Представляем кроссы функций
Может ли пересечение признаков действительно позволить модели соответствовать нелинейным данным? Чтобы узнать это, попробуйте это упражнение.
Задача. Попробуйте создать модель, которая отделяет синие точки от оранжевых, вручную изменив веса следующих трех входных функций:
- х 1
- х 2
- х 1 х 2 (характерный крест)
Чтобы вручную изменить вес:
- Нажмите на линию, соединяющую FEATURES с OUTPUT. Появится форма ввода.
- Введите значение с плавающей запятой в эту форму ввода.
- Нажмите Ввод.
Обратите внимание, что интерфейс этого упражнения не содержит кнопки «Шаг». Это потому, что это упражнение не обучает модель итеративно. Вместо этого вы будете вручную вводить «окончательные» веса модели.
(Ответы находятся сразу под упражнением.)
Более сложные пересечения функций
Теперь давайте поиграем с некоторыми перекрестными комбинациями расширенных функций. Набор данных в этом упражнении Playground немного похож на шумное яблочко из игры в дартс с синими точками посередине и оранжевыми точками на внешнем кольце.
Щелкните значок плюса для объяснения визуализации модели.
Каждое упражнение Playground отображает визуализацию текущего состояния модели. Например, вот визуализация:
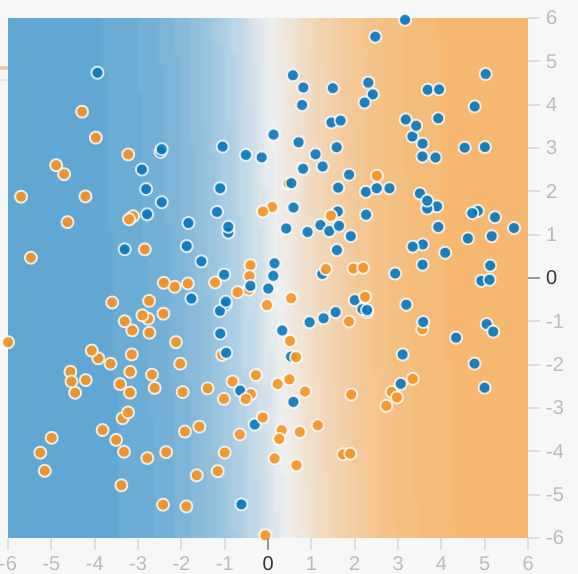
Обратите внимание на следующее о визуализации модели:
- Каждая ось представляет определенную функцию. В случае спама и не спама функциями могут быть количество слов и количество получателей электронной почты.
- Каждая точка отображает значения характеристик для одного примера данных, например электронной почты.
- Цвет точки представляет класс, к которому принадлежит пример. Например, синие точки могут обозначать сообщения, не являющиеся спамом, а оранжевые — спам.
- Цвет фона представляет собой предсказание модели о том, где должны быть найдены примеры этого цвета. Синий фон вокруг синей точки означает, что модель правильно предсказывает этот пример. И наоборот, оранжевый фон вокруг синей точки означает, что модель неверно предсказывает этот пример.
- Фоновые синие и оранжевые цвета масштабируются. Например, левая сторона визуализации окрашена сплошным синим цветом, но постепенно переходит в белый цвет в центре визуализации. Вы можете думать о насыщенности цвета как о том, что модель уверена в своем предположении. Таким образом, сплошной синий означает, что модель очень уверена в своем предположении, а светло-синий означает, что модель менее уверена. (Визуализация модели, показанная на рисунке, плохо справляется с прогнозированием.)
Используйте визуализацию, чтобы оценить прогресс вашей модели. («Отлично — большинство синих точек имеют синий фон» или «О нет! Синие точки имеют оранжевый фон».) Помимо цветов, Playground также отображает текущие потери модели в числовом виде. («О нет! Потери растут, а не падают».)
Задача 1: Запустите эту линейную модель как задано. Потратьте минуту или две (но не больше), пробуя различные настройки скорости обучения, чтобы увидеть, сможете ли вы найти какие-либо улучшения. Может ли линейная модель дать эффективные результаты для этого набора данных?
Задача 2. Теперь попробуйте добавить кросс-продуктовые функции, такие как x 1 x 2 , чтобы оптимизировать производительность.
- Какие функции помогают больше всего?
- Какова лучшая производительность, которую вы можете получить?
Задача 3: Когда у вас есть хорошая модель, изучите выходную поверхность модели (показана фоновым цветом).
- Это похоже на линейную модель?
- Как бы вы описали модель?
(Ответы находятся сразу под упражнением.)