Responsible AI 实践:全盘兼顾、全面推进
Responsible AI practices
AI 的发展为改善全球人民生活创造了新机遇,惠及商业、医疗、教育等各个领域。同时,这也引发了新思考:如何才能最有效地将公平性、可解释性、隐私性和安全性融入相关系统?
The development of AI has created new opportunities to improve the lives of people around the world, from business to healthcare to education. It has also raised new questions about the best way to build fairness, interpretability, privacy, and safety into these systems.
AI 通用推荐做法
General recommended practices for AI
设计 AI 系统时,不仅应始终遵循软件系统方面的通用最佳实践,还应斟酌机器学习所特有的若干考量因素。
While general best practices for software systems should always be followed when designing AI systems, there are also a number of considerations unique to machine learning.
推荐做法
Recommended practices
若要评估系统在预测、推荐和决策方面的真实影响力,实际用户所获得的系统体验是关键。
The way actual users experience your system is essential to assessing the true impact of its predictions, recommendations, and decisions.
- 设计功能时内置适宜的披露信息:知情权和控制权对良好的用户体验至关重要。
- Design features with appropriate disclosures built-in: clarity and control is crucial to a good user experience.
- 酌情扩展辅助:如果一个答案就很可能满足各种各样的用户和用例的需求,那么提供单一答案是可行的。但在其他情况下,最好能向用户提供多个建议选项。从技术层面来说,在单个答案上达到良好的精确度(P@1)比通过多个答案上达到精确(例如 P@3)要困难得多。
- Consider augmentation and assistance: producing a single answer can be appropriate where there is a high probability that the answer satisfies a diversity of users and use cases. In other cases, it may be optimal for your system to suggest a few options to the user. Technically, it is much more difficult to achieve good precision at one answer (P@1) versus precision at a few answers (e.g., P@3).
- 在设计过程初期预判可能会出现的负面反馈,然后针对少许流量进行特定的实时测试和迭代,最后再全面部署。
- Model potential adverse feedback early in the design process, followed by specific live testing and iteration for a small fraction of traffic before full deployment.
- 在项目开发之前和期间,积极纳入各种各样的用户和用例场景,并持续收集反馈,不断优化产品体验。这样可将丰富多样的用户意见融入项目中,使开发的技术能造福更多人。
- Engage with a diverse set of users and use-case scenarios, and incorporate feedback before and throughout project development. This will build a rich variety of user perspectives into the project and increase the number of people who benefit from the technology.
使用多项指标,而不局限于单一指标,才能更好地理解如何权衡不同类型的错误和体验。
The use of several metrics rather than a single one will help you to understand tradeoffs between different kinds of errors and experiences.
- 考虑多种评估指标,包括用户调查问卷中的反馈、跟踪整体系统性能的量化指标、跟踪短期和长期产品健康状况的量化指标(例如短期-点击率,长期-客户生命周期价值),以及针对不同用户群体分析的假正例率和假负例率。
- Consider metrics including feedback from user surveys, quantities that track overall system performance and short- and long-term product heath (e.g., click-through rate and customer lifetime value, respectively), and false positive and false negative rates sliced across different subgroups.
- 确保所用指标契合系统的情境和目标。例如,火灾警报系统应达到高召回率,即使偶尔误报也无妨。
- Ensure that your metrics are appropriate for the context and goals of your system, e.g., a fire alarm system should have high recall, even if that means the occasional false alarm.
机器学习模型会反映所用训练数据的特点,因此你应仔细分析原始数据,确保对它了如指掌。万一无法这样做,例如当原始数据比较敏感时,你可在尊重隐私权的前提下尽可能(比如通过计算匿名聚合数据)了解相关输入数据。
ML models will reflect the data they are trained on, so analyze your raw data carefully to ensure you understand it. In cases where this is not possible, e.g., with sensitive raw data, understand your input data as much as possible while respecting privacy; for example by computing aggregate, anonymized summaries.
- 数据是否包含任何错误(例如值缺失、标签有误)?
- Does your data contain any mistakes (e.g., missing values, incorrect labels)?
- 你的训练数据采样方式能否代表目标用户(例如,原本希望覆盖所有年龄段的用户,但训练数据只涉及老年人)?能否代表预期现实环境(例如,原本希望覆盖全年,但训练数据只涉及夏季)?数据是否准确?
- Is your data sampled in a way that represents your users (e.g., will be used for all ages, but you only have training data from senior citizens) and the real-world setting (e.g., will be used year-round, but you only have training data from the summer)? Is the data accurate?
- 训练-应用偏差(即训练期间与应用期间的性能差距)始终是个难题。在训练期间,应设法识别并努力消除潜在偏差,比如通过调整训练数据或目标函数。在评估期间,应继续尝试获取能最大限度代表目标环境的评估数据。
- Training-serving skew-the difference between performance during training and performance during serving-is a persistent challenge. During training, try to identify potential skews and work to address them, including by adjusting your training data or objective function. During evaluation, continue to try to get evaluation data that is as representative as possible of the deployed setting.
- 模型中是否有任何冗余或不必要的特征?只要能实现性能目标,模型越简单越好。
- Are any features in your model redundant or unnecessary? Use the simplest model that meets your performance goals.
- 对于受监督系统,要考虑现有的数据标签与尝试预测的标签之间的关系。如果用数据标签 X 作为替代项来预测标签 Y,在什么情况下 X 和 Y 之间的差异会造成问题呢?
- For supervised systems, consider the relationship between the data labels you have, and the items you are trying to predict. If you are using a data label X as a proxy to predict a label Y, in which cases is the gap between X and Y problematic?
- 数据偏见也是一个重要的考量因素,详见 AI 和公平性相关实践。
- Data bias is another important consideration; learn more in practices on AI and fairness.
- 如果某个模型的训练目的是检测相关性,那就不该将它用于推断因果关系,也不该暗示它有这种能力。例如,模型可能会发现,买篮球鞋的人普遍个头较高,但这并不意味着,用户只要买了篮球鞋就一定会变高。
- A model trained to detect correlations should not be used to make causal inferences, or imply that it can. E.g., your model may learn that people who buy basketball shoes are taller on average, but this does not mean that a user who buys basketball shoes will become taller as a result.
- 如今的机器学习模型可在很大程度上反映所用训练数据中蕴含的规律。因此,务必阐明相应训练数据的范围和覆盖面,以便用户了解模型的能力和局限。例如,基于图库照片训练的鞋子检测器在处理图库照片时表现最佳,但如果换成用户手机中的照片进行测试,该检测器的表现会有失水准。
- Machine learning models today are largely a reflection of the patterns of their training data. It is therefore important to communicate the scope and coverage of the training, hence clarifying the capability and limitations of the models. E.g., a shoe detector trained with stock photos can work best with stock photos but has limited capability when tested with user-generated cellphone photos.
- 尽可能向用户说明模型的局限。例如,一款利用 ML 技术识别鸟类的应用可向用户说明,它的模型训练数据是来自世界某一特定区域的少量鸟类照片。当你提供更多相关信息之后,用户便能更全面地了解功能或应用,并给出更有价值的反馈。
- Communicate limitations to users where possible. For example, an app that uses ML to recognize specific bird species might communicate that the model was trained on a small set of images from a specific region of the world. By better educating the user, you may also improve the feedback provided from users about your feature or application.
借鉴软件工程最佳测试实践和质量工程技术,确保 AI 系统能按预期运行且值得信赖。
Learn from software engineering best test practices and quality engineering to make sure the AI system is working as intended and can be trusted.
- 执行严格的单元测试,让系统中的每个组件都接受单独测试。
- Conduct rigorous unit tests to test each component of the system in isolation.
- 执行集成测试,了解各个机器学习组件如何与整个系统的其他部分交互。
- Conduct integration tests to understand how individual ML components interact with other parts of the overall system.
- 主动检测输入偏移,通过测试 AI 系统的输入统计信息,确保输入未发生意外变化。
- Proactively detect input drift by testing the statistics of the inputs to the AI system to make sure they are not changing in unexpected ways.
- 使用黄金标准数据集来测试系统,确保其行为持续符合预期。定期更新该测试集,以契合不断变化的用户和用例,降低模型基于测试集进行训练的可能性。
- Use a gold standard dataset to test the system and ensure that it continues to behave as expected. Update this test set regularly in line with changing users and use cases, and to reduce the likelihood of training on the test set.
- 在开发周期内,执行迭代的用户测试,兼顾不同用户的多样化需求。
- Conduct iterative user testing to incorporate a diverse set of users' needs in the development cycles.
- 践行质量工程领域的波卡纠偏 (poka-yoke) 原则:在系统中内置质量检查机制,确保意外故障无法发生或会触发即刻响应(例如,如果某项重要功能意外缺失,AI 系统将不会输出任何预测结果)。
- Apply the quality engineering principle of poka-yoke: build quality checks into a system, so that unintended failures either cannot happen or trigger an immediate response (e.g., if an important feature is unexpectedly missing, the AI system won't output a prediction).
持续监控可确保模型能将实际表现和用户反馈纳入考量(例如满意度跟踪调查问卷、HEART 框架)。
Continued monitoring will ensure your model takes real-world performance and user feedback (e.g., happiness tracking surveys, HEART framework) into account.
- 问题在所难免:模型几乎注定会不完美,无一例外。所以,应在产品路线图中为解决问题预留时间。
- Issues will occur: any model of the world is imperfect almost by definition. Build time into your product roadmap to allow you to address issues.
- 同时考虑短期解决方案和长期解决方案。简单的修复方法(例如使用屏蔽名单)或许有助于快速解决问题,但从长远来看,未必是最佳解决方案。要在短期的简单修复和长期的习得解决方案之间找到平衡。
- Consider both short- and long-term solutions to issues. A simple fix (e.g., blocklisting) may help to solve a problem quickly, but may not be the optimal solution in the long run. Balance short-term simple fixes with longer-term learned solutions.
- 在更新已部署的模型之前,分析该模型和候选模型之间的差异,以及相应更新会对整体系统质量和用户体验产生的影响。
- Before updating a deployed model, analyze how the candidate and deployed models differ, and how the update will affect the overall system quality and user experience.
工作成果示例
Examples of our work
-
Responsible AI:2022 年及之后的 Google 研究动向
Google Research, 2022 & beyond: Responsible AI
-


数据卡片手册
The Data Cards Playbook
-


Imagen:文本转图像 diffusion 模型
Imagen: Text-to-Image Diffusion Model
-
AI Explorables
AI Explorables
-


提升机器学习对肤色的评估能力
Improving skin tone evaluation in machine learning
-


利用 AI 研究电视角色表征在 12 年间的演变趋势
Using AI to study 12 years of representation in TV
-
AI@ 公告
Announcements from AI@
-


Wordcraft Writer's Workshop
Wordcraft Writer's Workshop
Responsible AI:2022 年及之后的 Google 研究动向
Google Research, 2022 & beyond: Responsible AI
公平性
Fairness
AI 系统正在为全人类创造新体验和新功能。除了推荐应用、短视频和电视节目,AI 系统还能承担更重要的任务,例如预测患病概率和严重程度、为求职者或征婚者牵线搭桥,以及识别是否有人正在过马路。与以往基于特设规则或人为判断的决策过程相比,此类由计算机辅助或决策的系统有望在更大范围内做到更公平、更包容。但这类系统是"双刃剑",如果它们有任何不公平的偏见,也可能会造成大范围的负面影响。因此,随着 AI 在各行各业的影响力与日俱增,构建公平公正、包容并蓄的系统势在必行。
AI systems are enabling new experiences and abilities for people around the globe. Beyond recommending apps, short videos, and TV shows, AI systems can be used for more critical tasks, such as predicting the presence and severity of a medical condition, matching people to jobs and partners, or identifying if a person is crossing the street. Such computerized assistive or decision-making systems have the potential to be more fair and more inclusive at a broader scale than historical decision-making processes based on ad hoc rules or human judgments. The risk is that any unfair bias in such systems can also have a wide-scale impact. Thus, as the impact of AI increases across sectors and societies, it is critical to work towards systems that are fair and inclusive for all.
这绝非易事。首先,机器学习模型的训练依赖于现实世界中收集的已有数据,所以模型很可能会习得甚至放大数据本身在种族、性别、宗教或其他方面的负面偏见。
This is a hard task. First, ML models learn from existing data collected from the real world, and so a model may learn or even amplify problematic pre-existing biases in the data based on race, gender, religion or other characteristics.
其次,即便用尽目前最全面、最严谨的跨功能训练与测试,依然很难构建放之四海而皆准的公平系统。举例来说,如果某个语音识别系统是基于美国成年人数据训练的,那么在"美国成年人"这一特定情境下,该系统或许能做到公平、包容。然而,当面对青少年群体及其不断演变的流行用语时,该系统可能会茫然无措。如果该系统部署在英国,它对某些英式口音的识别可能要比其他口音困难得多。即使将该系统应用于美国成年人,我们也可能会发现,对于特定群体(例如有口吃障碍的人),该系统的语音识别效果不尽如意。系统发布后的使用情况难以预测,可能会暴露出一些在无意中导致的不公平结果。
Second, even with the most rigorous and cross-functional training and testing, it is a challenge to build systems that will be fair across all situations or cultures. For example, a speech recognition system that was trained on US adults may be fair and inclusive in that specific context. When used by teenagers, however, the system may fail to recognize evolving slang words or phrases. If the system is deployed in the United Kingdom, it may have a harder time with certain regional British accents than others. And even when the system is applied to US adults, we might discover unexpected segments of the population whose speech it handles poorly, for example people speaking with a stutter. Use of the system after launch can reveal unintentional, unfair outcomes that were difficult to predict.
再者,"公平"一词并没有标准的定义,无论是由人还是由机器判定。为某个系统确定适宜的公平性判定依据时,需要全面考量用户体验、文化、社会、历史、政治、法律和伦理等诸多因素,并酌情妥善权衡。即使是一些看似简单的情况,对于公平与否,也可能众说纷纭,导致无法确定应基于哪种观点来制定 AI 政策,尤其是在全球环境下。因此,只有持续改进才有望实现"更公平"的系统。
Third, there is no standard definition of fairness, whether decisions are made by humans or machines. Identifying appropriate fairness criteria for a system requires accounting for user experience, cultural, social, historical, political, legal, and ethical considerations, several of which may have tradeoffs. Even for situations that seem simple, people may disagree about what is fair, and it may be unclear what point of view should dictate AI policy, especially in a global setting. That said, it is possible to aim for continuous improvement toward "fairer" systems.
确保 AI 公平、公正且包容已成为当下的一个热门研究领域。为了实现这个目标,就需采取多管齐下的全盘改进方案,包括:培养一支包容的团队,兼收并蓄多种专业知识;在研究和开发过程初期广开言路,尽早深入了解社会情境;评估所用的训练数据集,找出不公平偏见的潜在源头;训练模型以消除或纠正负面偏见;评估不同模型的性能差异;持续对最终版 AI 系统实施对抗性测试,尽早发现并处理不公平结果。事实上,ML 模型甚至能识别一些由来已久的人为偏见和隔阂。这些偏见和隔阂在历史长河中形成并延续至今,无论是有意之举还是无心之失,都妨碍实现包容性,所以一旦被识别并消除,定会对人类未来发展产生长远的积极影响。
Addressing fairness, equity, and inclusion in AI is an active area of research. It requires a holistic approach, from fostering an inclusive workforce that embodies critical and diverse knowledge, to seeking input from communities early in the research and development process to develop an understanding of societal contexts, to assessing training datasets for potential sources of unfair bias, to training models to remove or correct problematic biases, to evaluating models for disparities in performance, to continued adversarial testing of final AI systems for unfair outcomes. In fact, ML models can even be used to identify some of the conscious and unconscious human biases and barriers to inclusion that have developed and perpetuated throughout history, bringing about positive change.
AI 的公平性问题远未解决,它既是机遇也是挑战。Google 致力在所有这些领域中砥砺前行,并为更广大的社区创建工具、数据集和其他资源,同时不断调整这些资源,从容应对生成式 AI 系统发展所带来的新挑战。Google 的当前思路如下所述。
Far from a solved problem, fairness in AI presents both an opportunity and a challenge. Google is committed to making progress in all of these areas, and to creating tools, datasets, and other resources for the larger community and adapting these as new challenges arise with the development of generative AI systems. Our current thinking at Google is outlined below.
推荐做法
Recommended practices
务必尽早确定,机器学习能否为目前面临的特定问题提供有效解决方案。如果能,那么切记:正如没有任何对所有机器学习或 AI 任务都适用的"万能"模型,也没有任何技术能确保所有情况或结果都绝对公平。在实践中,AI 研究人员和开发者应尝试使用各种方法进行迭代和改进,特别是从事生成式 AI 这一新兴领域的工作时。
It is important to identify whether or not machine learning can help provide an adequate solution to the specific problem at hand. If it can, just as there is no single "correct" model for all ML or AI tasks, there is no single technique that ensures fairness in every situation or outcome. In practice, AI researchers and developers should consider using a variety of approaches to iterate and improve, especially when working in the emerging area of generative AI.
- 针对你的产品集思广益,与社会科学家、人文学者和其他相关专家合作,了解并考虑各方的观点。
- Engage with social scientists, humanists, and other relevant experts for your product to understand and account for various perspectives.
- 值得深思的是,随着时间的推移,这项技术及其发展会如何影响不同的用例:代表了哪些人的观点?代表了哪些类型的数据?遗漏了什么?这项技术能助力实现哪些结果?这些结果成真后,不同的用户和社区分别会受到怎样的影响?可能会造成什么样的偏见、负面体验或歧视性结果?
- Consider how the technology and its development over time will impact different use cases: Whose views are represented? What types of data are represented? What's being left out? What outcomes does this technology enable and how do these compare for different users and communities? What biases, negative experiences, or discriminatory outcomes might occur?
- 为你的系统设定目标,让它公平地处理各个预期用例:例如,以 X 种不同的语言,或面向 Y 个不同的年龄段。随着时间的推移,持续监控这些目标并酌情扩展。
- Set goals for your system to work fairly across anticipated use cases: for example, in X different languages, or to Y different age groups. Monitor these goals over time and expand as appropriate.
- 设计要使用的算法和目标函数时,力求反映公平性目标。
- Design your algorithms and objective function to reflect fairness goals.
- 及时更新你的训练数据和测试数据,以适应不断变化的用户群体和他们使用技术的方式。
- Update your training and testing data frequently based on who uses your technology and how they use it.
- 评估数据集的公平性,包括确定数据的代表性和相应局限,以及特征、标签和群体之间的偏见性或歧视性关联。可视化、聚类和数据注解均有助于评估。
- Assess fairness in your datasets, which includes identifying representation and corresponding limitations, as well as identifying prejudicial or discriminatory correlations between features, labels, and groups. Visualization, clustering, and data annotations can help with this assessment.
- 公共训练数据集通常需要扩充,以更好地反映系统要预测的人员、事件和属性的真实频率。
- Public training datasets will often need to be augmented to better reflect real-world frequencies of people, events, and attributes that your system will be making predictions about.
- 了解为数据添加注解的人员的不同观点、经验和目标。"成功"对不同的工作者分别意味着什么?依据什么来权衡任务耗费的时间与任务带来的享受?
- Understand the various perspectives, experiences, and goals of the people annotating the data. What does success look like for different workers, and what are the trade-offs between time spent on task and enjoyment of the task?
- 如果你与注解团队合作,请务必与他们密切协同,设计明确的任务、激励和反馈机制,确保注解的可持续性、多样性和准确性。要考虑人的个体差异,包括无障碍性、肌肉记忆和注解中的偏见。例如,可使用一组有明确答案的标准问题来减小潜在影响。
- If you are working with annotation teams, partner closely with them to design clear tasks, incentives, and feedback mechanisms that ensure sustainable, diverse, and accurate annotations. Account for human variability, including accessibility, muscle memory, and biases in annotation, e.g., by using a standard set of questions with known answers.
- 例如,组建一个由背景多样的可信人员构成的测试小组,让他们对系统进行对抗性测试,并将各种对抗性输入整合到单元测试中。这可帮助你确定哪些人可能会遭受意想不到的负面影响。即使错误率已降到很低,也难免会偶尔出现严重错误。有针对性的对抗性测试可帮助我们发现聚合指标所遮蔽的问题。
- For example, organize a pool of trusted, diverse testers who can adversarially test the system, and incorporate a variety of adversarial inputs into unit tests. This can help to identify who may experience unexpected adverse impacts. Even a low error rate can allow for the occasional very bad mistake. Targeted adversarial testing can help find problems that are masked by aggregate metrics.
- 在设计用于训练和评估系统的指标时,还应加入相关指标来检查系统对不同子群体的效果。例如,我们可逐一分析每个子群体的假正例率和假负例率,从而精准判断哪些群体受到了过多的负面影响,哪些群体受益颇多,以免顾此失彼。
- While designing metrics to train and evaluate your system, also include metrics to examine performance across different subgroups. For example, false positive rate and false negative rate per subgroup can help to understand which groups experience disproportionately worse or better performance.
- 除了细化后的统计指标,我们还需构建一个测试集,用于进行压力测试,从而检验系统在极限情况下的表现。通过这样的测试集,每次更新系统后,都能快速评估系统在处理那些伤害性极强或问题极严重的样例时的表现。就像对待其他所有测试集一样,应持续更新这个特殊测试集,特别是在系统不断演变、功能不断增加、用户反馈不断积累的情况下。
- In addition to sliced statistical metrics, create a test set that stress-tests the system on difficult cases. This will enable you to quickly evaluate how well your system is doing on examples that can be particularly hurtful or problematic each time you update your system. As with all test sets, you should continuously update this set as your system evolves, features are added or removed and you have more feedback from users.
- 考虑系统先前决策所产生的偏见有何影响,以及由此可能形成的反馈环,避免系统越"走"越"偏"。
- Consider the effects of biases created by decisions made by the system previously, and the feedback loops this may create.
- 将你定义的各个不同指标考虑在内。举个例子,系统处理不同子群体的数据时假正例率可能存在差异,某个指标的改进可能会对另一个指标产生负面影响。
- Take the different metrics you've defined into account. For example, a system's false positive rate may vary across different subgroups in your data, and improvements in one metric may adversely affect another.
- 模拟真实的使用场景,覆盖尽可能广泛的用户、用例和情境,从而全面评估用户体验,例如借助 TensorFlow Model Analysis 工具。首先通过 dogfood 进行测试和迭代,然后在发布后继续测试。
- Evaluate user experience in real-world scenarios across a broad spectrum of users, use cases, and contexts of use (e.g., TensorFlow Model Analysis). Test and iterate in dogfood first, followed by continued testing after launch.
- 即使我们精心设计整个系统的方方面面,尽力解决公平性问题,基于机器学习的模型在面对真实的实时数据时,也难以做到尽善尽美。当产品在实际应用中出现问题时,我们需要考虑这个问题是否会加剧某些现有的社会不公平现象,并且需要评估短期和长期解决方案对这个问题的潜在影响。
- Even if everything in the overall system design is carefully crafted to address fairness issues, ML-based models rarely operate with 100%% perfection when applied to real, live data. When an issue occurs in a live product, consider whether it aligns with any existing societal disadvantages, and how it will be impacted by both short- and long-term solutions.
工作成果示例
Examples of our work
-
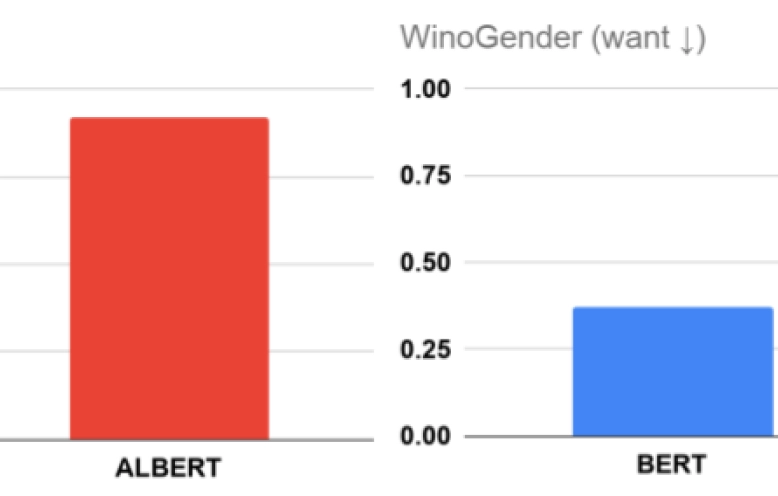
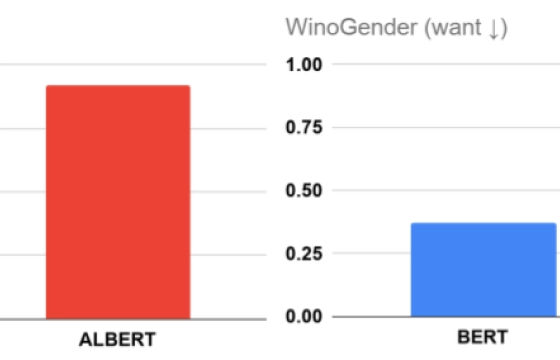
衡量预训练 NLP 模型中的性别相关性
Measuring Gendered Correlations in Pre-trained NLP Models
-

TensorFlow Constrained Optimization 库
TensorFlow Constrained Optimization Library
-


Project Respect
Project Respect
-
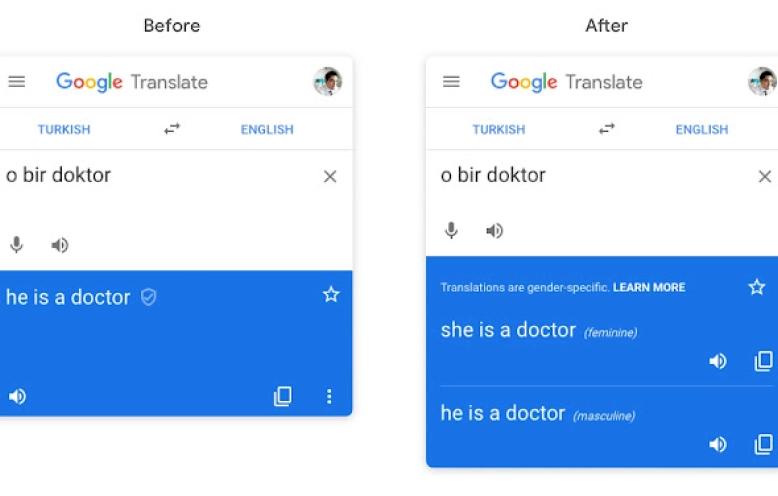
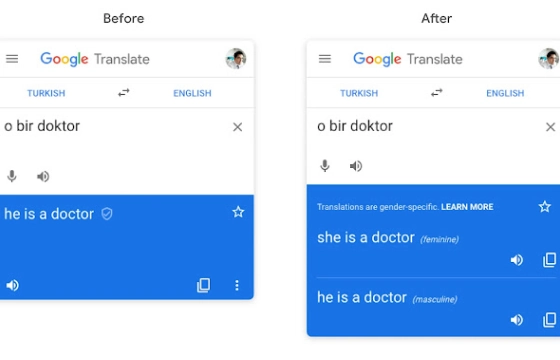
探索"Google 翻译"服务中的性别色彩译文
Gender-specific translations in Google Translate
-
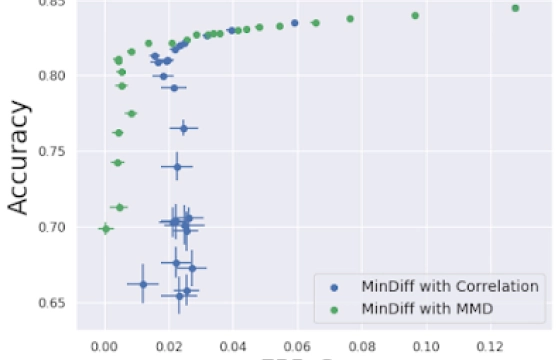
MinDiff:守护机器学习公平性的利器
MinDiff for ML Fairness
-
对抗地学习公平表征:数据决策与理论思考
Data decisions and theoretical implications when adversarially learning fair representations
对抗地学习公平表征:数据决策与理论思考
Data decisions and theoretical implications when adversarially learning fair representations
可解释性
Interpretability
自动化预测和决策技术能在许多方面改善人们的生活,例如推荐你可能喜欢的音乐以及持续监测病人的生命体征。正因如此,可解释性不容小觑。可解释性是指我们能在多大程度上质疑、理解和信任 AI 系统。它不仅反映了我们的领域知识和社会价值观,还能帮助科学家和工程师更好地设计、开发和调试模型,确保 AI 系统按预期工作。
Automated predictions and decision making can improve lives in a number of ways, from recommending music you might like to monitoring a patient's vital signs consistently. This is why interpretability, or the level to which we can question, understand, and trust an AI system, is crucial. Interpretability also reflects our domain knowledge and societal values, provides scientists and engineers with better means of designing, developing, and debugging models, and helps to ensure that AI systems are working as intended.
人类和 AI 系统都面临这样的挑战。毕竟,谁都无法总能合理地解释自己做出的决定。举个例子,肿瘤科医生可能很难将判定患者癌症复发的依据全部量化出来。他们可能只会说,根据自己基于多年诊断经验的直觉,建议患者做进一步检查以获得更明确的诊断结果。相比之下,AI 系统能列出预测所依据的各种信息,比如过去 10 年间 100 位不同患者的生物标志水平和相应扫描结果,但却很难解释,它如何通过整合这些数据,得出癌症复发率为 80%% 的结论并建议患者做个 PET 扫描。即使是机器学习专家,也很难理解复杂的 AI 模型,例如生成式 AI 系统所基于的深度神经网络。
These issues apply to humans as well as AI systems-after all, it's not always easy for a person to provide a satisfactory explanation of their own decisions. For example, it can be difficult for an oncologist to quantify all the reasons why they think a patient's cancer may have recurred-they may just say they have an intuition based on patterns they have seen in the past, leading them to order follow-up tests for more definitive results. In contrast, an AI system can list a variety of information that went into its prediction: biomarker levels and corresponding scans from 100 different patients over the past 10 years, but have a hard time communicating how it combined all that data to estimate an 80%% chance of cancer and recommendation to get a PET scan. Understanding complex AI models, such as deep neural networks which are at the foundation of generative AI systems, can be challenging even for machine learning experts.
与传统软件相比,理解和测试 AI 系统也带来了新挑战,尤其是随着生成式 AI 模型和系统的不断涌现,这些挑战愈发严峻。传统软件在本质上是一系列"if-then"规则,而解释和调试性能在很大程度上就像在错综复杂的岔路上追寻问题。虽然这极具挑战性,但人类通常可以顺藤摸瓜,成功跟踪代码的执行路径,并理解给定的结果。
Understanding and testing AI systems also offers new challenges compared to traditional software - especially as generative AI models and systems continue to emerge. Traditional software is essentially a series of if-then rules, and interpreting and debugging performance largely consists of chasing a problem down a garden of forking paths. While that can be extremely challenging, a human can generally track the path taken through the code, and understand a given result.
对于 AI 系统,"代码路径"可能包含数百万参数(在生成式 AI 系统中,甚至高达数十亿)以及海量的数学运算。因此,与传统软件相比,想要精确定位导致错误决策的 bug 可谓难上加难。然而,凭借 Responsible AI 系统设计,我们可以反向追踪这数百万乃至数十亿参数,溯源到具体的训练数据或模型对特定数据/特征的注意力,最终找到 bug 的根源。这与传统决策软件中的一个关键问题形成了鲜明对比,即"魔数"的存在。"魔数"是指程序员在未予解释的情况下设定的决策规则或阈值,而他们自己早已把当初的想法忘得一干二净。这些"魔数"的设置往往基于程序员的个人直觉或极少数测试样例。
With AI systems, the "code path" may include millions of parameters - and in generative AI systems, they may include billions - and mathematical operations, so it is much harder to pinpoint one specific bug that leads to a faulty decision than with previous software. However, with responsible AI system design, those millions or billions of values can be traced back to the training data or to model attention on specific data or features, resulting in discovery of the bug. That contrasts with one of the key problems in traditional decision-making software, which is the existence of "magic numbers"-decision rules or thresholds set without explanation by a now-forgotten programmer, often based on their personal intuition or a tiny set of trial examples.
总体而言,通过底层的训练数据和训练过程,我们可以尽可能充分理解 AI 系统,以及由此产生的 AI 模型。尽管这带来了新挑战,但随着科技界携手打造负责任的前瞻性指南、最佳实践和相关工具,我们理解、控制和调试 AI 系统的能力正在稳步提升。有鉴于此,我们希望与大家分享我们目前在该领域的一些研究和思考。
Overall, an AI system is best understood by the underlying training data and training process, as well as the resulting AI model. While this poses new challenges, the collective effort of the tech community to formulate proactive responsible guidelines, best practices, and tools is steadily improving our ability to understand, control, and debug AI systems. This, and we'd like to share some of our current work and thinking in this area.
推荐做法
Recommended practices
可解释性和问责制是 Google 和广大 AI 社区持续研究并开发的一个重要领域。在此,我们分享一些目前总结的推荐做法。
Interpretability and accountability is an area of ongoing research and development at Google and in the broader AI community. Here we share some of our recommended practices to date.
在设计并训练模型之前、期间和之后,都可以追求可解释性。
Pursuing interpretability can happen before, during and after designing and training your model.
- 你真正需要多大程度的可解释性?请针对你的模型,与相关领域(例如医疗保健、零售等)的专家紧密合作,共同确定需要哪些可解释性功能及相应原因。虽然很少见,但在某些情况下/系统中,如果积累了充分的经验证据,则不需要细粒度的可解释性。
- What degree of interpretability do you really need? Work closely with relevant domain experts for your model (e.g., healthcare, retail, etc.) to identify what interpretability features are needed, and why. While rare, there are some cases/systems where with sufficient empirical evidence, fine-grain interpretability is not needed.
- 你能否分析自己的训练/测试数据?例如,如果处理的是私密数据,可能就无法调查相应输入数据。
- Can you analyze your training/testing data? For example, if you are working with private data, you may not have access to investigate your input data.
- 你能否更改训练/测试数据?例如,针对特定子集(例如特征空间的某些部分/细分)收集更多训练数据,或者针对感兴趣的类别收集测试数据。
- Can you change your training/testing data, for example, gather more training data for certain subsets (e.g., parts/slices of the feature space), or gather test data for categories of interest?
- 你能自行设计新模型还是只能使用已训练的模型?
- Can you design a new model or are you constrained to an already-trained model?
- 你是否提供了过多的详细信息,以至于可能会导致滥用?
- Are you providing too much transparency, potentially opening up vectors for abuse?
- 你给出的训练后可解释性选项有哪些?你是否有权知晓模型的内部工作机制(例如是黑盒模型还是白盒模型)?
- What are your post-train interpretability options? Will you have access to the internals of the model (e.g., black box vs. white box)?
- 在开发周期中与用户反复沟通,测试并优化你对用户需求和目标的假设。
- Iterate with users in the development cycle to test and refine your assumptions about user needs and goals.
- 设计用户体验时,要引导用户构建适宜的心智模型以便使用 AI 系统。如果你未提供清晰且令人信服的信息,用户可能会自己虚构关于 AI 系统运作方式的理论,这可能会对他们尝试使用系统的方式产生负面影响。
- Design the UX so that users build useful mental models of the AI system. If not given clear and compelling information, users may make up their own theories about how an AI system works, which can negatively affect how they try to use the system.
- 尽可能为用户自行分析敏感度创造便利条件:让他们能够测试不同的输入对模型输出结果有何影响。
- Where possible, make it easy for users to do their own sensitivity analysis: empower them to test how different inputs affect the model output.
- 其他相关的用户体验资源:以人为本的设计、用户控制、训练 AI、习惯化、公平性、表征
- Additional relevant UX resources: Designing for human needs, user control, teaching an AI, habituation, fairness, representation
- 在能达成性能目标的前提下,使用尽可能小的输入集,以便更清晰地了解哪些因素会对模型产生影响。
- Use the smallest set of inputs necessary for your performance goals to make it clearer what factors are affecting the model.
- 只要能实现性能目标,模型越简单越好。
- Use the simplest model that meets your performance goals.
- 尽可能学习因果关系而非相关性。例如,判断孩子乘坐过山车是否安全时,应以身高(而非年龄)为依据。
- Learn causal relationships not correlations when possible (e.g., use height not age to predict if a kid is safe to ride a roller coaster).
- 确保训练目标与真实目标保持一致。例如,如果目标是将误报率控制在可接受范围内,那么训练就应围绕误报率展开,而不是单纯追求准确率。
- Craft the training objective to match your true goal (e.g., train for the acceptable probability of false alarms, not accuracy).
- 适当约束模型,使其生成的输入-输出关系既专业又合理。例如,在推荐咖啡店时,如果其他条件相同,距用户更近的咖啡店应更有可能被推荐。
- Constrain your model to produce input-output relationships that reflect domain expert knowledge (e.g., a coffee shop should be more likely to be recommended if it's closer to the user, if everything else about it is the same).
你选择的指标必须考虑到特定情境中的具体收益和风险。例如,火灾警报系统需要达到高召回率,即使偶尔误报也无妨。
The metrics you consider must address the particular benefits and risks of your specific context. For example, a fire alarm system would need to have high recall, even if that means the occasional false alarm.
目前,正在开发的许多技术都旨在帮助我们更好地理解模型的内部机制,例如模型对不同输入的敏感度。
Many techniques are being developed to gain insights into the model (e.g., sensitivity to inputs).
- 针对不同的样例子集,分别分析模型对不同输入的敏感度。
- Analyze the model's sensitivity to different inputs, for different subsets of examples.
- 应提供易于理解且适合用户查看的解释。比如,业内人士和学术界人士可能需要了解技术细节,而普通用户可能更喜欢即时弹出的界面提示、通俗易懂的摘要解释或直观呈现的内容。恰当的解释需要结合具体应用情境,仔细考量哲学、心理学、计算机科学(包括人机交互)、法律和伦理等诸多因素。
- Provide explanations that are understandable and appropriate for the user (e.g., technical details may be appropriate for industry practitioners and academia, while general users may find UI prompts, user-friendly summary descriptions or visualizations more useful). Explanations should be informed by a careful consideration of philosophical, psychological, computer science (including HCI), legal and ethical considerations about what counts as a good explanation in different contexts.
- 解释并非多多益善,有些情况下,提供解释反而不妥。例如:如果解释会让普通用户更加困惑,或者会被不法分子用以损害系统或用户安全,抑或会泄露专有信息,就不宜提供。
- Identify if and where explanations may not be appropriate (e.g., where explanations could result in more confusion for general users, nefarious actors could take advantage of the explanation for system or user abuse, or explanations may reveal proprietary information).
- 如果某个用户群要求提供解释,但你无法或不应提供,或者无法提供明确、合理的解释,这时就需要考虑采用替代方案。不妨改以其他方式实现问责制。例如接受审核、允许用户质疑决策或收集用户反馈,从而改进未来的决策和体验。
- Consider alternatives if explanations are requested by a certain user base but cannot or should not be provided, or if it's not possible to provide a clear, sound explanation. You could instead provide accountability through other mechanisms such as auditing or allow users to contest decisions or to provide feedback to influence future decisions or experiences.
- 应优先提供那些能明确指导用户操作的清晰解释,方便用户未来纠正不准确的预测。
- Prioritize explanations that suggest clear actions a user can take to correct inaccurate predictions going forward.
- 不要暗示相关解释意味着因果关系,除非确实如此。
- Don't imply that explanations mean causation unless they do.
- 认识到人类的心理和局限(例如确认偏差、认知疲劳)
- Recognize human psychology and limitations (e.g., confirmation bias, cognitive fatigue)
- 解释形式可以不拘一格(例如文本、图表、统计数据):在使用可视化资源提供数据洞见时,遵循 HCI 和可视化方面的最佳实践。
- Explanations can come in many forms (e.g., text, graphs, statistics): when using visualization to provide insights, use best practices from HCI and visualization.
- 任何经过聚合的摘要都可能会丢失信息并淹没细节(例如部分依赖关系)。
- Any aggregated summary may lose information and hide details (e.g., partial dependency plots).
- 如果能理解机器学习系统的各个部分(尤其是输入)以及所有部分之间如何协作(即“完整性”),用户就容易针对相应系统构建更明确的心智模型。这些心智模型更贴近系统的实际性能,能提供更可信的体验,并为未来的学习设定更准确的期望。
- The ability to understand the parts of the ML system (especially inputs) and how all the parts work together (“completeness”) helps users to build clearer mental models of the system. These mental models match actual system performance more closely, providing for a more trustworthy experience and more accurate expectations for future learning.
- 注意解释的局限。例如,不能以偏概全,随意将局部解释推而广之;而且,对于两个看起来相似的样例,局部解释可能会互相冲突。
- Be mindful of the limitations of your explanations (e.g., local explanations may not generalize broadly, and may provide conflicting explanations of two visually-similar examples).
借鉴软件工程最佳测试实践和质量工程技术,确保 AI 系统能按预期运行且值得信赖。
Learn from software engineering best test practices and quality engineering to make sure the AI system is working as intended and can be trusted.
- 执行严格的单元测试,让系统中的每个组件都接受单独测试。
- Conduct rigorous unit tests to test each component of the system in isolation.
- 主动检测输入偏移,通过测试 AI 系统的输入统计信息,确保输入未发生意外变化。
- Proactively detect input drift by testing the statistics of the inputs to the AI system to make sure they are not changing in unexpected ways.
- 使用黄金标准数据集来测试系统,确保其行为持续符合预期。定期更新该测试集,以契合不断变化的用户和用例,降低模型基于测试集进行训练的可能性。
- Use a gold standard dataset to test the system and ensure that it continues to behave as expected. Update this test set regularly in line with changing users and use cases, and to reduce the likelihood of training on the test set.
- 在开发周期内,执行迭代的用户测试,兼顾不同用户的多样化需求。
- Conduct iterative user testing to incorporate a diverse set of users' needs in the development cycles.
- 践行质量工程领域的波卡纠偏 (poka-yoke) 原则:在系统中内置质量检查机制,确保意外故障无法发生或会触发立即响应(例如,如果某项重要功能意外缺失,AI 系统将不会输出任何预测结果)。
- Apply the quality engineering principle of poka-yoke: build quality checks into a system so that unintended failures either cannot happen or trigger an immediate response (e.g., if an important feature is unexpectedly missing, the AI system won't output a prediction).
- 执行集成测试:了解 AI 系统如何与其他系统交互,以及生成了哪些反馈环(例如,如果因热度高而推荐某篇新闻报道,可能会使该报道的热度进一步升高,导致它被更多地推荐)。
- Conduct integration tests: understand how the AI system interacts with other systems and what, if any, feedback loops are created (e.g., recommending a news story because it's popular can make that news story more popular, causing it to be recommended more).
工作成果示例
Examples of our work
-


Google Cloud 与 Explainable AI
Explainable AI with Google Cloud
-
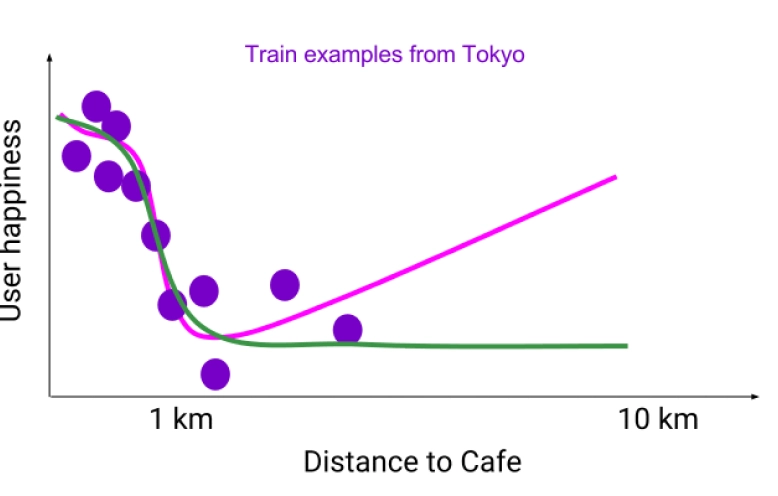
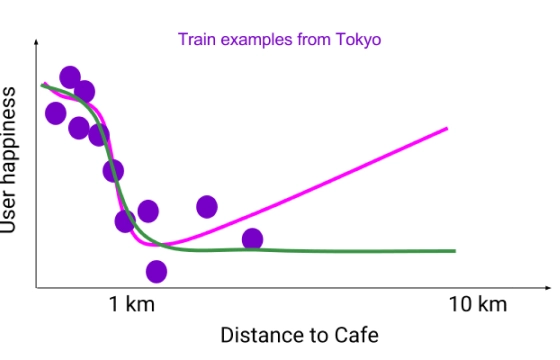
TensorFlow Lattice(开源)
TensorFlow Lattice (open source)
-


XRAI
XRAI
-


DeepDream 和可解释性的基石
Deepdream and building blocks of interpretability
-
What-If 工具(开源)
What-If Tool (open source)
-
推动可解释的机器学习成为一门严谨的科学
Towards a rigorous science of interpretable machine learning
推动可解释的机器学习成为一门严谨的科学
Towards a rigorous science of interpretable machine learning
隐私性
Privacy
机器学习模型会从训练数据中学习,并基于输入数据进行预测。有时,训练数据、输入数据或两者都可能非常敏感。构建基于敏感数据运行的模型可能会带来巨大好处。例如,我们可以负责任地收集活检图像数据来训练癌症检测器,并将该检测器用于分析个人患者的扫描图像。但利弊相依,我们必须认真考量使用敏感数据会带来的潜在隐私风险。这不仅包括严格遵守法律及监管要求,还应充分考虑社会规范和普通个人的期望。例如,考虑到机器学习模型可能会记住或透露其接触过的部分数据信息,建立安全机制保护个人隐私是一项至关重要的安保措施。务必要保障用户对其数据的知情权和控制权。
ML models learn from training data and make predictions on input data. Sometimes the training data, input data, or both can be quite sensitive. Although there may be enormous benefits to building a model that operates on sensitive data (e.g., a cancer detector trained on a responsibly sourced dataset of biopsy images and deployed on individual patient scans), it is essential to consider the potential privacy implications in using sensitive data. This includes not only respecting the legal and regulatory requirements, but also considering social norms and typical individual expectations. For example, it's crucial to put safeguards in place to ensure the privacy of individuals considering that ML models may remember or reveal aspects of the data they have been exposed to. It's essential to offer users transparency and control of their data.
幸运的是,只要以有的放矢、讲究原则的方式恰当地应用各种技术,就能最大限度地降低机器学习模型泄露底层数据的可能性。Google 一直在为实现 AI 系统中的隐私保护而孜孜不倦地研发各种此类技术,包括适用于生成式 AI 系统的各种新兴实践。对 AI 社区来说,这是一个方兴未艾的研究领域,未来仍有广阔的发展空间。以下是我们目前积累的一些经验教训。
Fortunately, the possibility that ML models reveal underlying data can be minimized by appropriately applying various techniques in a precise, principled fashion. Google is constantly developing such techniques to protect privacy in AI systems, including emerging practices for generative AI systems. This is an active area of research in the AI community with ongoing room for growth. Below we share the lessons we have learned so far.
推荐做法
Recommended practices
正如没有任何对所有 ML 任务都适用的“万能”模型,也没有任何能在所有场景下实现 ML 隐私保护的通用方法,更何况新方法可能会不断涌现。在实践中,研究人员和开发者需要精雕细琢、反复迭代,找到两全其美的方法,在保护隐私的同时兼顾任务效用。而这一切的前提是清晰界定隐私的定义,既要通俗易懂,又要严谨精确。
Just as there is no single "correct" model for all ML tasks, there is no single correct approach to ML privacy protection across all scenarios, and new ones may arise. In practice, researchers and developers must iterate to find an approach that appropriately balances privacy and utility for the task at hand; for this process to succeed, a clear definition of privacy is needed, which can be both intuitive and formally precise.
- 尝试能否在不使用敏感数据的情况下训练机器学习模型,例如,利用非敏感数据集或现有公共数据源另辟蹊径。
- Identify whether your ML model can be trained without the use of sensitive data, e.g., by utilizing non-sensitive data collection or an existing public data source.
- 如果必须处理敏感的训练数据,应设法尽量减少对此类数据的使用。处理敏感数据要慎之又慎:例如,首先要遵守相关法律和标准;其次要向用户提供明确通知,并向用户赋予对数据使用方式的必要控制权;此外要遵循相关最佳实践,例如对传输和存储的数据实施加密;最后要恪守 Google 的隐私权原则。
- If it is essential to process sensitive training data, strive to minimize the use of such data. Handle any sensitive data with care: e.g., comply with required laws and standards, provide users with clear notice and give them any necessary controls over data use, follow best practices such as encryption in transit and rest, and adhere to Google privacy principles.
- 对传入的数据进行匿名化和聚合处理时,务必滴水不漏,采用符合最佳实践要求的数据清理管道:例如,考虑删除个人身份信息 (PII) 和可能导致去匿名化的异常值或元数据(包括隐式元数据,例如到达顺序,此类数据可通过随机打乱来移除,如 Prochlo 中那样;或使用 Cloud Data Loss Prevention API 自动发现并隐去敏感数据和身份标识数据)。
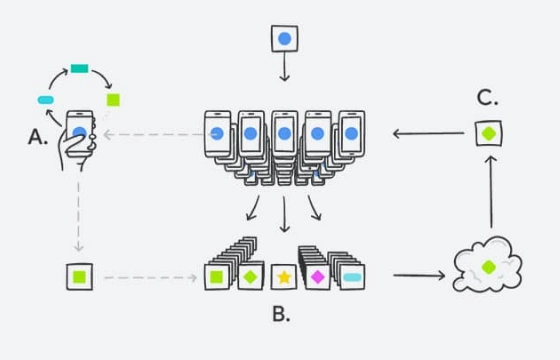
- Anonymize and aggregate incoming data using best practice data-scrubbing pipelines: e.g., consider removing personally identifiable information (PII) and outlier or metadata values that might allow de-anonymization (including implicit metadata such as arrival order, removable by random shuffling, as in ProchloProchlo; or the Cloud Data Loss Prevention API to automatically discover and redact sensitive and identifying data).
- 如果你的目标是学习个人交互统计数据(例如某些界面元素的使用频率),不妨考虑只收集在本地设备端计算的统计数据,而不收集可能包含敏感信息的原始交互数据。
- If your goal is to learn statistics of individual interactions (e.g., how often certain UI elements are used), consider collecting only statistics that have been computed locally, on-device, rather than raw interaction data, which can include sensitive information.
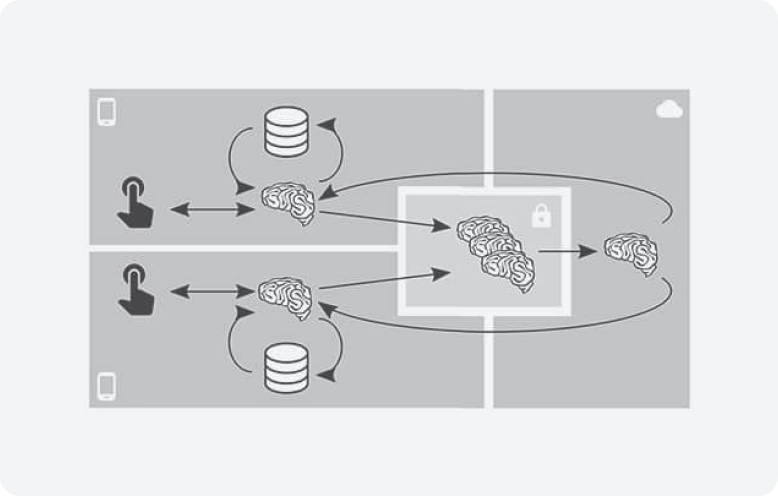
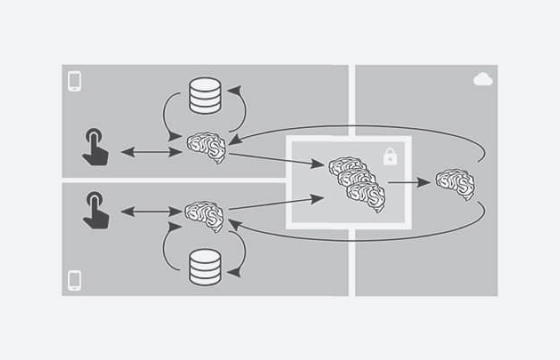
- 考虑某些技术能否提升系统的隐私保护水平,以联邦学习为例,该技术支持一组设备协同工作,基于本地存储的训练数据来训练共享的全局模型。
- Consider whether techniques like federated learning, where a fleet of devices coordinates to train a shared global model from locally-stored training data, can improve privacy in your system.
- 在可行的情况下,在设备端实施聚合、随机化和清理操作(例如安全聚合、RAPPOR,以及 Prochlo 的编码步骤)。需要注意的是,这些操作本身并非万无一失,除非附带相关证明,否则它们只能因地制宜、尽力而为地提供隐私保护。
- When feasible, apply aggregation, randomization, and scrubbing operations on-device (e.g., Secure aggregation, RAPPOR, and Prochlo's encode step). Note that these operations may only provide pragmatic, best-effort privacy unless the techniques employed are accompanied by proofs.
由于机器学习模型可能会通过其内部参数和外部可见行为泄露训练数据的详细信息,因此务必考虑模型的构建方式和访问方式对隐私保护有何影响。
Because ML models can expose details about their training data via both their internal parameters as well as their externally-visible behavior, it is crucial to consider the privacy impact of how the models were constructed and may be accessed.
- 评估你的模型是否会无意中记忆或泄露敏感数据,为此,可以使用基于“泄露”衡量或成员推断评估的测试。这些指标也可在模型维护期间用于回归测试。
- Estimate whether your model is unintentionally memorizing or exposing sensitive data using tests based on “exposure” measurements or membership inference assessment. These metrics can additionally be used for regression tests during model maintenance.
- 为了精益求精,实现数据最少化,你需要针对不同的参数进行实验(例如聚合、异常值阈值和随机化因素),从而权衡利弊,最终确定模型的最佳设置。
- Experiment with parameters for data minimization (e.g., aggregation, outlier thresholds, and randomization factors) to understand tradeoffs and identify optimal settings for your model.
- 使用能通过数学手段保证隐私性的技术来训练机器学习模型。需要注意的是,这些分析保证并不是对整个操作系统的全面保证。
- Train ML models using techniques that establish mathematical guarantees for privacy. Note that these analytic guarantees are not guarantees about the complete operational system.
- 遵循针对加密和安全关键型软件制定的最佳实践流程,例如,使用有原则且可证明的方法、以同行评审的方式发布新想法、对关键软件组件进行开源,以及在设计和开发的各个阶段邀请专家审核。
- Follow best-practice processes established for cryptographic and security-critical software, e.g., the use of principled and provable approaches, peer-reviewed publication of new ideas, open-sourcing of critical software components, and the enlistment of experts for review at all stages of design and development.
工作成果示例
Examples of our work
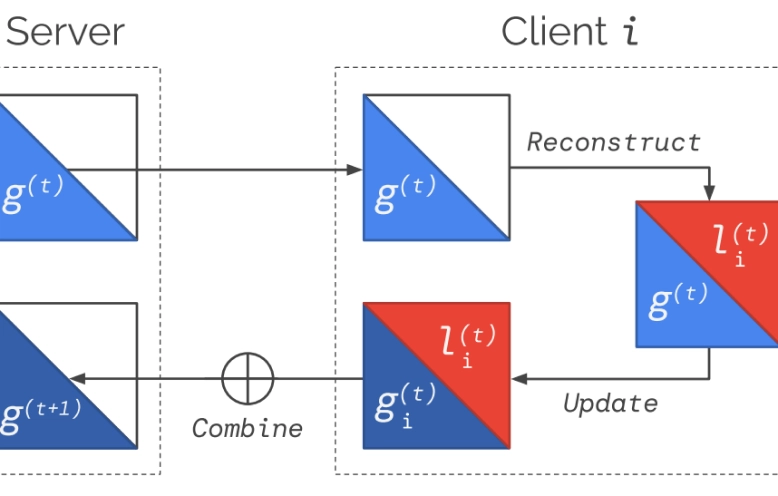
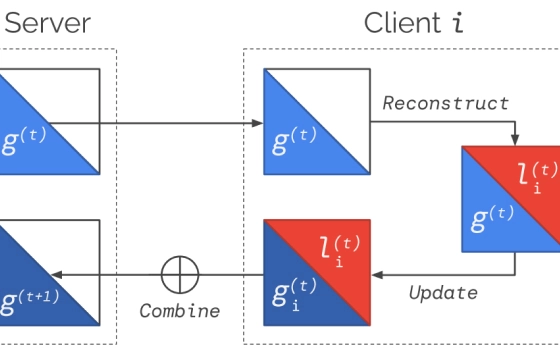
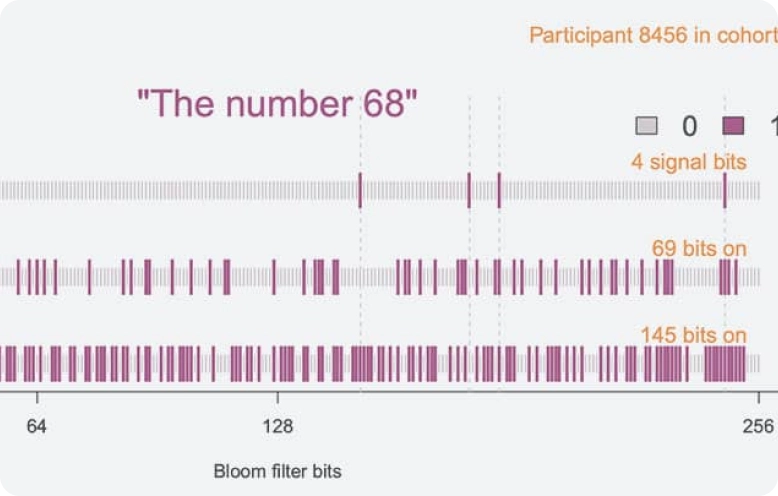


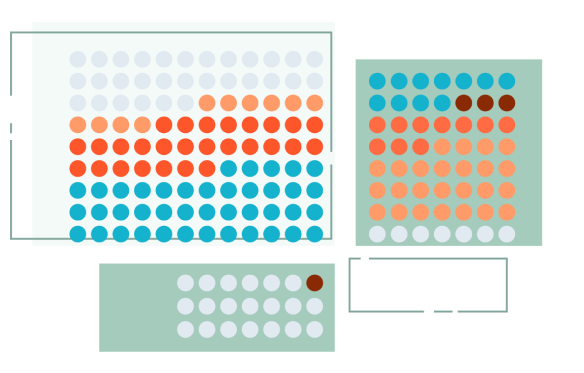
安全性
Safety and security
安全意味着确保 AI 系统始终按预期运行,无论攻击者如何不择手段地试图干扰。未雨绸缪方能防患未然,在 AI 系统受到安全关键型应用的广泛依赖之前,务必考虑并解决其安全性问题。AI 系统的安全性面临着许多特有的挑战。例如,当将 ML 应用于人类难以解决的问题时,想要提前预测所有可能出现的场景绝非易事;而在生成式 AI 的时代,这种难度更是有增无减。同样,我们也很难构建出理想的系统,使其既能严防死守,具备必要的主动性安全限制,又能随机应变,具备生成创造性解决方案和适应异常输入所必需的灵活性。随着 AI 技术的不断发展,安全问题也会随之演变,因为攻击者必然会找到新的攻击手段;所以,我们要未雨绸缪,尽早开发新的解决方案。以下是我们根据现有经验提供的一些建议。
Safety and security entails ensuring AI systems behave as intended, regardless of how attackers try to interfere. It is essential to consider and address the safety of an AI system before it is widely relied upon in safety-critical applications. There are many challenges unique to the safety and security of AI systems. For example, it is hard to predict all scenarios ahead of time, when ML is applied to problems that are difficult for humans to solve, and especially so in the era of generative AI. It is also hard to build systems that provide both the necessary proactive restrictions for safety as well as the necessary flexibility to generate creative solutions or adapt to unusual inputs. As AI technology evolves, so will security issues, as attackers will surely find new means of attack; and new solutions will need to be developed in tandem. Below are our current recommendations from what we've learned so far.
推荐做法
Recommended practices
机器学习安全研究包罗万象,涵盖各种威胁,包括训练数据中毒、敏感训练数据恢复、模型窃取和对抗性安全示例。Google 不遗余力地在所有这些领域开展了大量研究,其中部分工作关乎 AI 隐私保护方面的实践。Google 安全研究的重点之一是对抗性学习,即:利用一个神经网络生成能够欺骗系统的对抗性示例,同时利用第二个网络来尝试检测相应的欺骗行为。
Safety research in ML spans a wide range of threats, including training data poisoning, recovery of sensitive training data, model theft and adversarial security examples. Google invests in research related to all of these areas, and some of this work is related to practices in AI privacy. One focus of safety research at Google has been adversarial learning-the use of one neural network to generate adversarial examples that can fool a system, coupled with a second network to try to detect the fraud.
目前,针对对抗性示例的最佳防御措施还不够成熟,不适合在生产环境中使用。这是一个方兴未艾、发展势头迅猛的热门研究领域。由于尚无有效的防御措施,开发者应料敌于先,提前考虑其系统是否可能遭到攻击,评估攻击得逞后的潜在危害,并且 在大多数情况下,应该避免构建可能会因此类攻击而造成重大负面影响的系统。
Currently, the best defenses against adversarial examples are not yet reliable enough for use in a production environment. It is an ongoing, extremely active research area. Because there is not yet an effective defense, developers should think about whether their system is likely to come under attack, consider the likely consequences of a successful attack and in most cases should simply not build systems where such attacks are likely to have significant negative impact.
另一种实践是对抗性测试,用于系统地评估 ML 模型或应用在遭遇恶意输入或无意产生的有害输入时的反应,例如,要求某款文本生成模型针对特定宗教生成仇恨言论。这种实践方法可防患未然,利用目前已知的故障模式为模型和产品预警,并指引相应的化解方式(例如调优模型,或者为输入/输出部署过滤器或其他安全措施),从而帮助团队系统地优化模型和产品。最近,我们将持续开展的“红队”活动(一种查漏补缺的对抗性安全测试方法,用于发现易受攻击的漏洞)升级至“有道德地攻击”我们的 AI 系统,为安全 AI 框架保驾护航。
Another practice is adversarial testing, a method for systematically evaluating an ML model or application with the intent of learning how it behaves when provided with malicious or inadvertently harmful input, such as asking a text generation model to generate a hateful rant about a particular religion. This practice helps teams systematically improve models and products by exposing current failure patterns, and guide mitigation pathways (e.g. model fine-tuning, or putting in place filters or other safeguards on input or outputs). Most recently, we've evolved our ongoing "red teaming” efforts, an adversarial security testing approach that identifies vulnerabilities to attacks - to " ethically hack" our AI systems and support our Secure AI Framework.
- 考虑是否有人会故意让系统出现故障。例如,如果开发者构建了一款照片整理应用,用户固然能随意修改照片,让系统无法正确整理。不过,扰乱系统对用户无益,所以用户应该不会这样做。
- Consider whether anyone would have an incentive to make the system misbehave. For example, if a developer builds an app that helps a user organize their own photos, it would be easy for users to modify photos to be incorrectly organized, but users may have limited incentive to do so.
- 确定系统出错可能会导致的意外后果,并评估此类后果的发生几率和严重程度。
- Identify what unintended consequences would result from the system making a mistake, and assess the likelihood and severity of these consequences.
- 构建严谨的威胁模型,以了解所有可能的攻击途径。例如,一个系统允许攻击者更改输入到机器学习模型的数据,而另一个系统处理由服务器收集的元数据(例如用户执行操作的时间戳),那么前者比后者更容易受到攻击,因为用户很难故意修改在自己未直接参与的情况下收集的输入特征。
- Build a rigorous threat model to understand all possible attack vectors. For example, a system that would allow an attacker to change the input to the ML model may be much more vulnerable than a system that processes metadata collected by the server, like timestamps of actions the user took, since it is much harder for a user to intentionally modify input features collected without their direct participation.
某些应用(例如垃圾邮件过滤服务)尽管在对抗性机器学习方面困难重重,仍能利用当前的防御技术成功应对威胁。
Some applications, e.g., spam filtering, can be successful with current defense techniques despite the difficulty of adversarial ML.
- 在对抗性环境中测试系统性能。在某些情况下,这种测试可通过 CleverHans 等工具实现。
- 建立内部红队进行测试,或者举办比赛或启动漏洞赏金计划,鼓励第三方对你的系统进行对抗性测试。
- Test the performance of your systems in the adversarial setting. In some cases this can be done using tools such as CleverHansCleverHans.
- Create an internal red team to carry out the testing, or host a contest or bounty program encouraging third parties to adversarially test your system.
- Stay up to date on the latest research advances. Research into adversarial machine learning continues to offer improved performance for defenses and some defense techniques are beginning to offer provable guarantees.
- Beyond interfering with input, it is possible there may be other vulnerabilities in the ML supply chain. While to our knowledge such an attack has not yet occurred, it is important to consider the possibility and be prepared.
- 及时了解最新的研究进展。对抗性机器学习研究日新月异,促使防御性能不断提升,某些防御技术已开始提供可证明的保证。
- 除了干扰输入,机器学习供应链中可能还存在其他漏洞。据我们所知,这种攻击尚未发生,但居安思危不多余,未雨绸缪才明智。