
Google Cloud Search スキーマは、データのインデックス登録とクエリのオブジェクト、プロパティ、オプションを定義する JSON 構造です。コンテンツ コネクタは、登録されたスキーマを使用してリポジトリ データの構造化とインデックス登録を行います。
スキーマを作成するには、JSON スキーマ オブジェクトを API に提供します。データをインデックスに登録する前に、各リポジトリのスキーマを登録する必要があります。
このドキュメントでは、スキーマ作成の基礎について説明します。検索エクスペリエンスを最適化するには、検索品質の向上をご覧ください。
スキーマの作成
Cloud Search スキーマを作成する手順は次のとおりです。
- 予想されるユーザーの行動を特定する
- データソースを初期化する
- オブジェクトを定義する
- オブジェクトのプロパティを定義する
- スキーマを登録する
- データをインデックスに登録する
- スキーマをテストする
- スキーマを調整する
予想されるユーザーの行動を特定する
ユーザーがどのように検索するかを予測することは、スキーマ戦略の策定に役立ちます。映画データベースの場合、ユーザーは「ロバート レッドフォード出演の映画」を検索する可能性があります。スキーマでは、特定の俳優が出演する映画のクエリをサポートする必要があります。
スキーマをユーザーの行動に合わせるには:
- さまざまなユーザーから要求される多様なクエリを評価します。
- 「映画」などの論理データセット(オブジェクト)を特定します。
- タイトルや公開日などのプロパティ(属性)を特定します。
- 「インディ・ジョーンズ」などのプロパティの有効な値を特定します。
- 時系列順や視聴者評価など、並べ替えとランキングのニーズを特定します。
- 役職などのコンテキスト プロパティを特定して、自動補完候補を改善します。
- これらのオブジェクト、プロパティ、サンプル値をリストします。このリストを使用して、演算子オプションを定義します。
データソースを初期化する
データソースは、Google Cloud に保存されているインデックス登録済みのリポジトリ データを表します。サードパーティのデータソースを管理するをご覧ください。ユーザーが検索結果をクリックすると、Cloud Search はインデックス登録リクエストの URL を使用してアイテムに誘導します。
オブジェクトを定義する
オブジェクトは、スキーマの基本単位です。「映画」や「人物」などの論理構造はオブジェクトです。各オブジェクトには、タイトル、上映時間、名前などのプロパティがあります。
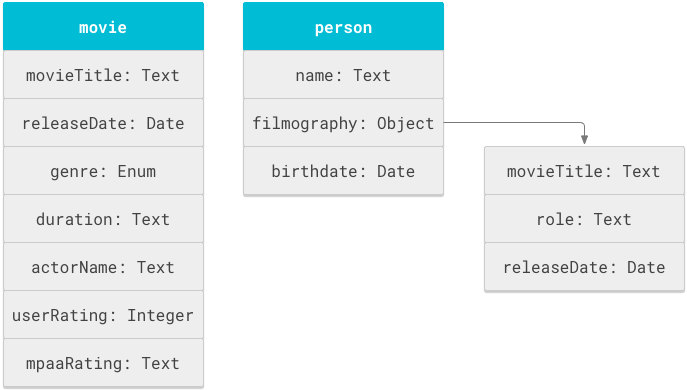
スキーマは、objectDefinitions タグ内のオブジェクト定義のリストです。
{
"objectDefinitions": [
{ "name": "movie" },
{ "name": "person" }
]
}
各オブジェクトに一意の名前(movie など)を使用します。スキーマ サービスでは、これらの名前がキーとして使用されます。ObjectDefinition をご覧ください。
オブジェクトのプロパティを定義する
propertyDefinitions セクションで、タイトルや公開日などのプロパティを定義します。freshnessOptions(ランキング)と displayOptions(UI ラベル)には options を使用します。
{
"objectDefinitions": [{
"name": "movie",
"propertyDefinitions": [
{
"name": "movieTitle",
"isReturnable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": { "operatorName": "title" }
},
"displayOptions": { "displayLabel": "Title" }
},
{
"name": "releaseDate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "released",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
}
}
]
}]
}
PropertyDefinition には次のものが含まれます。
name文字列。- 型に依存しないオプション(
isReturnableなど)。 - タイプとタイプ固有のオプション(
textPropertyOptionsなど)。 operatorOptions: 検索演算子。- UI ラベルの
displayOptions。
異なるオブジェクト間でプロパティ名を再利用できます。たとえば、movieTitle は movie オブジェクトと person オブジェクトの両方のフィルモグラフィに表示できます。
型に依存しないオプションを追加する
PropertyDefinition には、プロパティの型に関係なく、プロパティの検索機能を構成するブール値オプションが含まれています。これらのオプションはデフォルトで false に設定されています。使用するには true に設定する必要があります。
isReturnable: Query API を使用して検索結果でプロパティ データを返す必要がある場合は、trueに設定します。返せないプロパティは、結果に表示せずに検索やランキングに使用できます。isRepeatable: プロパティに複数の値を指定できる場合は、trueに設定します。たとえば、映画の公開日は 1 つですが、俳優は複数人います。isSortable: プロパティを並べ替えに使用できる場合は、trueに設定します。isRepeatableがtrueの場合、またはプロパティが繰り返し可能なサブオブジェクト内にある場合は、trueにすることはできません。isFacetable: プロパティをファセット(検索結果の絞り込みに使用される属性)の生成に使用できる場合は、trueに設定します。isReturnableがtrueである必要があります。- 列挙型、ブール型、テキスト型のプロパティでのみサポートされます。
isWildcardSearchable: ユーザーがこのプロパティでワイルドカード検索を実行できるようにするには、trueに設定します。このオプションはテキスト プロパティでのみ使用でき、その動作はexactMatchWithOperatorの設定によって異なります。exactMatchWithOperatorがtrueの場合: テキスト値は単一のトークンとして扱われます。science-*のようなクエリは、値science-fictionと一致します。exactMatchWithOperatorがfalseの場合: テキスト値がトークン化されます。sci*やfi*などのクエリはscience-fictionと一致しますが、science-*は一致しません。
型を定義する
適切なプロパティ オプション オブジェクト(textPropertyOptions など)を定義して、データ型を設定します。取り得る値がすべてわかっている場合は、列挙型(enumPropertyOptions)を使用します。プロパティに設定できるデータ型は 1 つのみです。
演算子オプションを定義する
operatorOptions プロパティが検索演算子として機能する方法を説明します。
すべての operatorOptions には operatorName(title など)が必要です。これは、ユーザーがクエリで入力するパラメータ(title:titanic など)です。直感的な名前を使用して、ユーザーに公開します。
同じタイプのプロパティ間で operatorName を共有できます。その名前を使用するクエリは、一致するすべてのプロパティから結果を取得します。
並べ替え可能なプロパティには、比較クエリの lessThanOperatorName と greaterThanOperatorName を含めることができます。テキスト プロパティでは、exactMatchWithOperator を使用して値全体を単一のトークンとして扱うことができます。
表示オプションを追加する
省略可能な displayOptions セクションには displayLabel が含まれます。これは、検索結果に表示されるユーザー向けのわかりやすいラベルです。
候補のフィルタリング演算子を追加する
suggestionFilteringOperators[] を使用して、オートコンプリート候補をフィルタするプロパティを定義します(例: ユーザーの好みのジャンルで映画の候補をフィルタする)。提案フィルタは 1 つしか定義できません。
スキーマを登録する
データソース ID を使用して、スキーマ サービスにスキーマを登録します。UpdateSchema リクエストを発行します。
PUT https://cloudsearch.googleapis.com/v1/indexing/{name=datasources/*}/schema
validateOnly: true を使用すると、スキーマを登録せずにテストできます。
データをインデックスに登録する
登録後、通常はコネクタを使用して、インデックス呼び出しでデータソースにインデックスを挿入します。
インデックス登録リクエストの例:
{
"name": "datasource/<data_source_id>/items/titanic",
"metadata": {
"title": "Titanic",
"objectType": "movie"
},
"structuredData": {
"object": {
"properties": [{
"name": "movieTitle",
"textValues": { "values": ["Titanic"] }
}]
}
},
"itemType": "CONTENT_ITEM"
}
スキーマをテストする
本番環境の前に、小さなリポジトリでテストします。結果をテストユーザーに制限する ACL を作成します。
- 一般的な検索語句: 文字列(「titanic」など)を検索して、一致するすべてのアイテムを表示します。
- 演算子クエリ: 演算子(
actor:Zaneなど)を使用して結果を絞り込みます。
スキーマを調整する
ユーザーのフィードバックをモニタリングし、スキーマを調整します。新しいフィールドのインデックス登録や、より直感的な演算子の名前変更を行うことができます。
スキーマ変更後に再インデックス登録する
次の変更については、インデックスを再作成する必要はありません。
- 演算子名。
- 数値の上限。
- 順序付きランキング。
- 更新頻度または表示オプション。
次の場合は、インデックスを再作成する必要があります。
- プロパティまたはオブジェクトの追加または削除。
isReturnable、isFacetable、isSortableをtrueに変更します。- プロパティを
isSuggestableとしてマークします。
禁止されているプロパティ変更
インデックスを破損したり、結果の不整合を引き起こしたりする変更は禁止されています。たとえば、次のような変更です。
- プロパティのデータ型または名前。
exactMatchWithOperatorまたはretrievalImportanceの設定。
複雑なスキーマ変更を行う
許可されていない変更を行うには、古い定義から新しい定義にプロパティを移行します。
- スキーマに別の名前の新しいプロパティを追加します。
- 新しいプロパティと古いプロパティの両方を含むスキーマを登録します。
- 新しいプロパティのみを使用してインデックスをバックフィルします。
- スキーマから古いプロパティを削除します。
- 新しいプロパティ名を使用するようにクエリコードを更新します。
Cloud Search では、再利用の問題を防ぐため、削除されたアイテムのレコードが 30 日間保持されます。
サイズの制限
- 最上位のオブジェクトは最大 10 個。
- 最大深度は 10 レベルです。
- オブジェクトあたりの最大フィールド数: 1,000(ネストされたフィールドを含む)。
次のステップ
- 検索インターフェースを作成します。
- 検索品質の向上。
- 最適なクエリ解釈のためのスキーマを構築します。
- 類義語を定義する。