Вместо сравнения данных объектов, объединенных вручную, вы можете свести данные объектов к представлениям, называемым внедрениями , а затем сравнить их. Вложения генерируются путем обучения контролируемой глубокой нейронной сети ( DNN ) на самих данных объекта. Вложения сопоставляют данные объекта с вектором в пространстве внедрения, обычно имеющем меньше измерений, чем данные объекта. Встраивания обсуждаются в модуле «Внедрения» ускоренного курса машинного обучения, а нейронные сети обсуждаются в модуле «Нейронные сети» . Векторы встраивания для аналогичных примеров, таких как видеоролики YouTube на схожие темы, которые смотрят одни и те же пользователи, в конечном итоге оказываются близко друг к другу в пространстве встраивания. Контролируемая мера сходства использует эту «близость» для количественной оценки сходства пар примеров.
Помните, мы обсуждаем обучение с учителем только для того, чтобы создать меру сходства. Мера сходства, ручная или контролируемая, затем используется алгоритмом для выполнения неконтролируемой кластеризации.
Сравнение ручных и контролируемых мер
В этой таблице описано, когда следует использовать ручную или контролируемую меру сходства в зависимости от ваших требований.
| Требование | Руководство | Контролируемый |
|---|---|---|
| Устраняет избыточную информацию в коррелирующих функциях? | Нет, вам необходимо исследовать любые корреляции между функциями. | Да, DNN удаляет избыточную информацию. |
| Дает представление о рассчитанных сходствах? | Да | Нет, вложения не могут быть расшифрованы. |
| Подходит для небольших наборов данных с небольшим количеством функций? | Да. | Нет, небольшие наборы данных не предоставляют достаточного количества обучающих данных для DNN. |
| Подходит для больших наборов данных со множеством функций? | Нет, вручную удалить избыточную информацию из нескольких функций, а затем объединить их очень сложно. | Да, DNN автоматически удаляет избыточную информацию и объединяет функции. |
Создание контролируемой меры сходства
Ниже приведен обзор процесса создания контролируемой меры сходства:

На этой странице обсуждаются DNN, а на следующих страницах описаны оставшиеся шаги.
Выбирайте DNN на основе обучающих меток
Сократите свои данные о признаках до внедрений меньшей размерности, обучив DNN, которая использует одни и те же данные о признаках как в качестве входных данных, так и в качестве меток. Например, в случае с данными о доме DNN будет использовать такие характеристики, как цена, размер и почтовый индекс, чтобы самостоятельно прогнозировать эти характеристики.
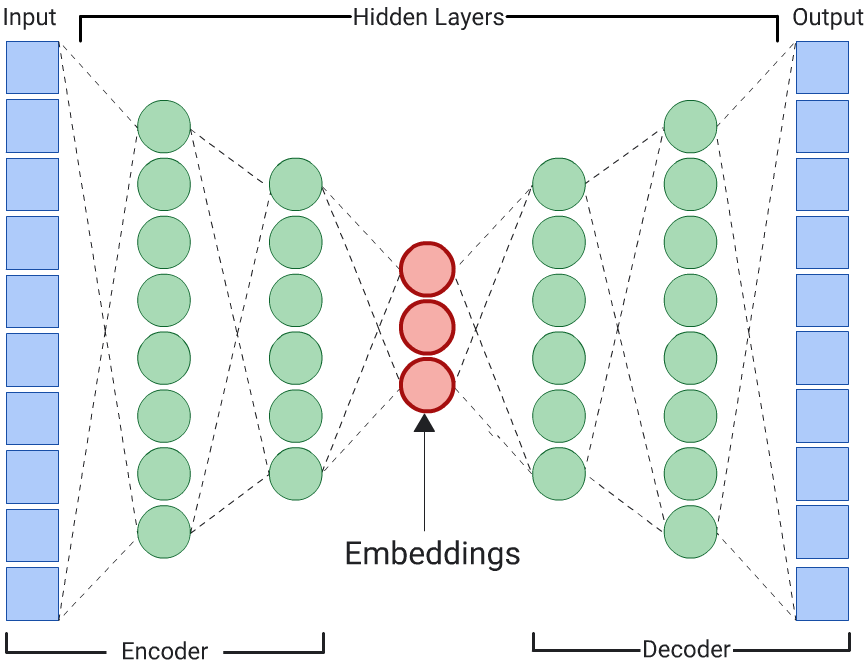
Автоэнкодер
DNN, которая изучает встраивания входных данных путем прогнозирования самих входных данных, называется автокодировщиком . Поскольку скрытые слои автокодировщика меньше входных и выходных слоев, автокодировщику приходится изучать сжатое представление входных пространственных данных. После обучения DNN извлеките вложения из наименьшего скрытого слоя, чтобы вычислить сходство.
Предсказатель
Автоэнкодер — это самый простой вариант для создания вложений. Однако автоэнкодер не является оптимальным выбором, когда определенные функции могут быть более важными, чем другие, при определении сходства. Например, в данных о доме предполагается, что цена важнее почтового индекса. В таких случаях используйте только важную функцию в качестве обучающей метки для DNN. Поскольку эта DNN прогнозирует конкретный входной признак вместо прогнозирования всех входных признаков, она называется предикторной DNN. Вложения обычно следует извлекать из последнего слоя внедрения.
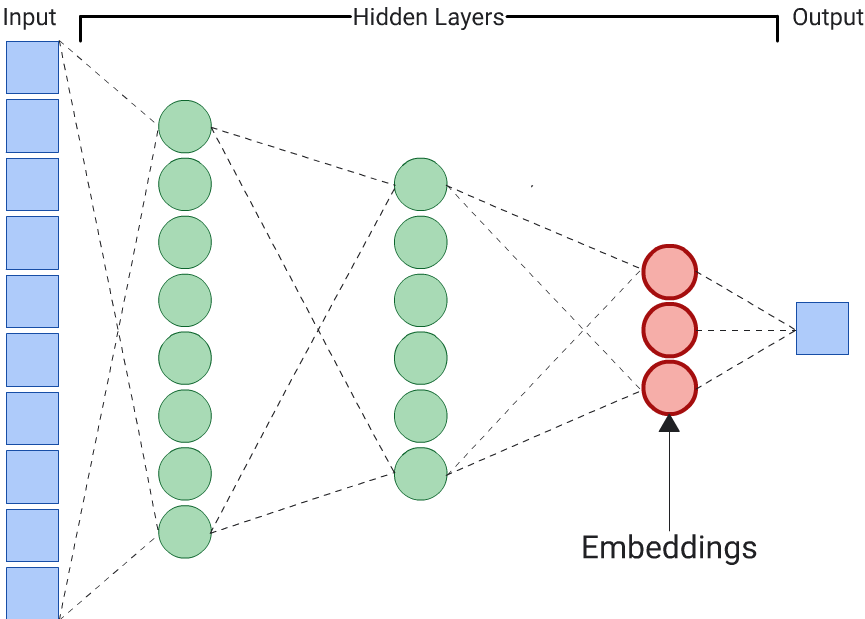
При выборе объекта для метки:
Предпочитайте числовые характеристики категориальным, потому что потери легче вычислять и интерпретировать для числовых характеристик.
Удалите функцию, которую вы используете в качестве метки, из входных данных в DNN, иначе DNN будет использовать эту функцию для точного прогнозирования выходных данных. (Это крайний пример утечки этикеток .)
В зависимости от вашего выбора меток результирующая DNN является либо автокодировщиком, либо предиктором.