এই মুহুর্তে, আমরা আমাদের ডেটাসেট একত্রিত করেছি এবং আমাদের ডেটার মূল বৈশিষ্ট্যগুলির অন্তর্দৃষ্টি অর্জন করেছি৷ পরবর্তী, ধাপ 2 এ আমরা যে মেট্রিক্স সংগ্রহ করেছি তার উপর ভিত্তি করে, আমাদের কোন শ্রেণীবিভাগ মডেল ব্যবহার করা উচিত সে সম্পর্কে আমাদের চিন্তা করা উচিত। এর মানে প্রশ্ন জিজ্ঞাসা করা যেমন:
- সাংখ্যিক ইনপুট আশা করে এমন একটি অ্যালগরিদমে পাঠ্য ডেটা কীভাবে উপস্থাপন করবেন? (এটিকে ডেটা প্রিপ্রসেসিং এবং ভেক্টরাইজেশন বলা হয়।)
- আপনি কি ধরনের মডেল ব্যবহার করা উচিত?
- আপনার মডেলের জন্য কি কনফিগারেশন পরামিতি ব্যবহার করা উচিত?
কয়েক দশকের গবেষণার জন্য ধন্যবাদ, আমরা ডেটা প্রিপ্রসেসিং এবং মডেল কনফিগারেশন বিকল্পগুলির একটি বৃহৎ অ্যারের অ্যাক্সেস পেয়েছি। যাইহোক, বেছে নেওয়ার জন্য কার্যকর বিকল্পগুলির একটি খুব বড় অ্যারের প্রাপ্যতা একটি নির্দিষ্ট সমস্যার জটিলতা এবং সুযোগকে ব্যাপকভাবে বাড়িয়ে তুলতে পারে। সর্বোত্তম বিকল্পগুলি সুস্পষ্ট নাও হতে পারে তা প্রদত্ত, একটি নিষ্পাপ সমাধান হ'ল অন্তর্দৃষ্টির মাধ্যমে কিছু পছন্দ ছাঁটাই করে প্রতিটি সম্ভাব্য বিকল্পকে পরিপূর্ণভাবে চেষ্টা করা। যাইহোক, এটি অত্যন্ত ব্যয়বহুল হবে।
এই নির্দেশিকাতে, আমরা একটি পাঠ্য শ্রেণিবিন্যাসের মডেল নির্বাচন করার প্রক্রিয়াটিকে উল্লেখযোগ্যভাবে সহজ করার চেষ্টা করি। একটি প্রদত্ত ডেটাসেটের জন্য, আমাদের লক্ষ্য হল এমন অ্যালগরিদম খুঁজে বের করা যা প্রশিক্ষণের জন্য প্রয়োজনীয় গণনার সময়কে কম করে সর্বাধিক নির্ভুলতার কাছাকাছি অর্জন করে। আমরা 12টি ডেটাসেট ব্যবহার করে, বিভিন্ন ডেটা প্রিপ্রসেসিং কৌশল এবং বিভিন্ন মডেল আর্কিটেকচারের মধ্যে প্রতিটি ডেটাসেটের জন্য পর্যায়ক্রমে বিভিন্ন ধরণের সমস্যা (বিশেষ করে অনুভূতি বিশ্লেষণ এবং বিষয়ের শ্রেণীবিভাগের সমস্যা) জুড়ে প্রচুর পরিমাণে (~450K) পরীক্ষা চালিয়েছি। এটি আমাদের ডেটাসেট প্যারামিটার সনাক্ত করতে সাহায্য করেছে যা সর্বোত্তম পছন্দগুলিকে প্রভাবিত করে।
নীচের মডেল নির্বাচন অ্যালগরিদম এবং ফ্লোচার্ট আমাদের পরীক্ষার একটি সারসংক্ষেপ। চিন্তা করবেন না যদি আপনি এখনও তাদের মধ্যে ব্যবহৃত সমস্ত পদ বুঝতে না পারেন; এই গাইডের নিম্নলিখিত বিভাগগুলি তাদের গভীরভাবে ব্যাখ্যা করবে।
ডেটা প্রস্তুতি এবং মডেল বিল্ডিংয়ের জন্য অ্যালগরিদম
- প্রতি নমুনা অনুপাতের নমুনার সংখ্যা/শব্দের সংখ্যা গণনা করুন।
- যদি এই অনুপাতটি 1500-এর কম হয়, তাহলে টেক্সটটিকে n-গ্রাম হিসাবে টোকেনাইজ করুন এবং তাদের শ্রেণীবদ্ধ করতে একটি সাধারণ মাল্টি-লেয়ার পারসেপ্ট্রন (MLP) মডেল ব্যবহার করুন (নীচের ফ্লোচার্টে বাম শাখা):
- নমুনাগুলিকে শব্দ এন-গ্রামে বিভক্ত করুন; n-গ্রামকে ভেক্টরে রূপান্তর করুন।
- ভেক্টরের গুরুত্ব স্কোর করুন এবং তারপর স্কোর ব্যবহার করে শীর্ষ 20K নির্বাচন করুন।
- একটি MLP মডেল তৈরি করুন।
- যদি অনুপাত 1500-এর বেশি হয়, পাঠ্যটিকে ক্রম হিসাবে টোকেনাইজ করুন এবং সেগুলিকে শ্রেণিবদ্ধ করতে একটি sepCNN মডেল ব্যবহার করুন (নীচের ফ্লোচার্টে ডান শাখা):
- শব্দের মধ্যে নমুনা বিভক্ত; তাদের ফ্রিকোয়েন্সি উপর ভিত্তি করে শীর্ষ 20K শব্দ নির্বাচন করুন.
- নমুনাগুলিকে শব্দ ক্রম ভেক্টরে রূপান্তর করুন।
- যদি প্রতি নমুনা অনুপাতের নমুনার আসল সংখ্যা/শব্দের সংখ্যা 15K-এর কম হয়, তাহলে sepCNN মডেলের সাথে একটি সূক্ষ্ম-টিউন করা প্রাক-প্রশিক্ষিত এম্বেডিং ব্যবহার করলে সম্ভবত সেরা ফলাফল পাওয়া যাবে।
- ডেটাসেটের জন্য সেরা মডেল কনফিগারেশন খুঁজে পেতে বিভিন্ন হাইপারপ্যারামিটার মান দিয়ে মডেলের কার্যকারিতা পরিমাপ করুন।
নীচের ফ্লোচার্টে, হলুদ বাক্সগুলি ডেটা এবং মডেল প্রস্তুতির প্রক্রিয়াগুলি নির্দেশ করে৷ ধূসর বাক্স এবং সবুজ বাক্সগুলি প্রতিটি প্রক্রিয়ার জন্য আমরা বিবেচনা করা পছন্দগুলি নির্দেশ করে৷ সবুজ বাক্স প্রতিটি প্রক্রিয়ার জন্য আমাদের প্রস্তাবিত পছন্দ নির্দেশ করে।
আপনি এই ফ্লোচার্টটিকে আপনার প্রথম পরীক্ষা তৈরি করতে একটি সূচনা বিন্দু হিসাবে ব্যবহার করতে পারেন, কারণ এটি আপনাকে কম গণনা খরচে ভাল নির্ভুলতা দেবে। তারপরে আপনি পরবর্তী পুনরাবৃত্তিগুলিতে আপনার প্রাথমিক মডেলে উন্নতি চালিয়ে যেতে পারেন।
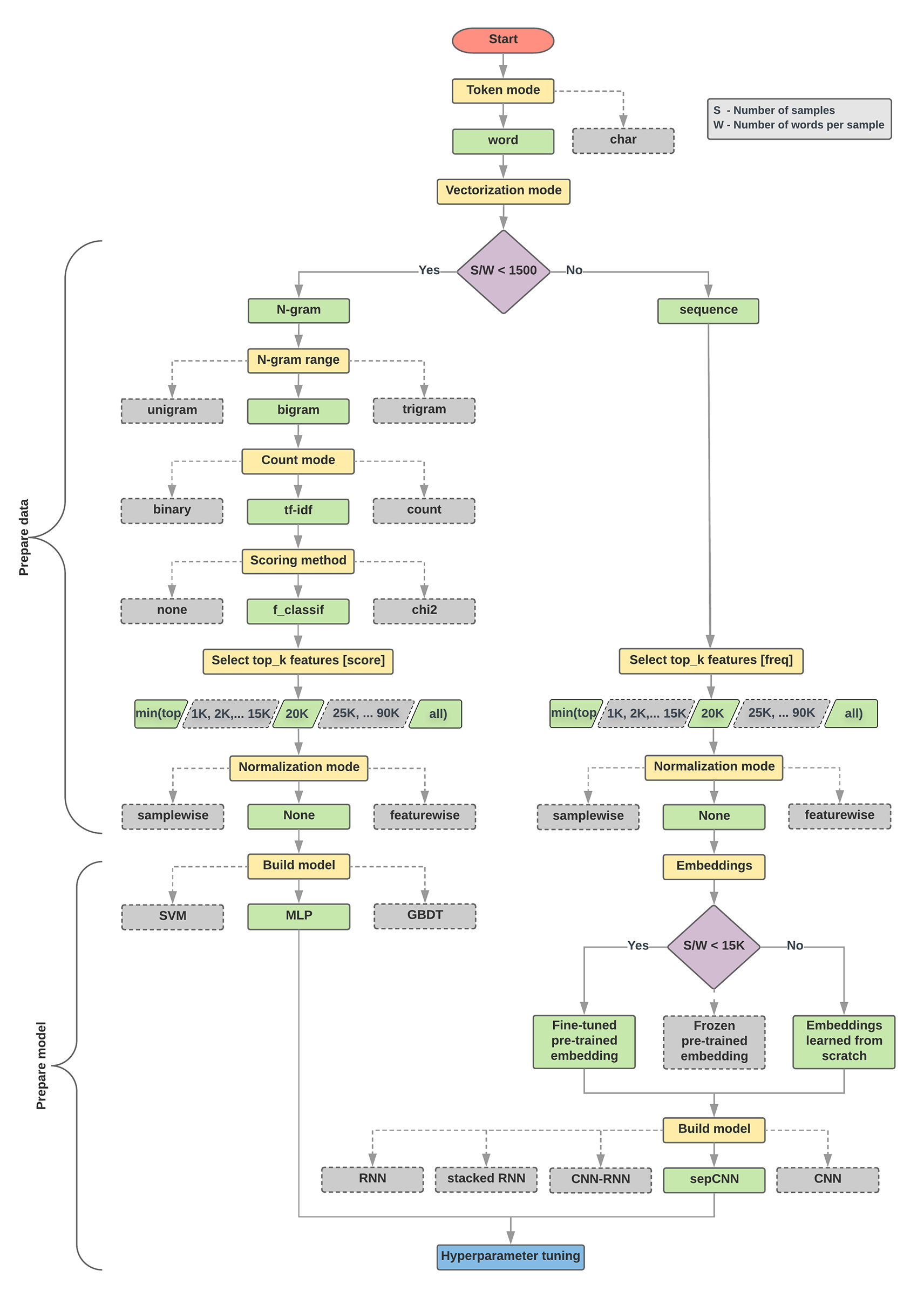
চিত্র 5: পাঠ্য শ্রেণিবিন্যাস ফ্লোচার্ট
এই ফ্লোচার্ট দুটি মূল প্রশ্নের উত্তর দেয়:
- কোন লার্নিং অ্যালগরিদম বা মডেল ব্যবহার করা উচিত?
- পাঠ্য এবং লেবেলের মধ্যে সম্পর্কটি দক্ষতার সাথে শিখতে আপনার কীভাবে ডেটা প্রস্তুত করা উচিত?
দ্বিতীয় প্রশ্নের উত্তর নির্ভর করে প্রথম প্রশ্নের উত্তরের ওপর; আমরা যেভাবে একটি মডেলে ডেটা দেওয়ার জন্য প্রিপ্রসেস করব তা নির্ভর করবে আমরা কোন মডেলটি বেছে নেব তার উপর। মডেলগুলিকে বিস্তৃতভাবে দুটি বিভাগে শ্রেণীবদ্ধ করা যেতে পারে: যেগুলি ওয়ার্ড অর্ডারিং তথ্য ব্যবহার করে (সিকোয়েন্স মডেল), এবং যেগুলি কেবলমাত্র টেক্সটকে শব্দের "ব্যাগ" (সেট) হিসাবে দেখে (এন-গ্রাম মডেল)। সিকোয়েন্স মডেলের ধরনগুলির মধ্যে রয়েছে কনভোল্যুশনাল নিউরাল নেটওয়ার্ক (CNN), পুনরাবৃত্ত নিউরাল নেটওয়ার্ক (RNN), এবং তাদের বৈচিত্র। এন-গ্রাম মডেলের প্রকারগুলি অন্তর্ভুক্ত করে:
- পণ্য সরবরাহ সংশ্লেষণ
- সাধারণ মাল্টি-লেয়ার পারসেপ্টরন (এমএলপি, বা সম্পূর্ণভাবে সংযুক্ত নিউরাল নেটওয়ার্ক)
- গ্রেডিয়েন্ট বুস্টেড গাছ
- সমর্থন ভেক্টর মেশিন
আমাদের পরীক্ষা থেকে, আমরা লক্ষ্য করেছি যে "নমুনার সংখ্যা" (S) থেকে "নমুনা প্রতি শব্দের সংখ্যা" (W) এর অনুপাত কোন মডেলটি ভাল পারফর্ম করে তার সাথে সম্পর্কযুক্ত।
যখন এই অনুপাতের মান ছোট হয় (<1500), তখন ছোট মাল্টি-লেয়ার পারসেপ্টরন যা n-গ্রামগুলিকে ইনপুট হিসাবে গ্রহণ করে (যাকে আমরা বিকল্প A বলব) আরও ভাল বা কমপক্ষে সেইসাথে সিকোয়েন্স মডেলগুলি সম্পাদন করে। এমএলপিগুলি সংজ্ঞায়িত করা এবং বোঝার জন্য সহজ, এবং তারা সিকোয়েন্স মডেলের তুলনায় অনেক কম গণনা সময় নেয়। যখন এই অনুপাতের মান বড় হয় (>= 1500), একটি সিকোয়েন্স মডেল ব্যবহার করুন ( বিকল্প B )। অনুসরণ করা পদক্ষেপগুলিতে, আপনি নমুনা/শব্দ-প্রতি-নমুনা অনুপাতের উপর ভিত্তি করে যে মডেলটি বেছে নিয়েছেন তার জন্য আপনি প্রাসঙ্গিক উপবিভাগে ( A বা B লেবেলযুক্ত) যেতে পারেন।
আমাদের IMDb পর্যালোচনা ডেটাসেটের ক্ষেত্রে, নমুনা/শব্দ-প্রতি-নমুনা অনুপাত হল ~144৷ এর মানে হল আমরা একটি MLP মডেল তৈরি করব।