
Ein Google Cloud Search-Schema ist eine JSON-Struktur, in der Objekte, Attribute und Optionen für das Indexieren und Abfragen von Daten definiert sind. Ihr Inhaltsconnector verwendet das registrierte Schema, um Repository-Daten zu strukturieren und zu indexieren.
Sie erstellen ein Schema, indem Sie der API ein JSON-Schemaobjekt bereitstellen. Sie müssen für jedes Repository ein Schema registrieren, bevor Sie Daten indexieren.
In diesem Dokument werden die Grundlagen der Schemaerstellung behandelt. Informationen zur Optimierung der Suchfunktionen finden Sie unter Suchqualität verbessern.
Schema erstellen
So erstellen Sie ein Cloud Search-Schema:
- Zu erwartendes Nutzerverhalten bestimmen
- Datenquelle initialisieren
- Objekte definieren
- Objekt-Attribute definieren
- Schema registrieren
- Daten indexieren
- Schema testen
- Schema anpassen
Zu erwartendes Nutzerverhalten bestimmen
Wenn Sie wissen, wie Nutzer suchen, können Sie Ihre Schemastrategie besser definieren. Bei einer Filmdatenbank suchen Nutzer möglicherweise nach „Filme mit Robert Redford“. Ihr Schema muss Abfragen für Filme mit einem bestimmten Schauspieler unterstützen.
So richten Sie Ihr Schema am Nutzerverhalten aus:
- Analysieren Sie unterschiedliche Suchabfragen von verschiedenen Nutzern.
- Identifizieren Sie logische Datensätze oder Objekte, z. B. einen „Film“.
- Identifizieren Sie Attribute wie Titel oder Veröffentlichungsdatum.
- Identifizieren Sie gültige Werte für Attribute, z. B. „Jäger des verlorenen Schatzes“.
- Bestimmen Sie die Sortier- und Rankinganforderungen, z. B. chronologische Reihenfolge oder Publikumsbewertungen.
- Identifizieren Sie Kontextattribute wie die Berufsbezeichnung, um die Vorschläge für die automatische Vervollständigung zu verbessern.
- Listen Sie diese Objekte, Attribute und Beispielwerte auf. Verwenden Sie diese Liste, um Operatoroptionen zu definieren.
Datenquelle initialisieren
Eine Datenquelle stellt indexierte Repository-Daten dar, die in Google Cloud gespeichert sind. Weitere Informationen finden Sie unter Integration von Drittanbietern. Wenn ein Nutzer auf ein Ergebnis klickt, wird er von Cloud Search über die URL aus der Indexierungsanforderung zum Element weitergeleitet.
Objekte definieren
Das Objekt ist die Grundeinheit eines Schemas. Logische Strukturen wie „Film“ oder „Person“ sind Objekte. Jedes Objekt hat Attribute wie Titel, Dauer oder Name.
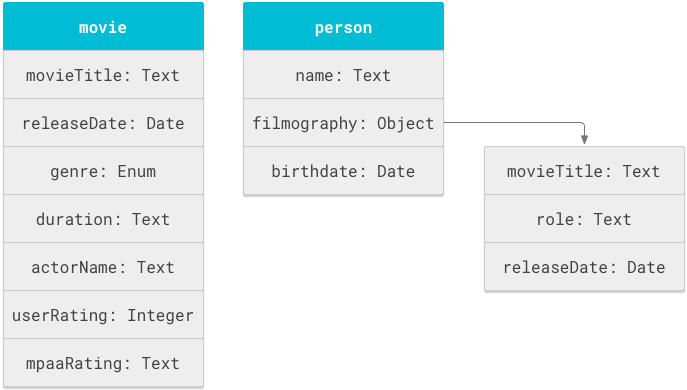
Ein Schema ist eine Liste von
Objektdefinitionen im objectDefinitions Tag.
{
"objectDefinitions": [
{ "name": "movie" },
{ "name": "person" }
]
}
Verwenden Sie für jedes Objekt eindeutige Namen, z. B. movie. Der Schemadienst verwendet diese Namen als Schlüssel. Weitere Informationen finden Sie unter
ObjectDefinition.
Objekt-Attribute definieren
Definieren Sie Attribute wie Titel und Veröffentlichungsdatum im Abschnitt propertyDefinitions. Verwenden Sie
options
für
freshnessOptions
(Ranking) und
displayOptions
(UI-Labels).
{
"objectDefinitions": [{
"name": "movie",
"propertyDefinitions": [
{
"name": "movieTitle",
"isReturnable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": { "operatorName": "title" }
},
"displayOptions": { "displayLabel": "Title" }
},
{
"name": "releaseDate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "released",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
}
}
]
}]
}
Eine PropertyDefinition enthält:
- Einen
name-String. - Typunabhängige Optionen (z.B.
isReturnable). - Einen Typ und typspezifische Optionen (z.B.
textPropertyOptions). operatorOptionsfür Suchoperatoren.displayOptionsfür UI-Labels.
Sie können Attributnamen für verschiedene Objekte wiederverwenden. movieTitle
kann beispielsweise sowohl in einem movie Objekt als auch in der Filmografie eines person Objekts vorkommen.
Typunabhängige Optionen hinzufügen
PropertyDefinition
enthält boolesche Optionen zum Konfigurieren der Suchfunktionen für ein Attribut,
unabhängig vom Typ. Diese Optionen sind standardmäßig auf false gesetzt und müssen auf true gesetzt werden, damit sie verwendet werden können.
isReturnable: Legen Sie diese Option auftruefest, wenn die Attributdaten in Suchergebnissen über die Query API zurückgegeben werden sollen. Nicht rückgabefähige Attribute können für die Suche oder das Ranking verwendet werden, ohne in den Ergebnissen angezeigt zu werden.isRepeatable: Legen Sie diese Option auftruefest, wenn das Attribut mehrere Werte haben kann. Ein Film hat beispielsweise ein Veröffentlichungsdatum, aber mehrere Schauspieler.isSortable: Legen Sie diese Option auftruefest, wenn das Attribut zum Sortieren verwendet werden kann. Diese Option kann nichttruesein, wennisRepeatabletrueist oder wenn sich das Attribut in einem wiederholbaren Unterobjekt befindet.isFacetable: Legen Sie diese Option auftruefest, wenn das Attribut zum Generieren von Facetten verwendet werden kann (Attribute, mit denen Suchergebnisse verfeinert werden).- Dazu muss
isReturnableauftruegesetzt sein. - Wird nur für Attribute vom Typ „Aufzählung“, „Bool“ und „Text“ unterstützt.
- Dazu muss
isWildcardSearchable: Legen Sie diese Option auftruefest, damit Nutzer Platzhaltersuchen für dieses Attribut ausführen können. Diese Option ist nur für Textattribute verfügbar und ihr Verhalten hängt von der EinstellungexactMatchWithOperatorab:- Wenn
exactMatchWithOperatorauftruegesetzt ist, wird der Textwert als einzelnes Token behandelt. Eine Abfrage wiescience-*stimmt mit dem Wertscience-fictionüberein. - Wenn
exactMatchWithOperatorauffalsegesetzt ist, wird der Textwert in Tokens zerlegt. Eine Abfrage wiesci*oderfi*stimmt mitscience-fictionüberein,science-*jedoch nicht.
- Wenn
Typ definieren
Legen Sie den Datentyp fest, indem Sie das entsprechende Objekt für die Attributoptionen definieren (z.B. textPropertyOptions). Verwenden Sie Aufzählungen (enumPropertyOptions), wenn Sie alle möglichen Werte kennen. Ein Attribut kann nur einen Datentyp haben.
Operatoroptionen festlegen
operatorOptions beschreiben, wie ein Attribut als Suchoperator funktioniert.
Jedes operatorOptions benötigt einen operatorName (z.B. title). Dies ist der
Parameter, den Nutzer in Abfragen eingeben (z.B. title:titanic). Verwenden Sie intuitive Namen
und machen Sie sie für Nutzer sichtbar.
Sie können einen operatorName für Attribute desselben Typs freigeben. Bei Abfragen mit diesem Namen werden Ergebnisse aus allen übereinstimmenden Attributen abgerufen.
Sortierbare Attribute können lessThanOperatorName und greaterThanOperatorName für Vergleichsabfragen enthalten. Für Textattribute kann exactMatchWithOperator verwendet werden, um den gesamten Wert als einzelnes Token zu behandeln.
Anzeigeoptionen hinzufügen
Der optionale Abschnitt displayOptions enthält ein displayLabel. Dies ist ein nutzerfreundliches Label, das in den Suchergebnissen angezeigt wird.
Operatoren zum Filtern von Vorschlägen hinzufügen
Verwenden Sie suggestionFilteringOperators[], um ein Attribut zu definieren, das Vorschläge für die automatische Vervollständigung filtert (z.B. Filmvorschläge nach dem bevorzugten Genre eines Nutzers). Sie können nur einen Vorschlagsfilter definieren.
Schema registrieren
Registrieren Sie Ihr Schema mit der Datenquellen-ID beim Schemadienst. Geben Sie eine UpdateSchema Anforderung aus:
PUT https://cloudsearch.googleapis.com/v1/indexing/{name=datasources/*}/schema
Verwenden Sie validateOnly: true, um Ihr Schema zu testen, ohne es zu registrieren.
Daten indexieren
Nach der Registrierung können Sie die Datenquelle mithilfe von Index -Aufrufen füllen, in der Regel mit einem Connector.
Beispiel für eine Indexierungsanforderung:
{
"name": "datasource/<data_source_id>/items/titanic",
"metadata": {
"title": "Titanic",
"objectType": "movie"
},
"structuredData": {
"object": {
"properties": [{
"name": "movieTitle",
"textValues": { "values": ["Titanic"] }
}]
}
},
"itemType": "CONTENT_ITEM"
}
Schema testen
Testen Sie vor der Produktion mit einem kleinen Repository. Erstellen Sie eine ACL, die die Ergebnisse auf einen Testnutzer beschränkt.
- Allgemeine Abfrage: Suchen Sie nach einem String (z.B. „titanic“), um alle übereinstimmenden Elemente zu sehen.
- Operatorabfrage: Verwenden Sie einen Operator (z.B.
actor:Zane), um die Ergebnisse zu beschränken.
Schema anpassen
Behalten Sie das Nutzerfeedback im Blick und passen Sie Ihr Schema an. Möglicherweise indexieren Sie neue Felder oder benennen Operatoren um, damit sie intuitiver sind.
Nach einer Schemaänderung neu indexieren
Bei Änderungen an folgenden Elementen ist keine Neuindexierung erforderlich:
- Operatornamen
- Numerische Grenzwerte
- Sortiertes Ranking
- Optionen für Aktualität oder Anzeige
In folgenden Fällen müssen Sie neu indexieren:
- Hinzufügen oder Entfernen von Attributen oder Objekten
- Ändern von
isReturnable,isFacetableoderisSortableintrue - Markieren eines Attributs als
isSuggestable
Nicht zulässige Attributänderungen
Änderungen, die den Index beschädigen oder zu inkonsistenten Ergebnissen führen, sind nicht zulässig. Dazu gehören:
- Datentyp oder Name des Attributs
- Einstellungen für
exactMatchWithOperatoroderretrievalImportance
Komplexe Schemaänderungen vornehmen
Wenn Sie eine nicht zulässige Änderung vornehmen möchten, migrieren Sie Attribute aus einer alten Definition in eine neue:
- Fügen Sie dem Schema ein neues Attribut mit einem anderen Namen hinzu.
- Registrieren Sie das Schema mit den neuen und alten Attributen.
- Füllen Sie den Index nur mit dem neuen Attribut auf.
- Löschen Sie das alte Attribut aus dem Schema.
- Aktualisieren Sie Ihren Abfragecode, um den neuen Attributnamen zu verwenden.
In Cloud Search werden gelöschte Elemente 30 Tage lang gespeichert, um Probleme bei der Wiederverwendung zu vermeiden.
Größenbeschränkungen
- Maximal 10 Objekte der obersten Ebene
- Maximale Tiefe von 10 Ebenen
- Maximal 1.000 Felder pro Objekt (einschließlich verschachtelter Felder)
Nächste Schritte
- Eine Suchoberfläche erstellen
- Suchqualität verbessern.
- Schema für optimale Abfrageinterpretation strukturieren.
- Synonyme definieren.