
جستجوی ابری به کارمندان اجازه میدهد تا اطلاعاتی مانند اسناد داخلی، فیلدهای پایگاه داده و دادههای CRM را از مخازن داده داخلی جستجو و بازیابی کنند.
نمای کلی معماری
شکل 1 اجزای کلیدی پیادهسازی جستجوی ابری را نشان میدهد:
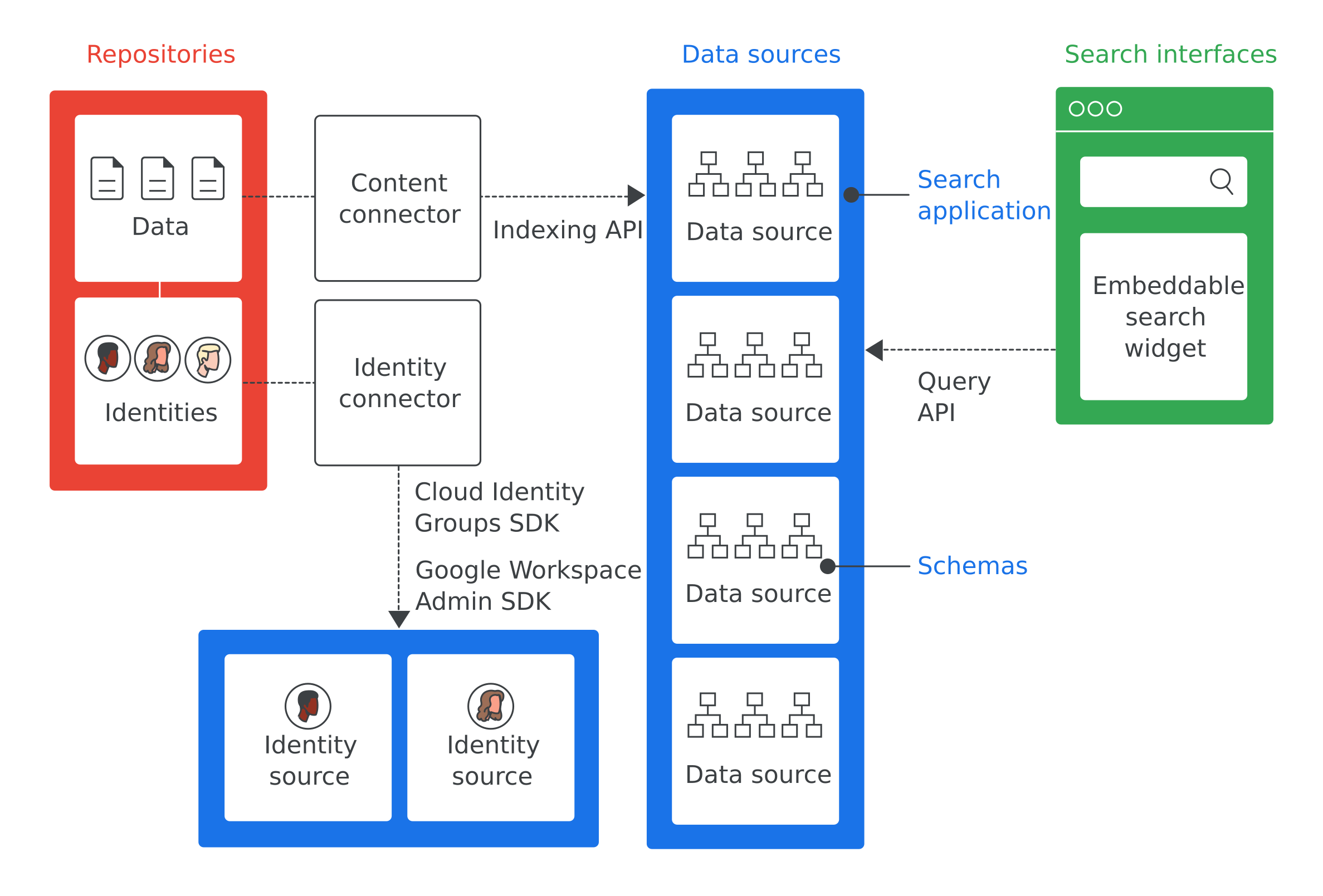
در اینجا تعاریف مهمترین اصطلاحات از شکل 1 آمده است:
- مخزن
- نرمافزاری که توسط یک شرکت برای ذخیره دادهها استفاده میشود، مانند پایگاه دادهای که برای ذخیره اطلاعات کارمندان استفاده میشود.
- منبع داده
- دادههایی از مخزنی که Cloud Search آنها را فهرستبندی و ذخیره میکند.
- رابط جستجو
- رابط کاربری که کارمندان برای جستجوی یک منبع داده استفاده میکنند. شما میتوانید یک رابط جستجو برای هر دستگاهی، مانند تلفن همراه یا رایانه رومیزی، ایجاد کنید. همچنین میتوانید ویجت جستجوی ارائه شده توسط گوگل را برای فعال کردن جستجو در وبسایتهای داخلی خود مستقر کنید. هر جستجو شامل شناسه برنامه جستجو برای شناسایی زمینه جستجو، مانند یک ابزار خدمات مشتری، است. سایت cloudsearch.google.com حاوی یک رابط جستجو است.
- جستجوی برنامه
- گروهی از تنظیمات که وقتی با رابط جستجو مرتبط میشوند، اطلاعات زمینهای در مورد جستجوها ارائه میدهند. اطلاعات زمینهای شامل منابع داده و رتبهبندیهای جستجو مورد استفاده برای یک جستجو میشود. برنامههای جستجو همچنین شامل مکانیسمهایی برای فیلتر کردن نتایج هستند و گزارشدهی در مورد منابع داده، مانند تعداد پرسوجوهای انجام شده در یک دوره زمانی مشخص را فعال میکنند.
- طرحواره
- یک ساختار داده که نحوه نمایش دادهها در یک مخزن سازمانی برای جستجوی ابری را مشخص میکند. یک طرح، تجربه جستجوی ابری کارمندان، مانند نحوه فیلتر کردن و مشاهده دادهها توسط کاربران را تعریف میکند.
- رابط محتوا
- یک برنامه نرمافزاری که دادهها را در مخزن سازمانی پیمایش میکند و یک منبع داده را پر میکند.
- رابط هویت
- یک برنامه نرمافزاری که هویتهای سازمانی (کاربران و گروهها) را با هویتهای مورد نیاز Cloud Search همگامسازی میکند.
موارد استفاده از جستجوی ابری
مثالهایی از موارد استفاده برای جستجوی ابری:
- کارمندان باید سیاستها، اسناد و محتوای شرکتی که توسط سایر کارمندان نوشته شده است را پیدا کنند.
- اعضای تیم خدمات مشتری باید اسناد مربوط به عیبیابی را برای ارسال به مشتریان پیدا کنند.
- کارمندان باید اطلاعات داخلی در مورد پروژههای شرکت را پیدا کنند.
- یک نماینده فروش میخواهد وضعیت تمام مشکلات پشتیبانی یک مشتری خاص را مشاهده کند.
- کارمندان میخواهند تعریفی برای یک اصطلاح خاص شرکت داشته باشند.
اولین قدم در پیادهسازی جستجوی ابری، شناسایی موارد استفاده مرتبط است.
پیادهسازی جستجوی ابری
به طور پیشفرض، جستجوی ابری، دادههای Google Workspace مانند اسناد و صفحات گسترده گوگل را فهرستبندی میکند. نیازی به پیادهسازی جستجوی ابری برای دادههای Google Workspace ندارید. با این حال، باید جستجوی ابری را برای دادههای غیر Google Workspace، مانند دادههای ذخیره شده در یک پایگاه داده شخص ثالث، سیستمهای فایل مانند Windows File Share، OneDrive یا پورتالهای اینترانت مانند SharePoint، پیادهسازی کنید. برای پیادهسازی جستجوی ابری برای سازمان خود، این مراحل را دنبال کنید.
- یک مورد استفاده که جستجوی ابری به حل آن کمک میکند را تعیین کنید.
- مخازنی را که دادههای مربوط به مورد استفاده را در خود جای دادهاند، شناسایی کنید.
- سیستمهای هویتی مورد استفاده توسط شرکت شما برای مدیریت دسترسی به دادهها در هر مخزن را شناسایی کنید.
- دسترسی به API جستجوی ابری گوگل را پیکربندی کنید .
- یک منبع داده به جستجوی ابری اضافه کنید .
- برای هر منبع داده، یک طرحواره ایجاد و ثبت کنید .
- بررسی کنید که آیا رابط محتوا برای مخزن شما موجود است یا خیر. برای مشاهده فهرست رابطهای از پیش ساخته شده، به فهرست رابطهای جستجوی ابری مراجعه کنید. اگر رابط محتوا موجود است، به مرحله ۹ بروید.
- یک رابط محتوا برای دسترسی به دادهها در هر مخزن ایجاد کنید و آن را در یک منبع داده جستجوی ابری فهرستبندی کنید.
- مشخص کنید که آیا به یک رابط هویت نیاز دارید یا خیر. اگر به یک رابط هویت نیاز ندارید، به مرحله ۱۱ بروید.
- یک رابط هویت ایجاد کنید تا هویتهای مخزن یا سازمان خود را به هویتهای گوگل نگاشت کنید.
- برنامههای جستجو را تنظیم کنید .
- یک رابط جستجو برای انجام جستجوهای پرسوجو ایجاد کنید .
- رابطها و رابطهای جستجوی خود را مستقر کنید. اگر از یک رابط از پیش ساخته شده استفاده کردهاید، دستورالعملهای مربوط به رابط را برای دریافت و استقرار آن دنبال کنید. رابطهای موجود در فهرست رابطهای جستجوی ابری فهرست شدهاند.
مراحل بعدی
- آموزش شروع به کار با جستجوی ابری را امتحان کنید.
- موارد استفادهای را که برای آنها از جستجوی ابری استفاده خواهید کرد، تعیین کنید.
- مخازن مربوط به این موارد استفاده را شناسایی کنید.
- هرگونه سیستم هویتی مورد استفاده توسط مخازن خود را شناسایی کنید.
- ادامه پیکربندی دسترسی به API جستجوی ابری .