Suponha que você esteja trabalhando com um conjunto de dados que inclui informações do paciente de um sistema de saúde. O conjunto de dados é complexo e inclui atributos categóricos e numéricos. Você quer encontrar padrões e semelhanças no conjunto de dados. Como você faria isso?
Clustering é uma técnica de machine learning não supervisionada projetada para agrupar exemplos não rotulados com base na semelhança entre eles. Se os exemplos forem rotulados, esse tipo de agrupamento é chamado de classificação. Considere um estudo hipotético de paciente projetado para avaliar um novo protocolo de tratamento. Durante o estudo, os pacientes informam quantas vezes por semana eles apresentam sintomas e a gravidade deles. Os pesquisadores podem usar a análise de agrupamento para agrupar pacientes com respostas semelhantes ao tratamento em clusters. A Figura 1 demonstra um possível agrupamento de dados simulados em três clusters.
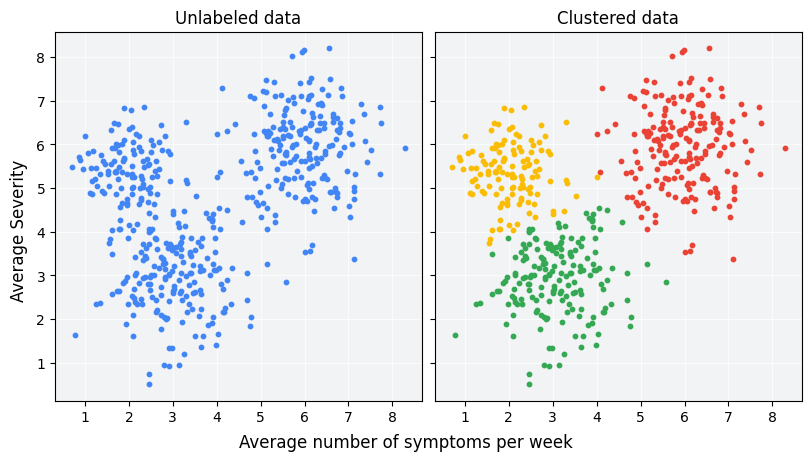
Analisando os dados não rotulados à esquerda da Figura 1, você pode supor que os dados formam três clusters, mesmo sem uma definição formal de semelhança entre os pontos de dados. No entanto, em aplicativos reais, é necessário definir explicitamente uma medida de similaridade, ou a métrica usada para comparar amostras, em termos dos recursos do conjunto de dados. Quando os exemplos têm apenas alguns recursos, visualizar e medir a semelhança é simples. No entanto, à medida que o número de atributos aumenta, a combinação e a comparação deles se tornam menos intuitivas e mais complexas. Diferentes medidas de similaridade podem ser mais ou menos adequadas para diferentes cenários de agrupamento, e este curso abordará a escolha de uma medida de similaridade adequada em seções posteriores: Medidas de similaridade manuais e Medida de similaridade de embeddings.
Após a formação de clusters, cada grupo recebe um rótulo exclusivo chamado ID de cluster. O agrupamento é poderoso porque pode simplificar conjuntos de dados grandes e complexos com vários recursos em um único ID de cluster.
Casos de uso de agrupamento
O agrupamento é útil em vários setores. Algumas aplicações comuns para agrupamento:
- Segmentação de mercado
- Análise de rede social
- Agrupamento de resultados da pesquisa
- Imagiologia médica
- Segmentação de imagens
- Detecção de anomalias
Alguns exemplos específicos de agrupamento:
- O diagrama de Hertzsprung-Russell mostra aglomerados de estrelas quando plotados por luminosidade e temperatura.
- A sequência de genes que mostra semelhanças e diferenças genéticas anteriormente desconhecidas entre espécies levou à revisão de taxonomias anteriormente baseadas na aparência.
- O modelo de traços de personalidade Big 5 foi desenvolvido agrupando palavras que descrevem a personalidade em cinco grupos. O modelo HEXACO usa seis clusters em vez de cinco.
Imputação
Quando alguns exemplos em um cluster têm dados de elementos ausentes, é possível inferir os dados ausentes de outros exemplos no cluster. Isso é chamado de imputação. Por exemplo, vídeos menos populares podem ser agrupados com vídeos mais populares para melhorar as recomendações.
Compactação de dados
Como discutido, o ID de cluster relevante pode substituir outros recursos para todos os exemplos nesse cluster. Essa substituição reduz o número de recursos e, portanto, também reduz os recursos necessários para armazenar, processar e treinar modelos com esses dados. Para conjuntos de dados muito grandes, essa economia se torna significativa.
Por exemplo, um único vídeo do YouTube pode ter dados de recursos, incluindo:
- local, horário e informações demográficas do espectador
- carimbos de data/hora, texto e IDs de usuários dos comentários
- tags de vídeo
Agrupar vídeos do YouTube substitui esse conjunto de recursos por um ID de cluster único, comprimindo os dados.
Preservação da privacidade
É possível preservar a privacidade agrupando usuários e associando dados de usuários a IDs de cluster em vez de IDs de usuários. Por exemplo, suponha que você queira treinar um modelo com base no histórico de exibição dos usuários do YouTube. Em vez de transmitir IDs de usuário ao modelo, você pode agrupar usuários e transmitir apenas o ID do cluster. Isso impede que os históricos de exibição individuais sejam anexados a usuários individuais. O cluster precisa conter um número suficientemente grande de usuários para preservar a privacidade.