আমাদের ডেটা একটি মডেলে খাওয়ানোর আগে, এটিকে মডেলটি বুঝতে পারে এমন একটি বিন্যাসে রূপান্তরিত করা দরকার।
প্রথমত, আমরা যে ডেটা নমুনাগুলি সংগ্রহ করেছি তা একটি নির্দিষ্ট ক্রমে হতে পারে। আমরা পাঠ্য এবং লেবেলের মধ্যে সম্পর্ককে প্রভাবিত করার জন্য নমুনাগুলির অর্ডারের সাথে যুক্ত কোনো তথ্য চাই না। উদাহরণস্বরূপ, যদি একটি ডেটাসেট শ্রেণী অনুসারে বাছাই করা হয় এবং তারপরে প্রশিক্ষণ/বৈধকরণ সেটে বিভক্ত করা হয়, তাহলে এই সেটগুলি ডেটার সামগ্রিক বিতরণের প্রতিনিধি হবে না।
মডেলটি ডেটা অর্ডার দ্বারা প্রভাবিত না হয় তা নিশ্চিত করার জন্য একটি সহজ সর্বোত্তম অনুশীলন হ'ল অন্য কিছু করার আগে সর্বদা ডেটা শাফেল করা। যদি আপনার ডেটা ইতিমধ্যেই প্রশিক্ষণ এবং বৈধতা সেটে বিভক্ত হয়ে থাকে, তাহলে নিশ্চিত করুন যে আপনি আপনার প্রশিক্ষণের ডেটাকে যেভাবে রূপান্তর করেন ঠিক সেভাবে আপনার বৈধতা ডেটা রূপান্তরিত করুন৷ যদি আপনার ইতিমধ্যে আলাদা প্রশিক্ষণ এবং বৈধতা সেট না থাকে, তাহলে আপনি এলোমেলো করার পরে নমুনাগুলিকে বিভক্ত করতে পারেন; প্রশিক্ষণের জন্য নমুনার 80% এবং বৈধতার জন্য 20% ব্যবহার করা সাধারণ।
দ্বিতীয়ত, মেশিন লার্নিং অ্যালগরিদম ইনপুট হিসাবে সংখ্যা গ্রহণ করে। এর মানে হল যে আমাদের পাঠ্যগুলিকে সংখ্যাসূচক ভেক্টরে রূপান্তর করতে হবে। এই প্রক্রিয়ার দুটি ধাপ রয়েছে:
টোকেনাইজেশন : টেক্সটকে শব্দ বা ছোট সাব-টেক্সটে বিভক্ত করুন, যা টেক্সট এবং লেবেলের মধ্যে সম্পর্কের ভালো সাধারণীকরণ সক্ষম করবে। এটি ডেটাসেটের "শব্দভান্ডার" নির্ধারণ করে (ডেটাতে উপস্থিত অনন্য টোকেনের সেট)।
ভেক্টরাইজেশন : এই পাঠ্যগুলিকে চিহ্নিত করার জন্য একটি ভাল সংখ্যাসূচক পরিমাপ সংজ্ঞায়িত করুন।
আসুন দেখি কিভাবে n-গ্রাম ভেক্টর এবং সিকোয়েন্স ভেক্টর উভয়ের জন্য এই দুটি ধাপ সম্পাদন করা যায়, সেইসাথে বৈশিষ্ট্য নির্বাচন এবং স্বাভাবিককরণ কৌশল ব্যবহার করে ভেক্টর উপস্থাপনাগুলিকে কীভাবে অপ্টিমাইজ করা যায়।
এন-গ্রাম ভেক্টর [বিকল্প A]
পরবর্তী অনুচ্ছেদে, আমরা দেখব কিভাবে এন-গ্রাম মডেলের জন্য টোকেনাইজেশন এবং ভেক্টরাইজেশন করতে হয়। বৈশিষ্ট্য নির্বাচন এবং স্বাভাবিকীকরণ কৌশল ব্যবহার করে আমরা কীভাবে n-গ্রাম উপস্থাপনাকে অপ্টিমাইজ করতে পারি তাও আমরা কভার করব।
একটি n-গ্রাম ভেক্টরে, পাঠ্যকে অনন্য n-গ্রামের সংগ্রহ হিসাবে উপস্থাপন করা হয়: n সংলগ্ন টোকেনের গ্রুপ (সাধারণত, শব্দ)। পাঠ্যটি বিবেচনা করুন The mouse ran up the clock । এখানে:
- ইউনিগ্রাম শব্দটি (n = 1) হল
['the', 'mouse', 'ran', 'up', 'clock'] - বিগ্রাম শব্দটি (n = 2) হল
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'] - ইত্যাদি।
টোকেনাইজেশন
আমরা দেখেছি যে শব্দ ইউনিগ্রাম + বিগ্রামে টোকেনাইজ করা কম গণনা করার সময় ভাল নির্ভুলতা প্রদান করে।
ভেক্টরাইজেশন
একবার আমরা আমাদের পাঠ্য নমুনাগুলিকে n-গ্রামে বিভক্ত করার পরে, আমাদের এই n-গ্রামগুলিকে সংখ্যাসূচক ভেক্টরে পরিণত করতে হবে যা আমাদের মেশিন লার্নিং মডেলগুলি প্রক্রিয়া করতে পারে। নীচের উদাহরণটি দুটি পাঠ্যের জন্য উত্পন্ন ইউনিগ্রাম এবং বিগ্রামগুলিতে নির্ধারিত সূচীগুলি দেখায়।
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
একবার এন-গ্রামে সূচী নির্ধারণ করা হলে, আমরা সাধারণত নিম্নলিখিত বিকল্পগুলির মধ্যে একটি ব্যবহার করে ভেক্টরাইজ করি।
ওয়ান-হট এনকোডিং : প্রতিটি নমুনা পাঠ্যকে একটি ভেক্টর হিসাবে উপস্থাপন করা হয় যা পাঠ্যে একটি টোকেনের উপস্থিতি বা অনুপস্থিতি নির্দেশ করে।
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
কাউন্ট এনকোডিং : প্রতিটি নমুনা পাঠ্যকে একটি ভেক্টর হিসাবে উপস্থাপন করা হয় যা পাঠ্যে একটি টোকেনের গণনা নির্দেশ করে। উল্লেখ্য যে unigram 'the'-এর সাথে সংশ্লিষ্ট উপাদানটিকে এখন 2 হিসেবে উপস্থাপন করা হয়েছে কারণ টেক্সটে "the" শব্দটি দুবার দেখা যাচ্ছে।
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
Tf-idf এনকোডিং : উপরের দুটি পদ্ধতির সমস্যা হল যে সাধারণ শব্দগুলি যা সমস্ত নথিতে একই রকম ফ্রিকোয়েন্সিতে ঘটে (অর্থাৎ, ডেটাসেটে পাঠ্য নমুনার জন্য বিশেষভাবে অনন্য নয়) শব্দগুলিকে শাস্তি দেওয়া হয় না৷ উদাহরণস্বরূপ, "a" এর মতো শব্দগুলি সমস্ত পাঠ্যগুলিতে খুব ঘন ঘন ঘটবে৷ তাই অন্যান্য আরও অর্থপূর্ণ শব্দের তুলনায় "the" এর জন্য একটি উচ্চতর টোকেন গণনা খুব দরকারী নয়।
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
( Sikit-learn TfidfTransformer দেখুন)
অন্যান্য অনেক ভেক্টর উপস্থাপনা আছে, কিন্তু পূর্ববর্তী তিনটি সবচেয়ে বেশি ব্যবহৃত হয়।
আমরা লক্ষ্য করেছি যে tf-idf এনকোডিং নির্ভুলতার পরিপ্রেক্ষিতে অন্য দুটির চেয়ে সামান্য ভাল (গড়ে: 0.25-15% বেশি), এবং n-গ্রামগুলিকে ভেক্টরাইজ করার জন্য এই পদ্ধতিটি ব্যবহার করার পরামর্শ দিই। যাইহোক, মনে রাখবেন যে এটি আরও মেমরি দখল করে (যেহেতু এটি ফ্লোটিং-পয়েন্ট উপস্থাপনা ব্যবহার করে) এবং গণনা করতে আরও সময় নেয়, বিশেষত বড় ডেটাসেটের জন্য (কিছু ক্ষেত্রে দ্বিগুণ সময় লাগতে পারে)।
বৈশিষ্ট্য নির্বাচন
যখন আমরা একটি ডেটাসেটের সমস্ত টেক্সটকে ওয়ার্ড ইউনি+বিগ্রাম টোকেনে রূপান্তর করি, তখন আমরা কয়েক হাজার টোকেন দিয়ে শেষ করতে পারি। এই সমস্ত টোকেন/বৈশিষ্ট্য লেবেল ভবিষ্যদ্বাণীতে অবদান রাখে না। তাই আমরা নির্দিষ্ট টোকেন ড্রপ করতে পারি, উদাহরণস্বরূপ যেগুলি ডেটাসেট জুড়ে খুব কমই ঘটে। এছাড়াও আমরা বৈশিষ্ট্যের গুরুত্ব পরিমাপ করতে পারি (প্রত্যেকটি টোকেন লেবেল ভবিষ্যদ্বাণীতে কতটা অবদান রাখে), এবং শুধুমাত্র সবচেয়ে তথ্যপূর্ণ টোকেন অন্তর্ভুক্ত করি।
অনেক পরিসংখ্যানগত ফাংশন রয়েছে যা বৈশিষ্ট্য এবং সংশ্লিষ্ট লেবেলগুলি নেয় এবং বৈশিষ্ট্যের গুরুত্ব স্কোর আউটপুট করে। দুটি সাধারণভাবে ব্যবহৃত ফাংশন হল f_classif এবং chi2 । আমাদের পরীক্ষাগুলি দেখায় যে এই দুটি ফাংশনই সমানভাবে ভাল কাজ করে।
আরও গুরুত্বপূর্ণ, আমরা দেখেছি যে অনেক ডেটাসেটের জন্য নির্ভুলতা প্রায় 20,000 বৈশিষ্ট্যে পৌঁছেছে ( চিত্র 6 দেখুন)। এই থ্রেশহোল্ডে আরও বৈশিষ্ট্য যুক্ত করা খুব কম অবদান রাখে এবং কখনও কখনও এমনকি অতিরিক্ত ফিটিং এবং কর্মক্ষমতা হ্রাস করে।

চিত্র 6: শীর্ষ K বৈশিষ্ট্য বনাম যথার্থতা । ডেটাসেট জুড়ে, প্রায় 20K বৈশিষ্ট্যে যথার্থতা মালভূমি।
স্বাভাবিককরণ
সাধারণীকরণ সমস্ত বৈশিষ্ট্য/নমুনা মানকে ছোট এবং অনুরূপ মানগুলিতে রূপান্তর করে। এটি অ্যালগরিদম শেখার ক্ষেত্রে গ্রেডিয়েন্ট ডিসেন্ট কনভারজেন্সকে সহজ করে। আমরা যা দেখেছি তা থেকে, ডেটা প্রিপ্রসেসিংয়ের সময় স্বাভাবিককরণ পাঠ্য শ্রেণিবিন্যাসের সমস্যাগুলিতে খুব বেশি মূল্য যোগ করে বলে মনে হয় না; আমরা এই ধাপটি এড়িয়ে যাওয়ার পরামর্শ দিই।
নিম্নলিখিত কোডটি উপরের সমস্ত পদক্ষেপগুলিকে একত্রিত করে:
- টেক্সট নমুনাকে শব্দ ইউনি+বিগ্রামে টোকেনাইজ করুন,
- tf-idf এনকোডিং ব্যবহার করে ভেক্টরাইজ করুন,
- টোকেনগুলির ভেক্টর থেকে শুধুমাত্র শীর্ষ 20,000 বৈশিষ্ট্যগুলি নির্বাচন করুন যা 2 বারের কম প্রদর্শিত টোকেনগুলি বাতিল করে এবং বৈশিষ্ট্যের গুরুত্ব গণনা করতে f_classif ব্যবহার করে৷
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
n-গ্রাম ভেক্টর প্রতিনিধিত্বের সাথে, আমরা শব্দের ক্রম এবং ব্যাকরণ সম্পর্কে অনেক তথ্য বাতিল করি (সর্বোত্তমভাবে, আমরা কিছু আংশিক ক্রম তথ্য বজায় রাখতে পারি যখন n > 1)। একে বলা হয় ব্যাগ-অফ-শব্দ পদ্ধতি। লজিস্টিক রিগ্রেশন, মাল্টি-লেয়ার পারসেপ্টরন, গ্রেডিয়েন্ট বুস্টিং মেশিন, সাপোর্ট ভেক্টর মেশিনের মতো ক্রমকে বিবেচনা করে না এমন মডেলগুলির সাথে এই উপস্থাপনাটি ব্যবহার করা হয়।
সিকোয়েন্স ভেক্টর [বিকল্প B]
পরবর্তী অনুচ্ছেদে, আমরা দেখব কিভাবে সিকোয়েন্স মডেলের জন্য টোকেনাইজেশন এবং ভেক্টরাইজেশন করতে হয়। বৈশিষ্ট্য নির্বাচন এবং স্বাভাবিকীকরণ কৌশল ব্যবহার করে আমরা কীভাবে ক্রম উপস্থাপনাকে অপ্টিমাইজ করতে পারি তাও আমরা কভার করব।
কিছু পাঠ্য নমুনার জন্য, শব্দ ক্রম পাঠ্যের অর্থের জন্য গুরুত্বপূর্ণ। উদাহরণস্বরূপ, বাক্য, “আমি আমার যাতায়াতকে ঘৃণা করতাম। আমার নতুন বাইকটি সম্পূর্ণ পরিবর্তন হয়েছে” শুধুমাত্র ক্রমানুসারে পড়লেই বোঝা যাবে। সিএনএন/আরএনএন-এর মতো মডেল একটি নমুনায় শব্দের ক্রম থেকে অর্থ অনুমান করতে পারে। এই মডেলগুলির জন্য, আমরা টোকেনগুলির একটি ক্রম হিসাবে পাঠ্যটিকে উপস্থাপন করি, অর্ডার সংরক্ষণ করে।
টোকেনাইজেশন
পাঠ্যকে অক্ষরের ক্রম বা শব্দের ক্রম হিসাবে উপস্থাপন করা যেতে পারে। আমরা খুঁজে পেয়েছি যে শব্দ-স্তরের উপস্থাপনা ব্যবহার করে অক্ষর টোকেনগুলির চেয়ে ভাল কার্যক্ষমতা প্রদান করে। এটিও সাধারণ নিয়ম যা শিল্প দ্বারা অনুসরণ করা হয়। অক্ষর টোকেন ব্যবহার করা তখনই বোধগম্য হয় যদি টেক্সটে প্রচুর টাইপো থাকে, যা সাধারণত হয় না।
ভেক্টরাইজেশন
একবার আমরা আমাদের পাঠ্য নমুনাগুলিকে শব্দের ক্রমগুলিতে রূপান্তরিত করার পরে, আমাদের এই ক্রমগুলিকে সংখ্যাসূচক ভেক্টরে পরিণত করতে হবে। নীচের উদাহরণটি দুটি পাঠ্যের জন্য উত্পন্ন ইউনিগ্রামে বরাদ্দকৃত সূচীগুলি দেখায় এবং তারপর টোকেন সূচির ক্রম যেখানে প্রথম পাঠটি রূপান্তরিত হয়।
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
প্রতিটি টোকেনের জন্য নির্ধারিত সূচক:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
দ্রষ্টব্য: "the" শব্দটি প্রায়শই ঘটে, তাই এটিতে 1 এর সূচক মান নির্ধারণ করা হয়। কিছু লাইব্রেরি অজানা টোকেনগুলির জন্য সূচক 0 সংরক্ষণ করে, যেমনটি এখানে রয়েছে।
টোকেন সূচকের ক্রম:
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
টোকেন সিকোয়েন্সগুলিকে ভেক্টরাইজ করার জন্য দুটি বিকল্প উপলব্ধ রয়েছে:
এক-হট এনকোডিং : n-মাত্রিক স্থান যেখানে n = শব্দভান্ডারের আকার থাকে সেখানে শব্দ ভেক্টর ব্যবহার করে সিকোয়েন্সগুলি উপস্থাপন করা হয়। এই উপস্থাপনাটি দুর্দান্ত কাজ করে যখন আমরা অক্ষর হিসাবে টোকেনাইজ করি, এবং শব্দভাণ্ডারটি তাই ছোট। যখন আমরা শব্দ হিসাবে টোকেনাইজ করি, তখন শব্দভাণ্ডারে সাধারণত হাজার হাজার টোকেন থাকে, যা এক-উষ্ণ ভেক্টরকে খুব বিরল এবং অদক্ষ করে তোলে। উদাহরণ:
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
শব্দ এম্বেডিং : শব্দের অর্থ(গুলি) তাদের সাথে যুক্ত। ফলস্বরূপ, আমরা একটি ঘন ভেক্টর স্পেসে শব্দ টোকেন উপস্থাপন করতে পারি (~কয়েক শত বাস্তব সংখ্যা), যেখানে শব্দের মধ্যে অবস্থান এবং দূরত্ব নির্দেশ করে যে তারা শব্দার্থগতভাবে কতটা একই রকম ( চিত্র 7 দেখুন)। এই উপস্থাপনাকে শব্দ এমবেডিং বলা হয়।
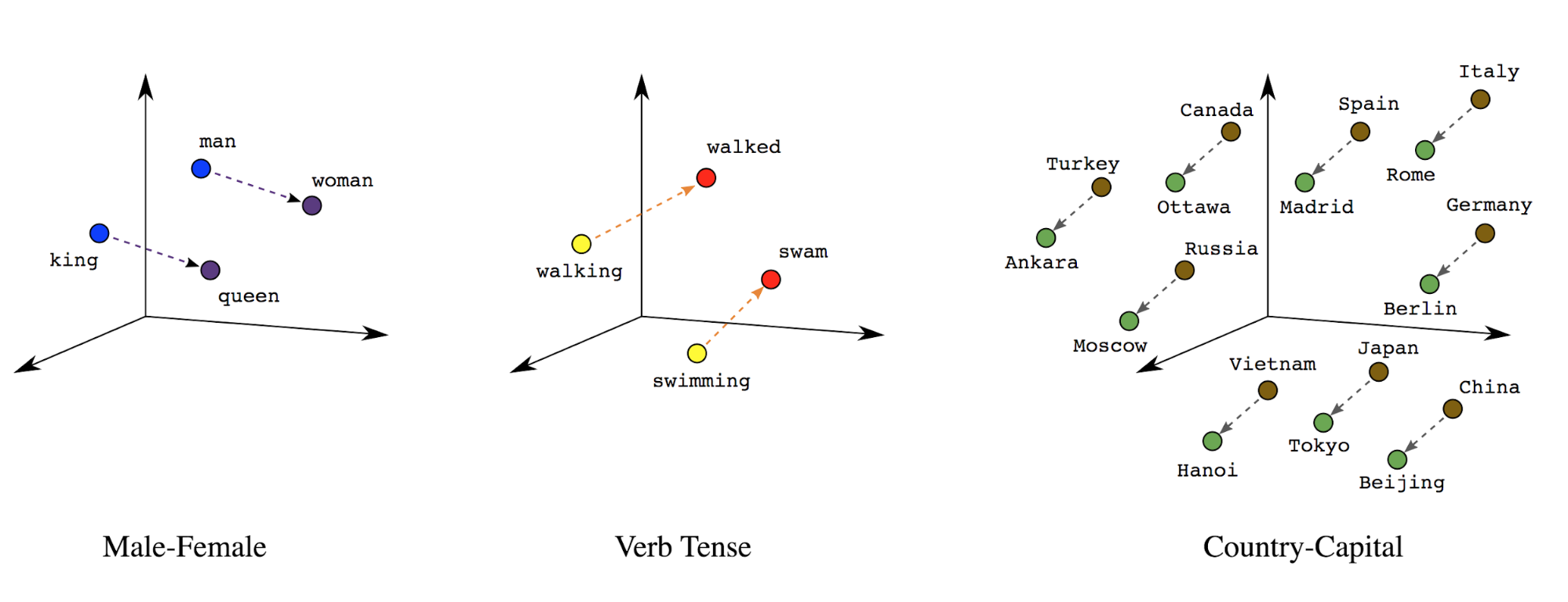
চিত্র 7: শব্দ এমবেডিং
সিকোয়েন্স মডেলগুলিতে প্রায়শই তাদের প্রথম স্তর হিসাবে এম্বেডিং স্তর থাকে। এই স্তরটি প্রশিক্ষণ প্রক্রিয়ার সময় শব্দ সূচকের ক্রমগুলিকে শব্দ এমবেডিং ভেক্টরে পরিণত করতে শেখে, যাতে প্রতিটি শব্দ সূচক বাস্তব মানের একটি ঘন ভেক্টরের সাথে ম্যাপ করা হয় যা শব্দার্থগত স্থানে সেই শব্দের অবস্থানকে প্রতিনিধিত্ব করে ( চিত্র 8 দেখুন)।
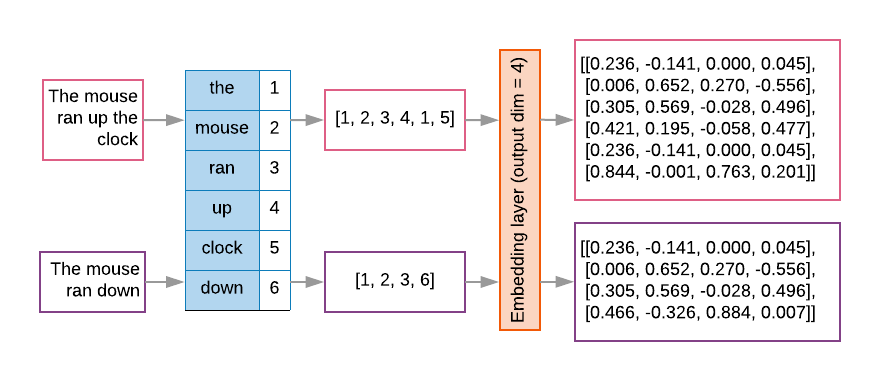
চিত্র 8: এম্বেডিং স্তর
বৈশিষ্ট্য নির্বাচন
আমাদের ডেটার সমস্ত শব্দ লেবেল ভবিষ্যদ্বাণীতে অবদান রাখে না। আমরা আমাদের শব্দভাণ্ডার থেকে বিরল বা অপ্রাসঙ্গিক শব্দ বাদ দিয়ে আমাদের শেখার প্রক্রিয়াটিকে অপ্টিমাইজ করতে পারি। প্রকৃতপক্ষে, আমরা লক্ষ্য করি যে সর্বাধিক ঘন ঘন 20,000 বৈশিষ্ট্যগুলি ব্যবহার করা সাধারণত যথেষ্ট। এটি এন-গ্রাম মডেলের জন্যও সত্য ( চিত্র 6 দেখুন)।
ক্রম ভেক্টরাইজেশনে উপরের সমস্ত ধাপগুলি একসাথে রাখা যাক। নিম্নলিখিত কোড এই কাজগুলি সম্পাদন করে:
- টেক্সটকে শব্দে টোকেনাইজ করে
- শীর্ষ 20,000 টোকেন ব্যবহার করে একটি শব্দভাণ্ডার তৈরি করে
- টোকেনকে সিকোয়েন্স ভেক্টরে রূপান্তর করে
- ক্রমগুলিকে একটি নির্দিষ্ট ক্রম দৈর্ঘ্যে প্যাড করে
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
লেবেল ভেক্টরাইজেশন
আমরা দেখেছি কিভাবে নমুনা টেক্সট ডেটাকে সংখ্যাসূচক ভেক্টরে রূপান্তর করা যায়। একটি অনুরূপ প্রক্রিয়া লেবেল প্রয়োগ করা আবশ্যক. আমরা সহজভাবে লেবেলগুলিকে পরিসরের মানগুলিতে রূপান্তর করতে পারি [0, num_classes - 1] । উদাহরণস্বরূপ, যদি 3টি ক্লাস থাকে আমরা তাদের প্রতিনিধিত্ব করার জন্য শুধুমাত্র 0, 1 এবং 2 মান ব্যবহার করতে পারি। অভ্যন্তরীণভাবে, নেটওয়ার্ক এই মানগুলিকে উপস্থাপন করতে এক-হট ভেক্টর ব্যবহার করবে (লেবেলের মধ্যে একটি ভুল সম্পর্ক অনুমান করা এড়াতে)। এই উপস্থাপনা নির্ভর করে লস ফাংশন এবং আমাদের নিউরাল নেটওয়ার্কে আমরা যে শেষ-স্তর অ্যাক্টিভেশন ফাংশন ব্যবহার করি তার উপর। আমরা পরবর্তী বিভাগে এগুলি সম্পর্কে আরও জানব।