本節將回顧機器學習速成課程「使用數值資料」單元中,與群聚分析最相關的資料準備步驟。
在聚類中,您可以將兩個範例的所有特徵資料合併為數值,藉此計算兩個範例之間的相似度。這需要資料集具有相同的比例,您可以透過正規化、轉換或建立分位數來達成這點。如果您想轉換資料,但不檢查其分布情形,可以預設使用分位數。
資料標準化
您可以將多個特徵的資料轉換為相同的比例,方法是將資料正規化。
Z 分
每當您看到資料集的形狀大致類似高斯分布時,就應為資料計算Z 分數。Z 分數是指值與平均值之間相差幾個標準差。如果資料集不夠大,無法用於計算分位數,您也可以使用 Z 分數。
請參閱Z 分數調整一文,瞭解相關步驟。
以下是 z-score 縮放前後,資料集的兩個特徵視覺化圖表:
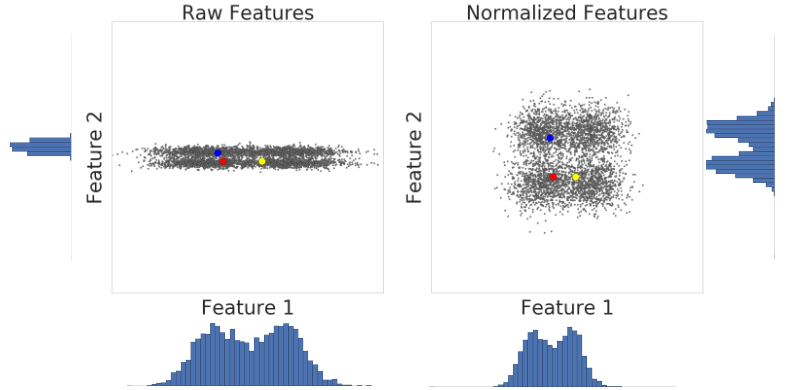
在左側未正規化的資料集中,分別在 X 軸和 Y 軸上繪製的特徵 1 和特徵 2 的比例不相同。在左側,紅色範例與藍色相近或更相似,在右側,經過 z-score 縮放後,特徵 1 和特徵 2 的縮放比例相同,紅色範例看起來會更接近黃色範例。正規化資料集可更準確地評估點之間的相似性。
記錄轉換
如果資料集完全符合冪律分布,且資料在最低值處聚集,請使用對數轉換。請參閱「記錄縮放」一文,瞭解相關步驟。
以下是對數轉換前後的對數法則資料集視覺化圖表:
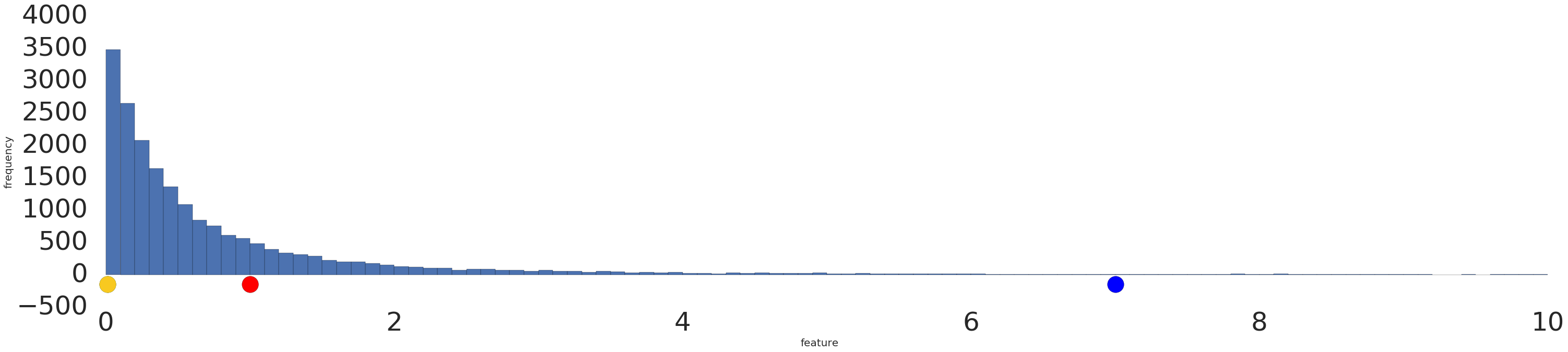
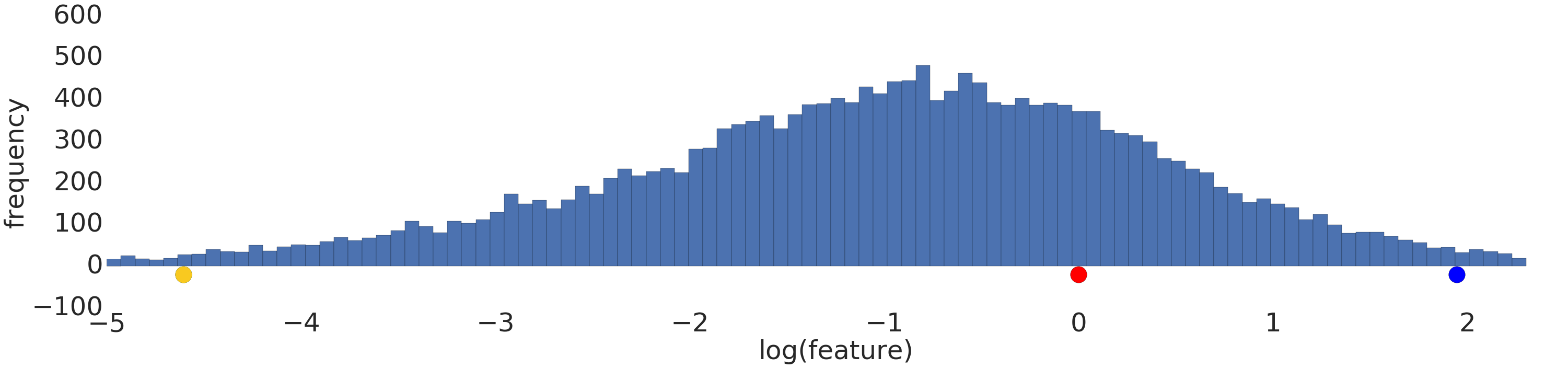
在對數縮放前 (圖 2),紅色範例看起來更像黃色。經過對數縮放 (圖 3) 後,紅色會更接近藍色。
分位數
如果資料集不符合已知分佈模式,將資料分割成分位數會很有幫助。以這個資料集為例:

直覺來說,如果兩個範例之間只有少數幾個範例,無論其值為何,兩者就比較相似;如果兩者之間有許多範例,兩者就比較不相似。上方的示意圖無法清楚顯示紅色和黃色之間,或紅色和藍色之間的示例總數。
您可以將資料集劃分為四分位數 (或各包含相同數量範例的間隔),並為每個範例指派四分位數索引,藉此瞭解相似度。請參閱百分位值區隔,瞭解相關步驟。
以下是將前述分布圖劃分為四分位數的結果,顯示紅色與黃色之間相差一個四分位數,藍色與紅色之間相差三個四分位數:
![圖表顯示轉換為分位數後的資料。線條代表 20 個間隔。]](https://developers.google.cn/static/machine-learning/clustering/images/Quantize.png?authuser=4&hl=zh-tw)
您可以選擇任意數量的分位數。 \(n\) 不過,如果您希望分位數能有效呈現基礎資料,資料集至少應包含\(10n\) 個例項。如果資料不足,請改為使用標準化功能。
進行隨堂測驗
在下列問題中,假設您有足夠的資料可建立分位數。
第一題
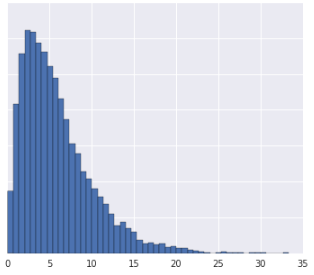
- 資料分布是高斯分布。
- 您對資料在實際情況中代表的意義有一定程度的瞭解,因此建議您不要以非線性方式轉換資料。
第二題
缺少資料
如果資料集中有某個特徵的範例缺少值,但這些範例很少出現,您可以移除這些範例。如果這些範例經常出現,您可以完全移除該特徵,也可以使用機器學習模型,根據其他範例預測缺少的值。舉例來說,您可以使用以現有特徵資料訓練的迴歸模型,推斷缺少的數值資料。