
Google Cloud Search का स्कीमा, JSON स्ट्रक्चर होता है. यह डेटा को इंडेक्स करने और क्वेरी करने के लिए, ऑब्जेक्ट, प्रॉपर्टी, और विकल्पों के बारे में बताता है. आपका कॉन्टेंट कनेक्टर, रजिस्टर किए गए स्कीमा का इस्तेमाल करके, रिपॉज़िटरी के डेटा को स्ट्रक्चर करता है और उसे इंडेक्स करता है.
एपीआई को JSON स्कीमा ऑब्जेक्ट देकर, स्कीमा बनाया जा सकता है. डेटा को इंडेक्स करने से पहले, हर रिपॉज़िटरी के लिए स्कीमा रजिस्टर करना ज़रूरी है.
इस दस्तावेज़ में, स्कीमा बनाने की बुनियादी जानकारी दी गई है. सर्च के अनुभव को बेहतर बनाने के लिए, खोज की क्वालिटी बेहतर बनाना लेख पढ़ें.
स्कीमा बनाना
Cloud Search का स्कीमा बनाने के लिए, यह तरीका अपनाएं:
- उपयोगकर्ता के संभावित व्यवहार की पहचान करना
- डेटा सोर्स को शुरू करना
- अपने ऑब्जेक्ट तय करना
- ऑब्जेक्ट की प्रॉपर्टी तय करना
- अपना स्कीमा रजिस्टर करना
- अपने डेटा को इंडेक्स करना
- अपने स्कीमा की जांच करना
- अपने स्कीमा को बेहतर बनाना
उपयोगकर्ता के संभावित व्यवहार की पहचान करना
उपयोगकर्ता किस तरह खोज करते हैं, यह जानने से स्कीमा की रणनीति तय करने में मदद मिलती है. फ़िल्मों के डेटाबेस के लिए, उपयोगकर्ता "रॉबर्ट रेडफ़ोर्ड की फ़िल्में" खोज सकते हैं. आपके स्कीमा में, किसी खास अभिनेता की फ़िल्मों के लिए क्वेरी की सुविधा होनी चाहिए.
अपने स्कीमा को उपयोगकर्ता के व्यवहार के हिसाब से बनाने के लिए:
- अलग-अलग उपयोगकर्ताओं की अलग-अलग क्वेरी का आकलन करें.
- लॉजिकल डेटा सेट या ऑब्जेक्ट की पहचान करें. जैसे, "फ़िल्म."
- प्रॉपर्टी (एट्रिब्यूट) की पहचान करें. जैसे, शीर्षक या रिलीज़ की तारीख.
- प्रॉपर्टी के लिए मान्य वैल्यू की पहचान करें. जैसे, "रेडर्स ऑफ़ द लॉस्ट आर्क."
- सॉर्ट करने और रैंक करने की ज़रूरतें तय करें. जैसे, कालक्रम के हिसाब से क्रम या दर्शकों की रेटिंग.
- ऑटोकंप्लीट के सुझावों को बेहतर बनाने के लिए, कॉन्टेक्स्ट प्रॉपर्टी की पहचान करें. जैसे, नौकरी की भूमिका.
- इन ऑब्जेक्ट, प्रॉपर्टी, और उदाहरण वैल्यू की सूची बनाएं. ऑपरेटर के विकल्प तय करने के लिए, इस सूची का इस्तेमाल करें define operator options.
अपना डेटा सोर्स शुरू करना
डेटा सोर्स , Google Cloud में सेव किए गए, इंडेक्स किए गए रिपॉज़िटरी डेटा को दिखाता है. तीसरे पक्ष के डेटा सोर्स मैनेज करना लेख पढ़ें . जब कोई उपयोगकर्ता किसी नतीजे पर क्लिक करता है, तो Cloud Search उसे इंडेक्स करने के अनुरोध में मौजूद यूआरएल का इस्तेमाल करके, आइटम पर भेजता है.
अपने ऑब्जेक्ट तय करना
ऑब्जेक्ट , स्कीमा की बुनियादी इकाई होती है. "फ़िल्म" या "व्यक्ति" जैसे लॉजिकल स्ट्रक्चर, ऑब्जेक्ट होते हैं. हर ऑब्जेक्ट में प्रॉपर्टी होती हैं. जैसे, शीर्षक, अवधि या नाम.
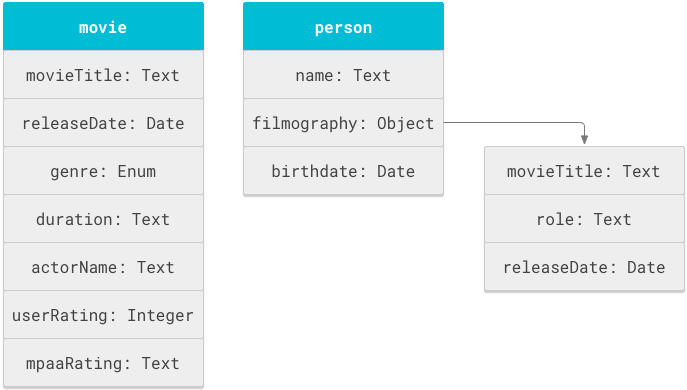
एक स्कीमा,
टैग में ऑब्जेक्ट की परिभाषाओं की सूची होती है.objectDefinitions
{
"objectDefinitions": [
{ "name": "movie" },
{ "name": "person" }
]
}
हर ऑब्जेक्ट के लिए, यूनीक नाम इस्तेमाल करें. जैसे, movie. स्कीमा सेवा, इन नामों को कुंजियों के तौर पर इस्तेमाल करती है.
ObjectDefinition देखें.
ऑब्जेक्ट की प्रॉपर्टी तय करना
propertyDefinitions सेक्शन में, प्रॉपर्टी तय करें. जैसे, शीर्षक और रिलीज़ की तारीख.
freshnessOptions
(रैंकिंग) और
displayOptions
(यूज़र इंटरफ़ेस लेबल) के लिए,
options
का इस्तेमाल करें.
{
"objectDefinitions": [{
"name": "movie",
"propertyDefinitions": [
{
"name": "movieTitle",
"isReturnable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": { "operatorName": "title" }
},
"displayOptions": { "displayLabel": "Title" }
},
{
"name": "releaseDate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "released",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
}
}
]
}]
}
nameस्ट्रिंग.- टाइप-अग्नोस्टिक विकल्प. जैसे,
isReturnable. - टाइप और टाइप के हिसाब से विकल्प. जैसे,
textPropertyOptions. - सर्च ऑपरेटर के लिए,
operatorOptions. - यूज़र इंटरफ़ेस लेबल के लिए,
displayOptions.
अलग-अलग ऑब्जेक्ट के लिए, प्रॉपर्टी के नामों को फिर से इस्तेमाल किया जा सकता है. उदाहरण के लिए, movieTitle
, movie ऑब्जेक्ट और person ऑब्जेक्ट की फ़िल्मोग्राफ़ी, दोनों में दिख सकता है.
टाइप-अग्नोस्टिक विकल्प जोड़ना
PropertyDefinition में, बूलियन विकल्प शामिल होते हैं. इनकी मदद से, किसी प्रॉपर्टी के लिए सर्च की सुविधा को कॉन्फ़िगर किया जा सकता है. भले ही, उसका टाइप कुछ भी हो. ये विकल्प डिफ़ॉल्ट रूप से false पर सेट होते हैं. इनका इस्तेमाल करने के लिए, इन्हें true पर सेट करना ज़रूरी है.
isReturnable: अगर Query API का इस्तेमाल करके, सर्च के नतीजों में प्रॉपर्टी का डेटा दिखाना है, तो इसेtrueपर सेट करें. नतीजों में न दिखने वाली प्रॉपर्टी का इस्तेमाल, खोज या रैंकिंग के लिए किया जा सकता है.isRepeatable: अगर प्रॉपर्टी की कई वैल्यू हो सकती हैं, तो इसेtrueपर सेट करें. उदाहरण के लिए, किसी फ़िल्म की रिलीज़ की तारीख एक होती है, लेकिन उसमें कई अभिनेता हो सकते हैं.isSortable: अगर प्रॉपर्टी का इस्तेमाल सॉर्ट करने के लिए किया जा सकता है, तो इसेtrueपर सेट करें. अगरisRepeatableकोtrueपर सेट किया गया है या प्रॉपर्टी, दोहराए जा सकने वाले सब-ऑब्जेक्ट में मौजूद है, तो इसेtrueपर सेट नहीं किया जा सकता.isFacetable: अगर प्रॉपर्टी का इस्तेमाल फ़ैसेट (सर्च के नतीजों को बेहतर बनाने के लिए इस्तेमाल किए जाने वाले एट्रिब्यूट) जनरेट करने के लिए किया जा सकता है, तो इसेtrueपर सेट करें.- इसके लिए,
isReturnableकोtrueपर सेट करना ज़रूरी है. - फ़िलहाल, इस सुविधा का इस्तेमाल सिर्फ़ enum, बूलियन, और टेक्स्ट प्रॉपर्टी के लिए किया जा सकता है.
- इसके लिए,
isWildcardSearchable: अगर उपयोगकर्ताओं को इस प्रॉपर्टी पर वाइल्डकार्ड खोज करने की अनुमति देनी है, तो इसेtrueपर सेट करें. यह विकल्प सिर्फ़ टेक्स्ट प्रॉपर्टी पर उपलब्ध है. इसका व्यवहार,exactMatchWithOperatorसेटिंग पर निर्भर करता है:- अगर
exactMatchWithOperatorकोtrueपर सेट किया गया है, तो टेक्स्ट वैल्यू को एक टोकन के तौर पर माना जाता है.science-*जैसी क्वेरी,science-fictionवैल्यू से मैच करती है. - अगर
exactMatchWithOperatorकोfalseपर सेट किया गया है, तो टेक्स्ट वैल्यू को टोकन में बांटा जाता है.sci*याfi*जैसी क्वेरी,science-fictionसे मैच करती हैं, लेकिनscience-*मैच नहीं करती.
- अगर
टाइप तय करना
सही प्रॉपर्टी के विकल्पों वाला ऑब्जेक्ट तय करके, डेटा टाइप सेट करें. जैसे, textPropertyOptions. अगर आपको सभी संभावित वैल्यू पता हैं, तो enums (enumPropertyOptions) का इस्तेमाल करें. किसी प्रॉपर्टी का सिर्फ़ एक डेटा टाइप हो सकता है.
ऑपरेटर के विकल्प तय करना
operatorOptions से पता चलता है कि कोई प्रॉपर्टी, सर्च ऑपरेटर के तौर पर कैसे काम करती है.
हर operatorOptions के लिए, operatorName (जैसे, title) की ज़रूरत होती है. यह वह
पैरामीटर है जिसे उपयोगकर्ता क्वेरी में टाइप करते हैं. जैसे, title:titanic. ऐसे नाम इस्तेमाल करें जो आसानी से समझ में आएं
और उन्हें उपयोगकर्ताओं को दिखाएं.
एक ही टाइप की प्रॉपर्टी के लिए, operatorName को शेयर किया जा सकता है. उस नाम का इस्तेमाल करने वाली क्वेरी से, मैच करने वाली सभी प्रॉपर्टी के नतीजे मिलते हैं.
सॉर्ट की जा सकने वाली प्रॉपर्टी में, तुलना करने वाली क्वेरी के लिए lessThanOperatorName और greaterThanOperatorName शामिल हो सकते हैं. टेक्स्ट प्रॉपर्टी, पूरी वैल्यू को एक टोकन के तौर पर मानने के लिए, exactMatchWithOperator का इस्तेमाल कर सकती हैं.
डिसप्ले के विकल्प जोड़ना
ज़रूरी नहीं है कि displayOptions सेक्शन में, displayLabel शामिल हो. यह उपयोगकर्ता के लिए आसान लेबल है, जो खोज के नतीजों में दिखता है.
सुझावों को फ़िल्टर करने वाले ऑपरेटर जोड़ना
suggestionFilteringOperators[] का इस्तेमाल करके, ऐसी प्रॉपर्टी तय करें जो ऑटोकंप्लीट के सुझावों को फ़िल्टर करती है. जैसे, उपयोगकर्ता की पसंदीदा शैली के हिसाब से, फ़िल्मों के सुझावों को फ़िल्टर करना. सुझावों के लिए सिर्फ़ एक फ़िल्टर तय किया जा सकता है.
अपना स्कीमा रजिस्टर करना
अपने डेटा सोर्स के आईडी का इस्तेमाल करके, स्कीमा सेवा के साथ अपना स्कीमा रजिस्टर करें. UpdateSchema का अनुरोध करें:
PUT https://cloudsearch.googleapis.com/v1/indexing/{name=datasources/*}/schema
रजिस्टर किए बिना अपने स्कीमा की जांच करने के लिए, validateOnly: true का इस्तेमाल करें.
अपने डेटा को इंडेक्स करना
रजिस्टर करने के बाद, Index कॉल का इस्तेमाल करके डेटा सोर्स में डेटा भरें. आम तौर पर, इसके लिए कनेक्टर का इस्तेमाल किया जाता है.
इंडेक्स करने के अनुरोध का उदाहरण:
{
"name": "datasource/<data_source_id>/items/titanic",
"metadata": {
"title": "Titanic",
"objectType": "movie"
},
"structuredData": {
"object": {
"properties": [{
"name": "movieTitle",
"textValues": { "values": ["Titanic"] }
}]
}
},
"itemType": "CONTENT_ITEM"
}
अपने स्कीमा की जांच करना
प्रोडक्शन में जाने से पहले, छोटी रिपॉज़िटरी के साथ जांच करें. एक ऐसी एसीएल बनाएं जो नतीजों को सिर्फ़ टेस्ट करने वाले उपयोगकर्ता तक सीमित करे.
- सामान्य क्वेरी: मैच करने वाले सभी आइटम देखने के लिए, कोई स्ट्रिंग खोजें. जैसे, "टाइटेनिक."
- ऑपरेटर क्वेरी: नतीजों को सीमित करने के लिए, किसी ऑपरेटर का इस्तेमाल करें. जैसे,
actor:Zane.
अपने स्कीमा को बेहतर बनाना
उपयोगकर्ता की राय पर नज़र रखें और अपने स्कीमा में बदलाव करें. नए फ़ील्ड को इंडेक्स किया जा सकता है या ऑपरेटर के नाम बदलकर उन्हें ज़्यादा आसानी से समझा जा सकता है.
स्कीमा में बदलाव करने के बाद, फिर से इंडेक्स करना
इनमें बदलाव करने के लिए, फिर से इंडेक्स करने की ज़रूरत नहीं होती:
- ऑपरेटर के नाम.
- संख्या से जुड़ी सीमाएं.
- क्रम के हिसाब से रैंकिंग.
- अपडेट करने या डिसप्ले के विकल्प.
इनके लिए, फिर से इंडेक्स करना ज़रूरी है:
- प्रॉपर्टी या ऑब्जेक्ट जोड़ना या हटाना.
isReturnable,isFacetableयाisSortableकोtrueपर सेट करना.- किसी प्रॉपर्टी को
isSuggestableके तौर पर मार्क करना.
प्रॉपर्टी में किए जाने वाले ऐसे बदलाव जिनकी अनुमति नहीं है
ऐसे बदलाव करने की अनुमति नहीं है जिनसे इंडेक्स टूट जाता है या नतीजे एक जैसे नहीं मिलते. इनमें ये शामिल हैं:
- प्रॉपर्टी का डेटा टाइप या नाम.
exactMatchWithOperatorयाretrievalImportanceसेटिंग.
स्कीमा में कोई मुश्किल बदलाव करना
अगर आपको ऐसा बदलाव करना है जिसकी अनुमति नहीं है, तो प्रॉपर्टी को पुरानी परिभाषा से नई परिभाषा में माइग्रेट करें:
- स्कीमा में, अलग नाम वाली नई प्रॉपर्टी जोड़ें.
- नई और पुरानी, दोनों प्रॉपर्टी के साथ स्कीमा रजिस्टर करें.
- सिर्फ़ नई प्रॉपर्टी का इस्तेमाल करके, इंडेक्स को बैकफ़िल करें.
- स्कीमा से पुरानी प्रॉपर्टी मिटाएं.
- क्वेरी कोड को अपडेट करके, प्रॉपर्टी के नए नाम का इस्तेमाल करें.
Cloud Search, मिटाए गए आइटम को 30 दिनों तक रिकॉर्ड करता है, ताकि उन्हें फिर से इस्तेमाल करने में कोई समस्या न हो.
साइज़ से जुड़ी सीमाएं
- ज़्यादा से ज़्यादा 10 टॉप-लेवल ऑब्जेक्ट.
- ज़्यादा से ज़्यादा 10 लेवल की गहराई.
- हर ऑब्जेक्ट के लिए ज़्यादा से ज़्यादा 1,000 फ़ील्ड. इनमें नेस्ट किए गए फ़ील्ड भी शामिल हैं.
अगले चरण
- एक सर्च इंटरफ़ेस बनाना.
- खोज की क्वालिटी बेहतर बनाना.
- क्वेरी की सही व्याख्या के लिए, स्कीमा को स्ट्रक्चर करना.
- समानार्थी शब्द तय करना.