我们的先进 AI 模型:让你利器在握、成竹在胸
Learn about our leading AI models
探索最具影响力的 Google 创新成果背后依托的 AI 模型,了解这些模型的功能,并在准备就绪后找到合适的模型,轻松打造你自己的 AI 项目。
Discover the AI models behind our most impactful innovations, understand their capabilities, and find the right one when you're ready to build your own AI project.
展开
Show more
收起
Show less
-
Gemini 模型Gemini models 开发者随时可用Ready for developers 多模态Multimodal 文本生成Text generation 代码生成Code generation
Gemini 1.0 Ultra
Gemini 1.0 Ultra
Google 旗下最大的模型,用于处理非常复杂的任务。
Our largest model for highly complex tasks.
了解详情 Learn more无论是理解自然图像、音频和视频,还是推理复杂数学,这款模型都驾轻就熟。LLM 研发领域广泛采用 32 项学术和多模态基准测试,其中 30 项测试都见证了这款模型的出类拔萃。
From natural image, audio, and video understanding to mathematical reasoning, performance exceeds current state-of-the-art results on 30 of the 32 widely-used academic and multimodal benchmarks used in large language model research and development.
这是第一款在大规模多任务语言理解测试中超越人类专家的模型。测试涵盖了数学、物理、历史、法律、医学、伦理等 57 个学科,旨在评估对全球各类知识的掌握程度以及解决问题的能力。
The first model to outperform human experts on massive multitask language understanding, which uses 57 subjects such as math, physics, history, law, medicine, ethics, and more for testing both world knowledge and problem solving abilities.
-

Gemini 模型Gemini models 开发者随时可用Ready for developers 多模态Multimodal 文本生成Text generation 代码生成Code generation
Gemini 1.5 Pro
Gemini 1.5 Pro
Google 旗下在各种任务中总体表现最优异的模型。
Our best model for general performance across a wide range of tasks.
了解详情 Learn more能一气呵成地分析、分类并总结给定提示中的大量内容。
Can seamlessly analyze, classify and summarize large amounts of content within a given prompt.
能针对不同模态执行非常复杂的理解和推理任务。
Can perform highly sophisticated understanding and reasoning tasks for different modalities.
遇到包含 >100,000 行代码的提示时,这款模型能更出色地跨示例推理、提供有用的修改建议,并说明代码各个部分的运作方式。
When given a prompt with more than 100,000 lines of code, it can better reason across examples, suggest helpful modifications and give explanations about how different parts of the code works.
-

Gemini 模型Gemini models 开发者随时可用Ready for developers 多模态Multimodal 文本生成Text generation 代码生成Code generation
Gemini 1.0 Pro
Gemini 1.0 Pro
Google 旗下适应性最强的模型,可自如处理多种多样的任务。
Our best model for scaling across a wide range of tasks.
了解详情 Learn more经过调优后,这款模型既可作为编码模型,以巧思生成候选解决方案;也可作为奖励模型,以慧眼识别和提取最有潜力的候选代码。
Fine-tuned both to be a coding model to generate proposal solution candidates, and to be a reward model that is leveraged to recognize and extract the most promising code candidates.
在所有 ASR 和 AST 任务中,无论是英语还是多语言测试集,这款模型的表现都明显优于 USM 和 Whisper 模型。
Significantly outperforms the USM and Whisper models across all ASR and AST tasks, both for English and multilingual test sets.
-

Gemini 模型Gemini models 开发者随时可用Ready for developers 多模态Multimodal 文本生成Text generation 代码生成Code generation
Gemini 1.0 Nano
Gemini 1.0 Nano
Google 旗下适合执行设备端任务的最高效模型。
Our most efficient model for on-device tasks.
了解详情 Learn more这款模型不仅善于处理设备端任务,能轻松完成总结、阅读理解、文本补全等任务,而且在推理、STEM、编码、多模态和多语言任务方面展现了惊人的能力 - 小身材,大能量,不外如此。
Excels at on-device tasks, such as summarization, reading comprehension, text completion tasks, and exhibits impressive capabilities in reasoning, STEM, coding, multimodal, and multilingual tasks relative to their sizes.
Gemini 模型能在更多平台和设备上运行,极大地扩展了适用范围,方便所有人体验它们的各项精彩功能。
With capabilities accessible to a larger set of platforms and devices, the Gemini models expand accessibility to everyone.
-

Gemini 模型Gemini models 开发者随时可用Ready for developers 多模态Multimodal 文本生成Text generation 代码生成Code generation
Gemini 1.5 Flash
Gemini 1.5 Flash
Google 旗下的一款轻量级模型,在速度和效率方面经过专门优化。
Our lightweight model, optimized for speed and efficiency.
了解详情 Learn more对于绝大多数开发者和企业用例,处理首个词元时的平均延迟时间 <1 秒。
Sub-second average first-token latency for the vast majority of developer and enterprise use cases.
对于大多数常见任务,1.5 Flash 能以更低的成本实现与更大的模型相媲美的质量。
On most common tasks, 1.5 Flash achieves comparable quality to larger models, at a fraction of the cost.
能处理持续数小时的视频和音频,以及数十万的单词或代码行。
Process hours of video and audio, and hundreds of thousands of words or lines of code.
-

开发者随时可用Ready for developers 文本生成Text generation 代码生成Code generation
PaLM 2
PaLM 2
一款先进的语言模型,具备更强的多语言、推理和编码能力。
A state-of-the-art language model with improved multilingual, reasoning and coding capabilities.
了解详情 Learn more能展现更强的逻辑、常识推理和数学能力。
Demonstrates improved capabilities in logic, common sense reasoning, and mathematics.
具有更强的语言理解、生成和翻译能力,即使面对精妙的习语、诗歌和谜语,也能轻松拿捏。PaLM 2 还参加了高级语言水平考试,并取得了“精通”级别的优秀成绩,堪称语言大师。
Improved its ability to understand, generate and translate nuanced text - including idioms, poems and riddles. PaLM 2 also passes advanced language proficiency exams at the “mastery” level.
既精通 Python 和 JavaScript 等流行编程语言,也能轻松使用 Prolog、Fortran 和 Verilog 等语言生成专用代码。
Excels at popular programming languages like Python and JavaScript, but is also capable of generating specialized code in languages like Prolog, Fortran, and Verilog.
-

开发者随时可用Ready for developers 图像生成Image generation
Imagen
Imagen
一系列用于文本转图像的模型,既能生成超乎想象的逼真画质,也具备深厚的语言理解功底。
A family of text-to-image models with an unprecedented degree of photorealism and a deep level of language understanding.
了解详情 Learn more凭借经过改进的图像+文本理解力,再结合各种新颖的训练和建模方法,可实现准确、优质、逼真的输出。
Achieves accurate, high-quality photorealistic outputs with improved image+text understanding and a variety of novel training and modeling techniques.
文本转图像模型通常很难准确在图中渲染文本。Imagen 3 改进了幕后流程,确保能在生成的图像中正确显示字词或短语。
Text-to-image models often struggle to include text accurately. Imagen 3 improves this process, ensuring the correct words or phrases appear in the generated images.
Imagen 3 能理解以自然的日常语言编写的提示,无需复杂的提示工程即可生成预期的输出。
Imagen 3 understands prompts written in natural, everyday language, making it easier to get the output you want without complex prompt engineering.
内置了安全防范措施,可帮助确保生成的图像符合 Google 的 Responsible AI 原则。
Includes built-in safety precautions to help ensure that generated images align with Google's Responsible AI principles.
-
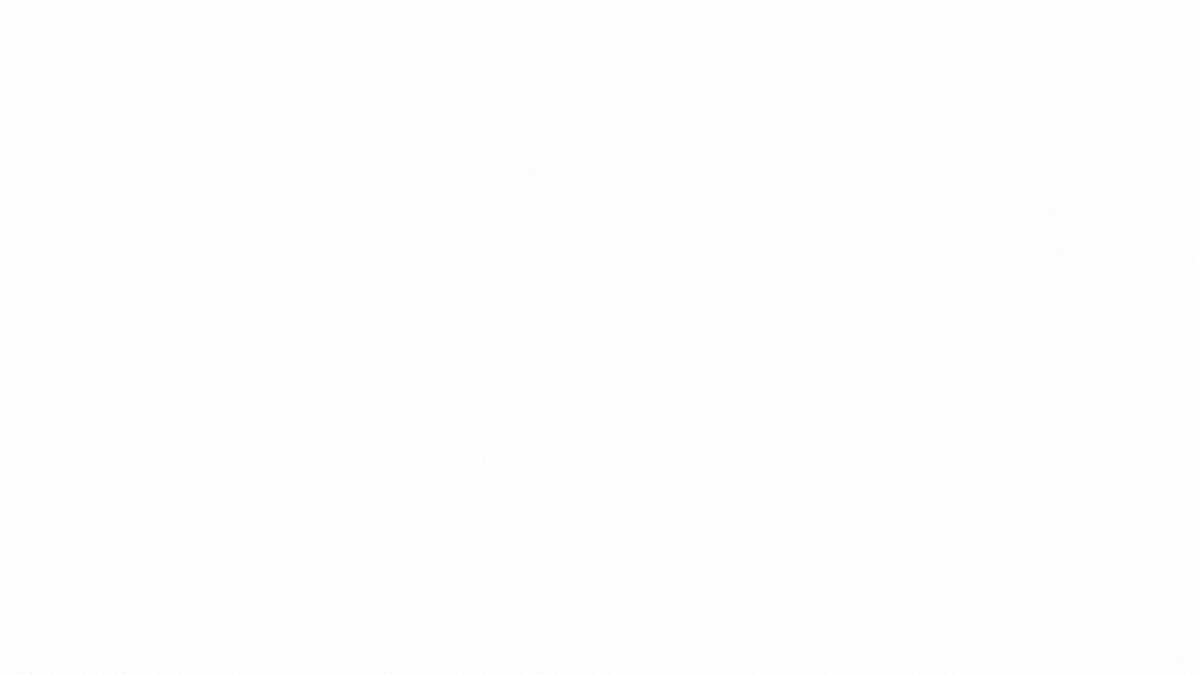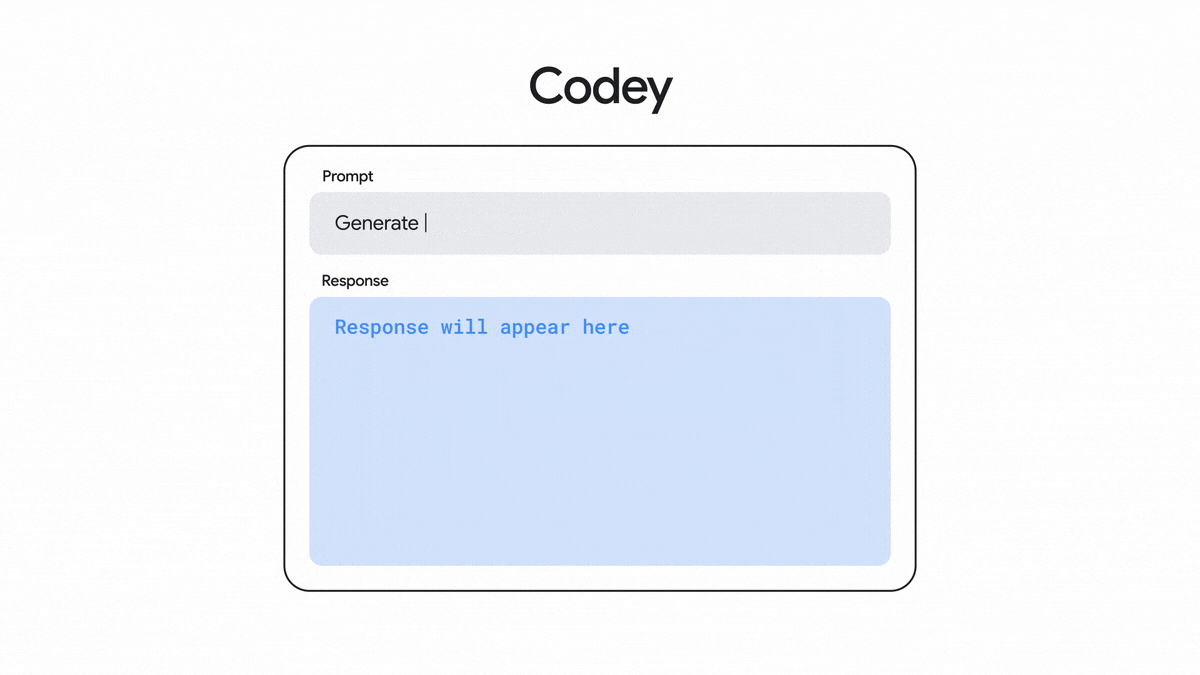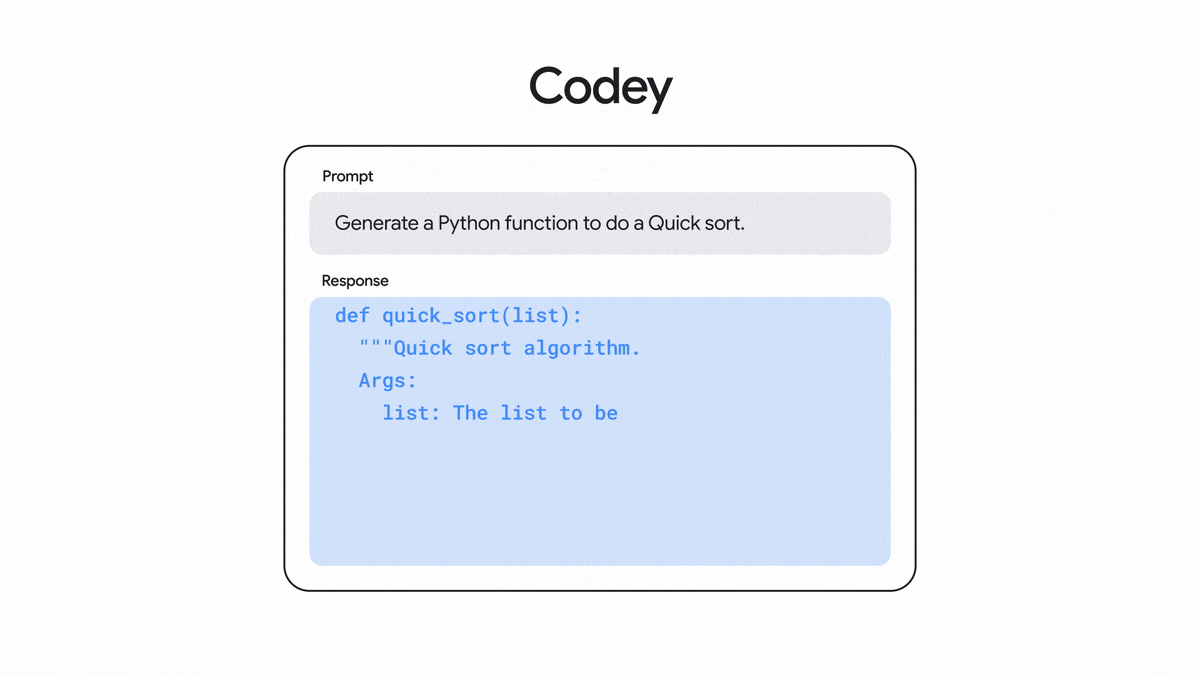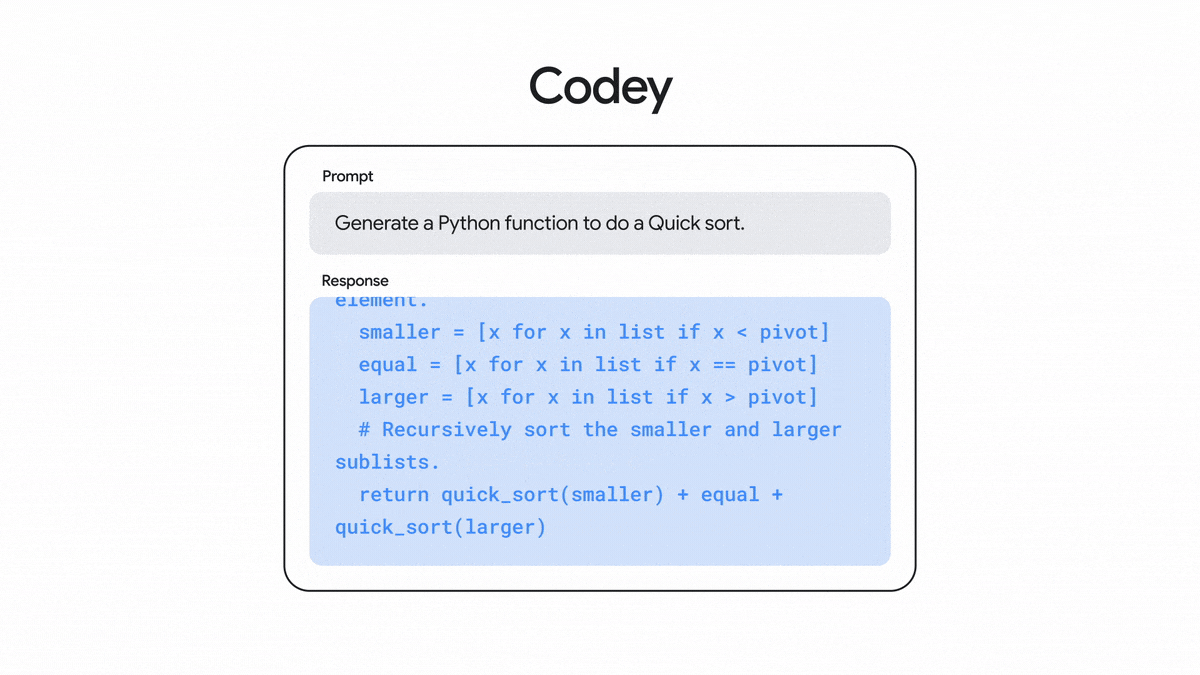
开发者随时可用Ready for developers 代码生成Code generation
Codey
Codey
一系列可根据一段自然语言说明来生成代码的模型,适用于创建函数、网页、单元测试和其他类型的代码。
A family of models that generate code based on a natural language description. It can be used to create functions, web pages, unit tests, and other types of code.
了解详情 Learn more根据代码的现有上下文,建议怎么续写接下来的几行代码。
Suggests the next few lines based on the existing context of code.
根据开发者提供的自然语言提示,生成所需代码。
Generates code based on natural language prompts from a developer.
让开发者能通过对话向 AI 机器人求助,以便调试代码、查阅文档、学习新概念以及解决其他的代码相关问题。
Lets developers converse with a bot to get help with debugging, documentation, learning new concepts, and other code-related questions.
-
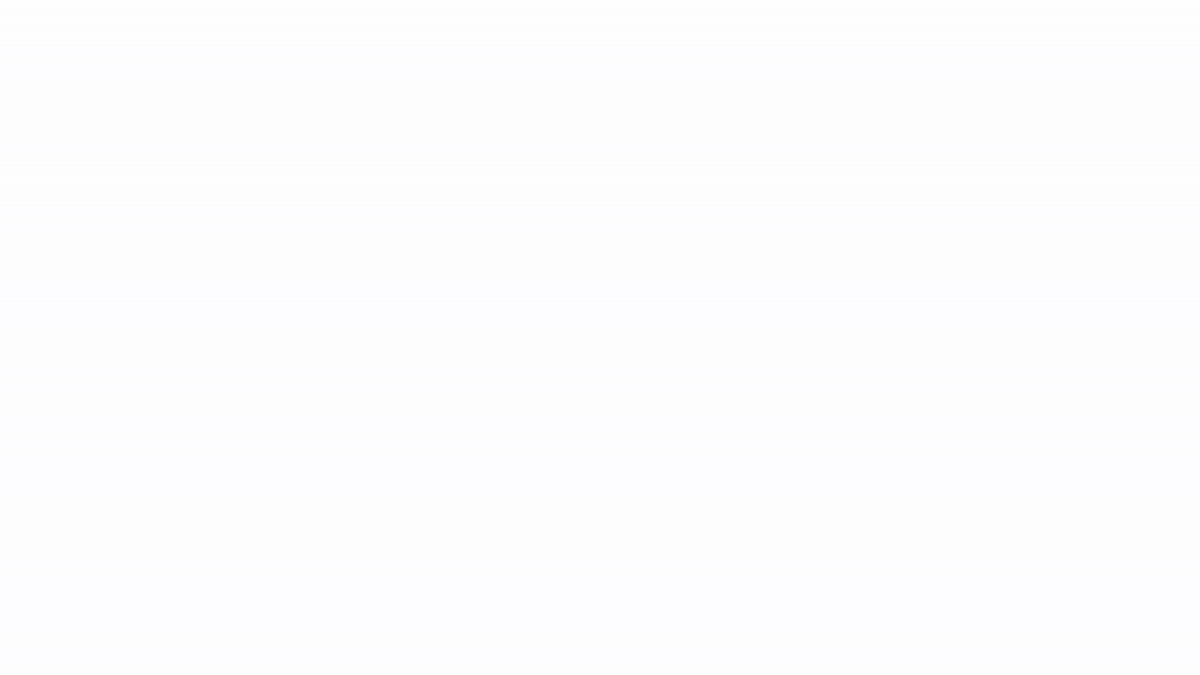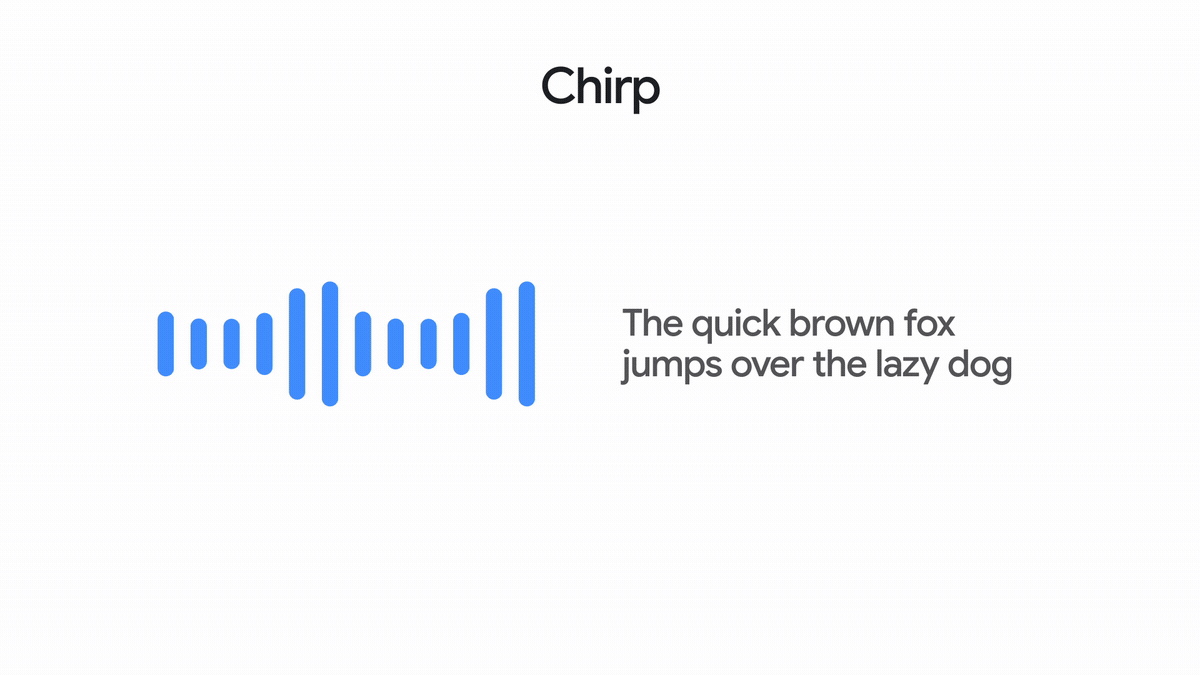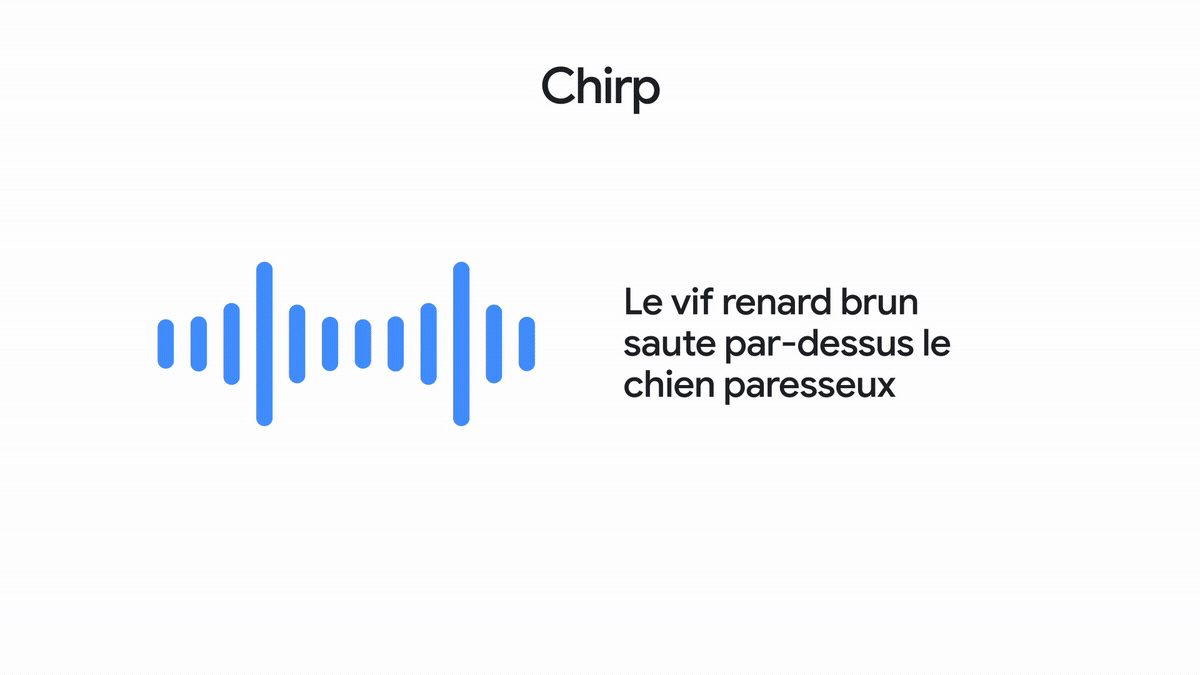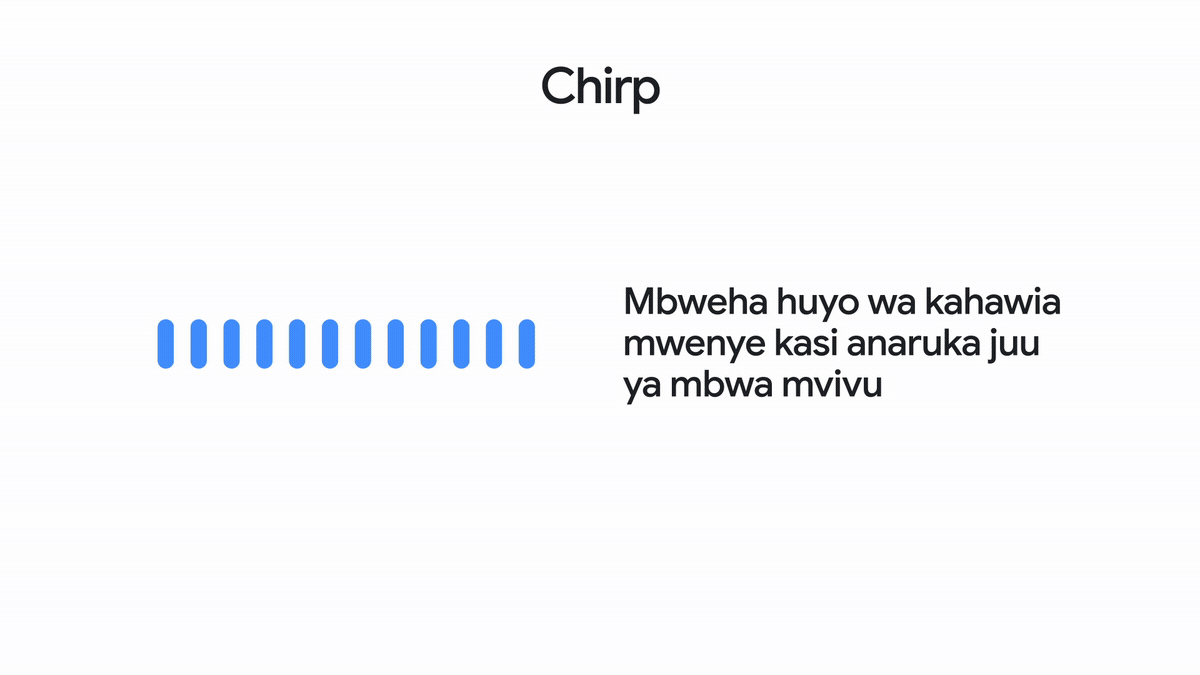
开发者随时可用Ready for developers 文本生成Text generation
Chirp
Chirp
一系列通用语音模型,基于 1,200 万小时的语音数据训练,支持对 100+ 种语言进行自动语音识别 (ASR)。
A family of universal Speech Models trained on 12 million hours of speech to enable automatic speech recognition (ASR) for 100+ languages.
了解详情 Learn more能凭借出色的语音识别能力转写 100+ 种语言的语音内容。
Can transcribe in over 100 languages with excellent speech recognition.
处理各种公开测试集和语言时,可将字词错误率 (WER) 控制在极低的水平。对于英语,语音识别准确率高达 98%;对于使用人数 <1,000 万的若干小语种,语音识别准确率也实现了 >300% 的相对提升。
Achieves state-of-the-art Word Error Rate (WER) on a variety of public test sets and languages. It delivers 98% speech recognition accuracy in English and over 300% relative improvement in several languages with less than 10M speakers.
Chirp 模型内含 20 亿参数,在规模上远超以往的语音模型,在性能上也更胜从前。
Chirp's 2-billion-parameter model outpaces previous speech models to deliver superior performance.
-

视频生成Video generation
Veo
Veo
Google 旗下最强的生成式视频模型。借助这款工具,探索视频生成技术的全新应用方式,尽情释放创意!
Our most capable generative video model. A tool to explore new applications and creative possibilities with video generation.
了解详情 Learn more只需输入文本提示,即可生成 >60 秒的 1080P 高画质视频。只要给出提示,就能操控镜头实现心中所想,比如延时摄影或壮观航拍。
With just text prompts, it creates high-quality, 1080P videos that can go beyond 60 seconds. Lets you control the camera, and prompt for things like time lapse or aerial shots of a landscape.
精准理解提示语气,生动呈现直观画面。从肢体语言的微妙暗示,到灯光和色彩选择变化,都能显著改变生成的视频效果。
Interprets and visualizes the tone of prompts. Subtle cues in body language, lighting, and even color choices could dramatically shift the look of a generated video.
即使是长视频,也能确保多个场景在外观、位置和风格方面稳定如一。
Able to retain visual consistency in appearance, locations and style across multiple scenes in a longer video.
Veo 使视频编辑化繁为简!用户只需给出提示,即可轻松修改、添加或替换各种视觉元素。更神奇的是,Veo 还能根据用户提供的图像生成视频,让图像融入视频的任意一帧,用户只需编辑提示,即可让视频按照所想呈现想要的效果。
Veo allows users to edit videos through prompts, including modifying, adding or replacing visual elements and it can generate a video from an image input, using the image to fit within any frame of the output and the prompt as guidance for how the video should proceed.
-

行业专用Industry-specific 开发者随时可用Ready for developers 文本生成Text generation
MedLM
MedLM
一系列专为医疗保健行业量身调优的模型。
A family of models fine-tuned for the healthcare industry.
了解详情 Learn more革新医疗信息的获取、分析和应用方式。减轻行政负担,助力实现信息无缝整合。
Revolutionizes the way medical information is accessed, analyzed, and applied. Reduces administrative burdens and helps synthesize information seamlessly.
MedLM 是一种支持定制的解决方案,可嵌入医疗保健工作流程中并与相关数据集成,从而提升医疗保健服务能力。
MedLM is a customizable solution that can embed into your workflow and integrate with your data to augment your healthcare capabilities.
MedLM 秉持"技人联合,安全创新"的理念,通过融合技术与医学专家的优势,助你始终立于行业前沿。
Born from a belief that together, technology and medical experts can innovate safely, MedLM helps you stay on the cutting edge.
-

行业专用Industry-specific 文本生成Text generation
LearnLM
LearnLM
一系列专为促进学习而调优的模型,蕴含诸多教师指导与教学评估功能。
A family of models fine-tuned for learning, infused with teacher-advised education capabilities and pedagogical evaluations.
了解详情 Learn more及时反馈,鼓励学习者加强练习并参加有益挑战。
Allow for practice and healthy struggle with timely feedback.
以多种形式呈现结构清晰的相关信息。
Present relevant, well-structured information in multiple modalities.
围绕目标和需求灵活调整教学策略,且有据可依。
Dynamically adjust to goals and needs, grounding in relevant materials.
点燃求知热情,为学习之旅注入强劲动力。
Inspire engagement to provide motivation through the learning journey.
帮助学习者规划、监控并反思学习进展。
Plan, monitor and help the learner reflect on progress.
-

行业专用Industry-specific 文本生成Text generation
SecLM
SecLM
一系列专为保障网络安全而调优的模型。
A family of models fine-tuned for cybersecurity.
了解详情 Learn more在 Google、VirusTotal 和 Mandiant 的威胁情报基础上训练和调优,可为用户提供最新的安全信息和情境分析。
Tuned, trained and grounded in threat intelligence from Google, VirusTotal, and Mandiant to bring up-to-date security information and context to users.
Gemini in Security 智能体可利用 SecLM 助力防御方守护组织安全。
Gemini in Security agents use SecLM to help defenders protect their organizations.
无论是解析复杂信息,还是执行专业化任务和工作流程,都可为网络安全专业人员分忧代劳。
Cybersecurity professionals can easily make sense of complex information and perform specialized tasks and workflows.
-

开放模型Open models 开发者随时可用Ready for developers 文本生成Text generation
Gemma
Gemma
一系列先进的轻量级开放模型,基于 Gemini 模型所用的研发技术打造。
A family of lightweight, state-of-the-art open models from Google, built from the same research and technology used to create the Gemini models.
了解详情 Learn more这些模型整合了全方位的安全措施,采用精选数据集并经过严谨调优,旨在助力打造负责任、值得信赖的 AI 解决方案。
Incorporating comprehensive safety measures, these models help ensure responsible and trustworthy AI solutions through curated datasets and rigorous tuning.
即使只有 20 亿或 70 亿参数,Gemma 模型也能在基准测试中取得优异成绩,甚至超越了一些更大的开放模型。
Gemma models achieve exceptional benchmark results at its 2B and 7B sizes, even outperforming some larger open models.
Gemma 支持 Keras 3.0,与 JAX、TensorFlow 和 PyTorch 无缝兼容,让用户能根据任务需求轻松选择并切换框架。
With Keras 3.0, enjoy seamless compatibility with JAX, TensorFlow, and PyTorch, empowering you to effortlessly choose and switch frameworks depending on your task.
-

开放模型Open models 开发者随时可用Ready for developers 代码生成Code generation
CodeGemma
CodeGemma
一系列基于 Gemma 构建的轻量级开放编码模型。CodeGemma 模型可执行各种任务,比如代码补全、代码生成、代码对话和指令遵循。
A collection of lightweight open code models built on top of Gemma. CodeGemma models perform a variety of tasks like code completion, code generation, code chat, and instruction following.
了解详情 Learn more无论是在本地开发,还是使用 Google Cloud 资源,CodeGemma 都能帮助补全代码、构建函数,甚至生成完整的代码块。
Complete lines, functions, and even generate entire blocks of code, whether you're working locally or using Google Cloud resources.
基于来自网络文档、数学和代码的 5,000 亿个词元训练,能生成语法正确且语义明确的代码,有效减少错误并缩短调试用时。
Trained on 500 billion tokens data from web documents, mathematics, and code. Generates code that's not only more syntactically correct but also semantically meaningful, reducing errors and debugging time.
支持 Python、JavaScript、Java、Kotlin、C++、C#、Rust、Go 等语言。
Supports Python, JavaScript, Java, Kotlin, C++, C#, Rust, Go, and other languages.
-

开放模型Open models 开发者随时可用Ready for developers 文本生成Text generation
RecurrentGemma
RecurrentGemma
这是一款具有技术特色的模型,采用循环神经网络和局部注意力机制,可有效提升内存效率。
A technically distinct model that leverages recurrent neural networks and local attention to improve memory efficiency.
了解详情 Learn more内存需求降低,即便是在内存有限的(比如单 GPU 或单 CPU)设备上,也能生成更长的样例。
Lower memory requirements allow for the generation of longer samples on devices with limited memory, such as single GPUs or CPUs.
支持以更大的批次规模进行推理,每秒可生成更多词元(在生成长序列时表现更出色)。
Can perform inference at significantly higher batch sizes, thus generating substantially more tokens per second (especially when generating long sequences).
不是 Transformer 模型,但得益于深度学习研究的不断进步,性能依然卓越。
Showcases a non-transformer model that achieves high performance, highlighting advancements in deep learning research.
-

开放模型Open models 开发者随时可用Ready for developers 多模态Multimodal 文本生成Text generation
PaliGemma
PaliGemma
Google 旗下的首个多模态 Gemma 模型,能在各种视觉语言任务中实现行业领先的调优性能。
Our first multimodal Gemma model, designed for class-leading fine-tune performance across diverse vision-language tasks.
了解详情 Learn more这款模型专为实现行业领先的调优性能而设计,可轻松处理各种视觉语言任务,例如:
Designed for class-leading fine-tune performance on a wide range of vision-language tasks like:
- 为图像和短视频生成字幕
- image and short video captioning
- 视觉问答
- visual question answering
- 理解图像中的文本
- understanding text in images
- 对象检测
- object detection
- 以及对象分割
- and object segmentation
支持诸多语言。
Supports a wide range of languages.
了解 AI 能如何帮助你…
See how AI can help you…
提升创意能力
Be more creative
提高工作效率
Get more done
使用 Gemini 汲取灵感、提升效率。
Supercharge your creativity and productivity with Gemini.
与 Gemini 对话
Chat with Gemini
巧用 Gemini for Google Workspace,让绝佳创意成真。
Bring your best ideas to life with Gemini for Google Workspace.
试用 Gemini for Workspace
Try Gemini for Workspace
这款研究兼写作工具可基于用户输入的信息,指点思路、激发创意。
Do your best thinking with a research and writing tool, grounded in the information you give it.
试用 NotebookLM
Try NotebookLM

*SynthID 可在我们的模型生成的文本、图像、音频和视频内容中嵌入不易察觉的水印,借此帮助标识 AI 生成的内容。
*SynthID helps identify AI-generated content by embedding an imperceptible watermark on text, images, audio, and video content generated by our models.
AI 正在以令人耳目一新的方式帮助我们履行使命,但这项新兴技术刚刚崭露头角,在演变过程中难免会带来新挑战和新问题。
AI is helping us deliver on our mission in exciting new ways, yet it's still an emerging technology that surfaces new challenges and questions as it evolves.
对我们来说,负责任地构建 AI 意味着既要解决这些挑战和问题,又要让 AI 最大限度地造福人类和社会。为了顺应如此复杂的环境,我们坚持秉承我们的 AI 原则,遵循前沿研究的指引,同时持续听取专家、用户及合作伙伴的反馈。
To us, building AI responsibly means both addressing these challenges and questions while maximizing the benefits for people and society. In navigating this complexity, we're guided by our AI Principles and cutting-edge research, along with feedback from experts, users, and partners.
得益于这些措施,我们可利用新的开发成果(例如 AI 辅助的红队测试)不断改进我们的模型,并凭借 SynthID 等技术防止这些成果遭到滥用。有了这些措施的助力,我们在应对社会面临的一些紧迫问题方面也取得了突破性进展,例如预测洪水以及加快研究被忽视的疾病。
These efforts are helping us continually improve our models with new advances like AI-assisted redteaming and prevent their misuse with technologies like SynthID. They are also unlocking exciting, real-world progress towards some of society's most pressing challenges like predicting floods and accelerating research on neglected diseases.