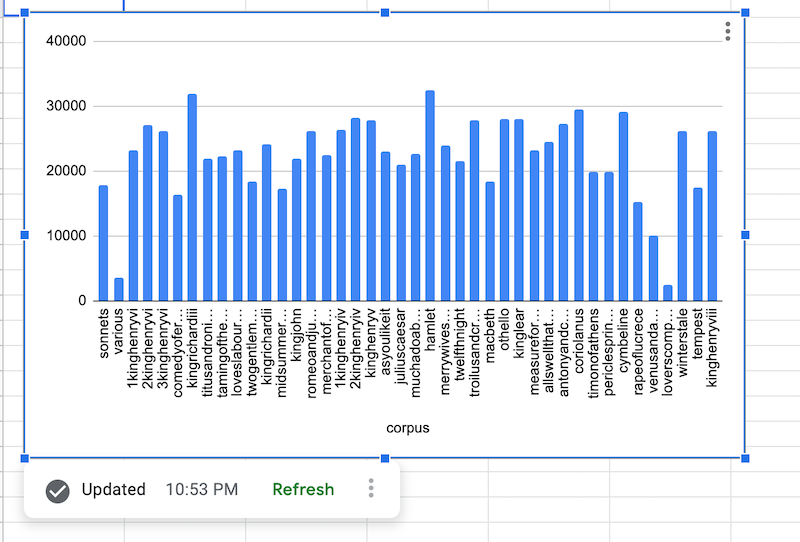
BigQuery 데이터를 가져온 후 데이터 소스 차트가 다음과 같이 렌더링됩니다.
BigQuery 데이터 소스 수식 추가
다음 코드 샘플은 spreadsheets.batchUpdate 메서드와 UpdateCellsRequest를 사용하여 평균 단어 수를 계산하는 데이터 소스 수식을 만드는 방법을 보여줍니다.
"updateCells":{
"rows":[
{
"values":[
{
"userEnteredValue":{
"formulaValue":"=AVERAGE(shakespeare!word_count)"
}
}
]
}
],
"fields":"userEnteredValue"
}
BigQuery 데이터를 가져오면 데이터 소스 수식이 다음과 같이 채워집니다.

BigQuery 데이터 소스 객체 새로고침
데이터 소스 객체를 새로고침하여 현재 데이터 소스 사양 및 객체 구성을 기반으로 BigQuery에서 최신 데이터를 가져올 수 있습니다. spreadsheets.batchUpdate 메서드를 사용하여 RefreshDataSourceRequest를 호출할 수 있습니다.
그런 다음 DataSourceObjectReferences 객체를 사용하여 새로고침할 객체 참조를 하나 이상 지정합니다.
단일 batchUpdate 요청 내에서 데이터 소스 객체를 생성하고 새로고침할 수 있습니다.
Looker 데이터 소스 관리
이 가이드에서는 Looker 데이터 소스를 추가, 업데이트, 삭제하고, Looker 데이터 소스에서 피벗 테이블을 만들고 새로고침하는 방법을 보여줍니다.
Looker에 연결된 시트 데이터를 요청하는 애플리케이션은 Looker와의 기존 Google 계정 연결을 재사용합니다.
Looker 데이터 소스 추가
데이터 소스를 추가하려면 spreadsheets.batchUpdate 메서드를 사용하여 AddDataSourceRequest를 제공합니다. 요청 본문은 DataSource 객체 유형의 dataSource 필드를 지정해야 합니다.
"addDataSource":{
"dataSource":{
"spec":{
"looker":{
"instance_uri":"INSTANCE_URI",
"model":"MODEL",
"explore":"EXPLORE"
}
}
}
}
INSTANCE_URI, MODEL, EXPLORE을 각각 유효한 Looker 인스턴스 URI, 모델 이름, 탐색 이름으로 바꿉니다.
데이터 소스를 만들면 연결된 DATA_SOURCE 시트가 생성되어 뷰, 측정기준, 측정, 필드 설명을 포함한 선택한 Explore의 구조를 미리 볼 수 있습니다.
AddDataSourceResponse에는 다음 필드가 포함됩니다.
dataSource: 생성된DataSource객체입니다.dataSourceId은 스프레드시트 범위의 고유 ID입니다. 데이터 소스에서 각DataSource객체를 만들기 위해 채워지고 참조됩니다.dataExecutionStatus: BigQuery 데이터를 미리보기 시트로 가져오는 실행의 상태입니다. 자세한 내용은 데이터 실행 상태 섹션을 참고하세요.
Looker 데이터 소스 업데이트 또는 삭제하기
spreadsheets.batchUpdate 메서드를 사용하고 UpdateDataSourceRequest 또는 DeleteDataSourceRequest 요청을 적절하게 제공합니다.
Looker 데이터 소스 객체 관리
데이터 소스가 스프레드시트에 추가되면 데이터 소스 객체를 만들 수 있습니다. Looker 데이터 소스의 경우 DataSource 피벗 테이블 객체만 만들 수 있습니다.
Looker 데이터 소스에서 DataSource 수식, 추출, 차트를 만들 수 없습니다.
Looker 데이터 소스 객체 새로고침
데이터 소스 객체를 새로고침하여 현재 데이터 소스 사양 및 객체 구성을 기반으로 Looker에서 최신 데이터를 가져올 수 있습니다. spreadsheets.batchUpdate 메서드를 사용하여 RefreshDataSourceRequest를 호출할 수 있습니다.
그런 다음 DataSourceObjectReferences 객체를 사용하여 새로고침할 객체 참조를 하나 이상 지정합니다.
단일 batchUpdate 요청 내에서 데이터 소스 객체를 생성하고 새로고침할 수 있습니다.
데이터 실행 상태
데이터 소스를 만들거나 데이터 소스 객체를 새로고침하면 BigQuery 또는 Looker에서 데이터를 가져오고 DataExecutionStatus가 포함된 응답을 반환하는 백그라운드 실행이 생성됩니다.
실행이 성공적으로 시작되면 DataExecutionState은 일반적으로 RUNNING 상태입니다.
이 프로세스는 비동기식이므로 애플리케이션은 폴링 모델을 구현하여 데이터 소스 객체의 상태를 주기적으로 검색해야 합니다. 상태가 SUCCEEDED 또는 FAILED 상태를 반환할 때까지 spreadsheets.get 메서드를 사용합니다.
대부분의 경우 실행이 빠르게 완료되지만 데이터 소스의 복잡성에 따라 달라집니다. 일반적으로 실행 시간은 10분을 초과하지 않습니다.
관련 주제
- Google Sheets API 범위 선택하기
- Google Sheets에서 BigQuery 데이터 시작하기
- BigQuery 문서
- BigQuery: 연결된 시트 사용하기
- 연결된 시트 동영상 튜토리얼
- Looker용 연결된 시트 사용
- Looker 소개