Objectif
Le tutoriel Validation d'adresses à volume élevé vous a présenté différents scénarios dans lesquels la validation d'adresses à volume élevé peut être utilisée. Dans ce tutoriel, nous allons vous présenter différents modèles de conception dans Google Cloud Platform pour exécuter la validation d'adresses à volume élevé.
Nous commencerons par vous donner un aperçu de l'exécution de la validation d'adresses à volume élevé dans Google Cloud Platform avec Cloud Run, Compute Engine ou Google Kubernetes Engine pour les exécutions ponctuelles. Nous verrons ensuite comment inclure cette fonctionnalité dans un pipeline de données.
À la fin de cet article, vous devriez bien comprendre les différentes options permettant d'exécuter la validation d'adresse à volume élevé dans votre environnement Google Cloud.
Architecture de référence sur Google Cloud Platform
Cette section présente plus en détail différents modèles de conception pour la validation d'adresses à volume élevé à l'aide de Google Cloud Platform. En s'exécutant sur Google Cloud Platform, vous pouvez l'intégrer à vos processus et pipelines de données existants.
Exécuter la validation d'adresses à volume élevé une seule fois sur Google Cloud Platform
Vous trouverez ci-dessous une architecture de référence illustrant comment construire une intégration sur Google Cloud Platform, plus adaptée aux opérations ponctuelles ou aux tests.

Dans ce cas, nous vous recommandons d'importer le fichier CSV dans un bucket Cloud Storage. Le script de validation d'adresses à volume élevé peut ensuite être exécuté à partir d'un environnement Cloud Run. Toutefois, vous pouvez l'exécuter dans n'importe quel autre environnement d'exécution, comme Compute Engine ou Google Kubernetes Engine. Le fichier CSV de sortie peut également être importé dans le bucket Cloud Storage.
Exécuter en tant que pipeline de données Google Cloud Platform
Le modèle de déploiement présenté dans la section précédente est idéal pour tester rapidement la validation d'adresses à volume élevé pour une utilisation unique. Toutefois, si vous devez l'utiliser régulièrement dans un pipeline de données, vous pouvez mieux exploiter les fonctionnalités natives de Google Cloud Platform pour le rendre plus robuste. Voici quelques exemples de modifications que vous pouvez apporter :
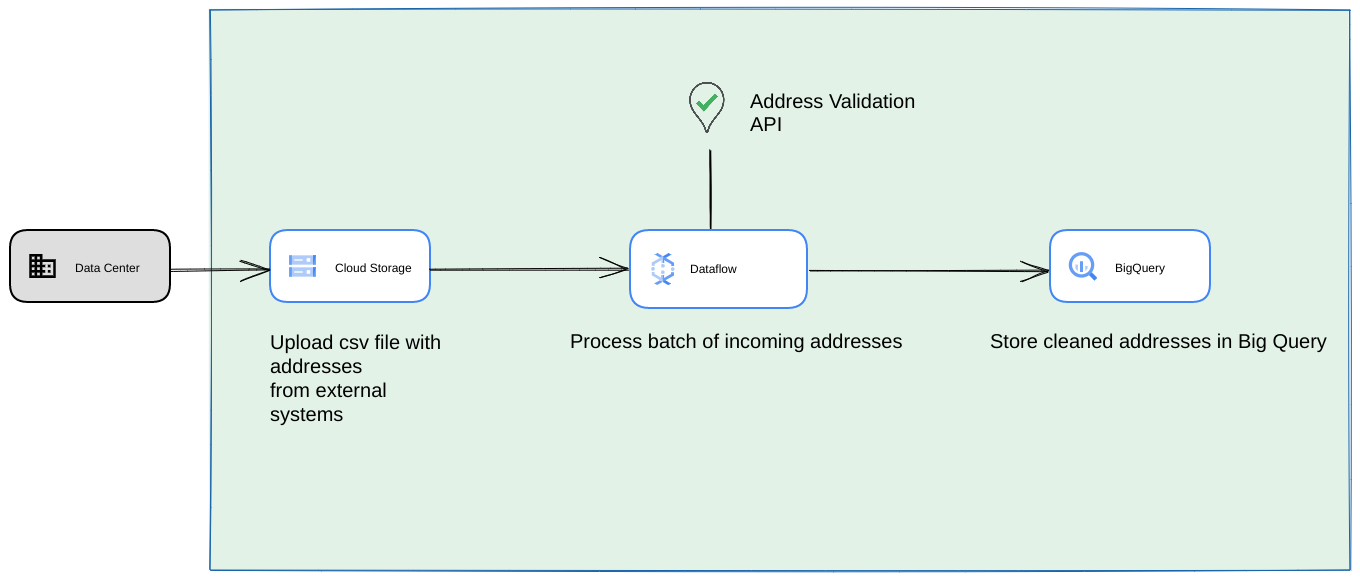
- Dans ce cas, vous pouvez vider les fichiers CSV dans des buckets Cloud Storage.
- Une tâche Dataflow peut récupérer les adresses à traiter, puis les mettre en cache dans BigQuery.
- La bibliothèque Python Dataflow peut être étendue pour inclure une logique de validation des adresses à volume élevé afin de valider les adresses de la tâche Dataflow.
Exécuter le script à partir d'un pipeline de données en tant que processus récurrent de longue durée
Une autre approche courante consiste à valider un lot d'adresses dans le cadre d'un pipeline de flux de données en tant que processus récurrent. Vous pouvez également avoir les adresses dans un datastore BigQuery. Dans cette approche, nous allons voir comment créer un pipeline de données récurrent (qui doit être déclenché quotidiennement/hebdomadairement/mensuellement).
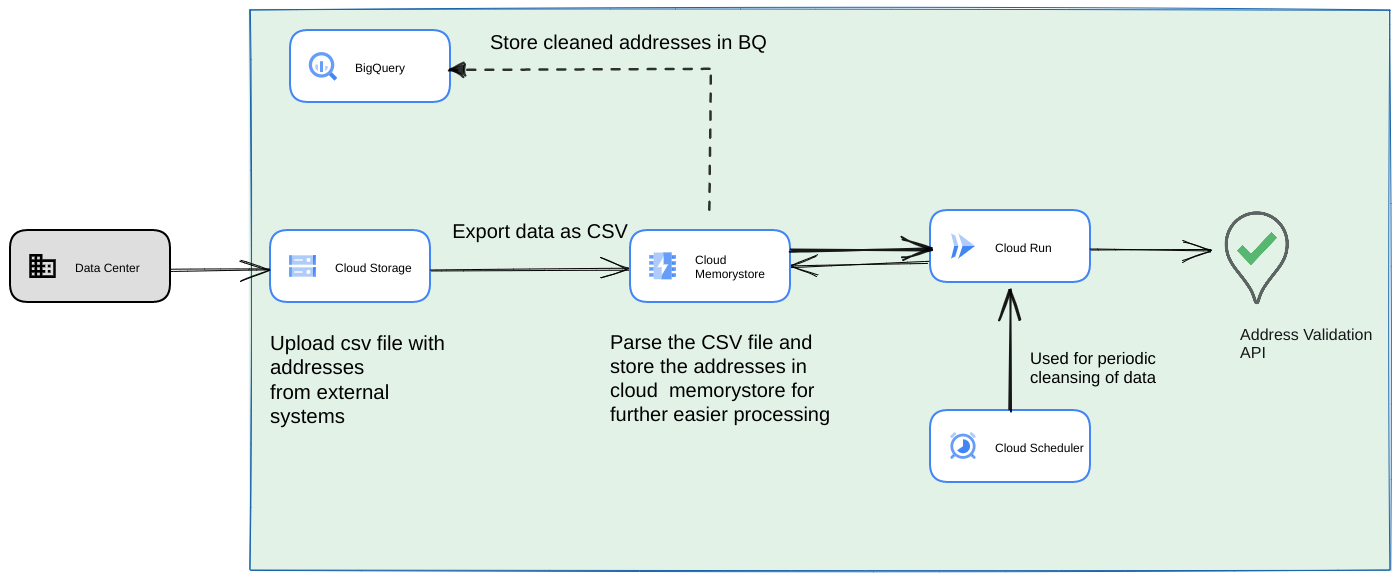
- Importez le fichier CSV initial dans un bucket Cloud Storage.
- Utilisez Memorystore comme data store persistant pour conserver l'état intermédiaire du processus de longue durée.
- Mettez en cache les adresses finales dans un data store BigQuery.
- Configurez Cloud Scheduler pour exécuter le script périodiquement.
Cette architecture présente les avantages suivants :
- La validation des adresses peut être effectuée périodiquement à l'aide de Cloud Scheduler. Vous pouvez revalider les adresses tous les mois ou valider les nouvelles adresses tous les mois ou tous les trimestres. Cette architecture permet de résoudre ce cas d'utilisation.
Si les données client se trouvent dans BigQuery, les adresses validées ou les indicateurs de validation peuvent y être mis en cache directement. Remarque : L'article Validation d'adresses à volume élevé décrit en détail ce qui peut être mis en cache et comment.
L'utilisation de Memorystore offre une résilience plus élevée et permet de traiter davantage d'adresses. Cette étape ajoute un état à l'ensemble du pipeline de traitement, ce qui est nécessaire pour gérer de très grands ensembles de données d'adresses. Vous pouvez également utiliser d'autres technologies de base de données, comme Cloud SQL[https://cloud.google.com/sql] ou toute autre version de base de données proposée par Google Cloud Platform. Toutefois, nous pensons que Memorystore sans serveur équilibre parfaitement les besoins de mise à l'échelle et de simplicité, et devrait donc être le premier choix.
Conclusion
En appliquant les modèles décrits ici, vous pouvez utiliser l'API Address Validation pour différents cas d'utilisation et à partir de différents cas d'utilisation sur Google Cloud Platform.
Nous avons écrit une bibliothèque Python open source pour vous aider à vous lancer avec les cas d'utilisation décrits ci-dessus. Il peut être appelé à partir d'une ligne de commande sur votre ordinateur ou à partir de Google Cloud Platform ou d'autres fournisseurs de services cloud.
Pour en savoir plus sur l'utilisation de la bibliothèque, consultez cet article.
Étapes suivantes
Téléchargez le livre blanc sur l'amélioration des processus de paiement, de livraison et des opérations grâce à des adresses fiables et regardez le webinaire sur l'amélioration des processus de paiement, de livraison et des opérations grâce à la validation d'adresse .
Lectures complémentaires suggérées :
- Documentation de l'API Address Validation
- Géocodage et validation d'adresse
- Explorer la démonstration Address Validation
Contributeurs
Google gère cet article. Les contributeurs suivants en sont les auteurs originaux.
Auteurs principaux :
Henrik Valve | Ingénieur solutions
Thomas Anglaret | Ingénieur solutions
Sarthak Ganguly | Ingénieur solutions