Places Insights 데이터에 액세스하려면 BigQuery에서 장소에 관한 집계된 유용한 정보를 반환하는 SQL 쿼리를 작성합니다. 결과는 쿼리에 지정된 검색 기준의 데이터 세트에서 반환됩니다.
쿼리 기본사항
다음 이미지는 쿼리의 기본 형식을 보여줍니다.

쿼리의 각 부분은 아래에서 자세히 설명합니다.
쿼리 요구사항
쿼리의 SELECT 문에는 WITH AGGREGATION_THRESHOLD이 포함되어야 하고 데이터 세트를 지정해야 합니다. 예를 들면 다음과 같습니다.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`
이 예에서는 FROM를 사용하여 미국에 대한 places_insights___us.places 데이터 세트를 지정합니다.
프로젝트 이름을 지정하세요 (선택 사항)
원하는 경우 쿼리에 프로젝트 이름을 포함할 수 있습니다. 프로젝트 이름을 지정하지 않으면 쿼리는 기본적으로 활성 프로젝트로 설정됩니다.
서로 다른 프로젝트에 이름이 동일한 데이터 세트를 연결했거나 활성 프로젝트 외부에서 테이블을 쿼리하는 경우 프로젝트 이름을 포함하는 것이 좋습니다.
예를 들면 [project name].[dataset name].places입니다.
집계 함수 지정
아래 예에서는 지원되는 BigQuery 집계 함수를 보여줍니다. 이 쿼리는 뉴욕시의 엠파이어 스테이트 빌딩 반경 1000m 이내에 있는 모든 장소의 평가를 집계하여 평가 통계를 생성합니다.
SELECT WITH AGGREGATION_THRESHOLD COUNT(id) AS place_count, APPROX_COUNT_DISTINCT(rating) as distinct_ratings, COUNTIF(rating > 4.0) as good_rating_count, LOGICAL_AND(rating <= 5) as all_ratings_equal_or_below_five, LOGICAL_OR(rating = 5) as any_rating_exactly_five, AVG(rating) as avg_rating, SUM(user_rating_count) as rating_count, COVAR_POP(rating, user_rating_count) as rating_covar_pop, COVAR_SAMP(rating, user_rating_count) as rating_covar_samp, STDDEV_POP(rating) as rating_stddev_pop, STDDEV_SAMP(rating) as rating_stddev_samp, VAR_POP(rating) as rating_var_pop, VAR_SAMP(rating) as rating_var_samp, FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND business_status = "OPERATIONAL"
위치 제한 지정
위치 제한을 지정하지 않으면 데이터 집계가 전체 데이터 세트에 적용됩니다. 일반적으로 아래와 같이 특정 영역을 검색하기 위해 위치 제한을 지정합니다.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000)
이 예에서 쿼리는 뉴욕의 엠파이어 스테이트 빌딩을 중심으로 하고 반지름이 1,000미터인 타겟 제한을 지정합니다.
다각형을 사용하여 검색 영역을 지정할 수 있습니다. 다각형을 사용하는 경우 다각형의 점은 다각형의 첫 번째 점이 마지막 점과 동일한 닫힌 루프를 정의해야 합니다.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_CONTAINS(ST_GEOGFROMTEXT("""POLYGON((-73.985708 40.75773,-73.993324 40.750298, -73.9857 40.7484,-73.9785 40.7575, -73.985708 40.75773))"""), point)
다음 예에서는 연결된 점의 선을 사용하여 검색 영역을 정의합니다. 이 노선은 Routes API에서 계산된 여행 경로와 유사합니다. 경로는 차량, 자전거 또는 보행자를 위한 것일 수 있습니다.
DECLARE route GEOGRAPHY; SET route = ST_GEOGFROMTEXT("""LINESTRING(-73.98903537033028 40.73655649223003, -73.93580216278471 40.80955538843361)"""); SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(route, point, 100)
이 예에서는 선을 중심으로 검색 반경을 100미터로 설정합니다.
장소 데이터 세트 필드로 필터링
데이터세트 스키마에 정의된 필드를 기준으로 검색을 구체화합니다. 장소 regular_opening_hours, price_level, 고객 rating 등의 데이터 세트 필드를 기준으로 결과를 필터링합니다.
관심 국가의 데이터 세트 스키마에 정의된 데이터 세트의 필드를 참조합니다. 각 국가의 데이터 세트 스키마는 두 부분으로 구성됩니다.
예를 들어, 쿼리에는 쿼리의 필터링 기준을 정의하는 WHERE 절을 포함할 수 있습니다. 다음 예에서는 OPERATIONAL의 business_status이 있고, rating이 4.0 이상이며, allows_dogs이 true로 설정된 tourist_attraction 유형의 장소에 대한 집계 데이터를 반환합니다.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND 'tourist_attraction' IN UNNEST(types) AND business_status = "OPERATIONAL" AND rating >= 4.0 AND allows_dogs = true
다음 쿼리는 전기 자동차 충전소가 8개 이상 있는 장소의 결과를 반환합니다.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ev_charge_options.connector_count > 8;
장소 기본 유형 및 장소 유형을 기준으로 필터링
데이터 세트의 각 위치는 다음을 가질 수 있습니다.
장소 유형에서 정의된 유형과 연관된 단일 기본 유형입니다. 예를 들어 기본 유형은
mexican_restaurant또는steak_house일 수 있습니다. 쿼리에서primary_type를 사용하여 장소의 기본 유형에 대한 결과를 필터링합니다.장소 유형에서 정의된 유형과 연관된 여러 유형 값입니다. 예를 들어 레스토랑에는 다음과 같은 유형이 있을 수 있습니다:
seafood_restaurant,restaurant,food,point_of_interest,establishment.types를 쿼리에 사용하여 장소와 관련된 유형 목록에서 결과를 필터링합니다.
다음 쿼리는 기본 유형이 skin_care_clinic이고 spa으로도 기능하는 모든 장소의 결과를 반환합니다.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE 'spa' IN UNNEST(types) AND 'skin_care_clinic' = primary_type
장소 ID로 필터링
아래 예에서는 5개 장소의 평균 평점을 계산합니다. 장소는 place_id로 식별됩니다.
DECLARE place_ids ARRAY<STRING>; SET place_ids = ['ChIJPQOh8YVZwokRE2WsbZI4tOk', 'ChIJibtT3ohZwokR7tX0gp0nG8U', 'ChIJdfD8moVZwokRO6vxjXAtoWs', 'ChIJsdNONuFbwokRLM-yuifjb8k', 'ChIJp0gKoClawokR0txqrcaEkFc']; SELECT WITH AGGREGATION_THRESHOLD AVG(rating) as avg_rating, FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(place_ids) place_id WHERE id = place_id;
특정 장소 ID 필터링
장소 ID 배열을 쿼리에서 제외할 수도 있습니다.
장소 ID 찾기를 사용하거나 프로그래밍 방식으로 장소 API를 사용하여 텍스트 검색 (신규) 요청을 수행하여 원하는 장소 ID를 찾을 수 있습니다.
아래 예에서 쿼리는 excluded_cafes 배열에 표시되지 않는 오스트레일리아 시드니의 우편번호 2000에 있는 카페의 수를 찾습니다. 이러한 쿼리는 자신의 사업을 조사에서 제외하려는 사업주에게 유용할 수 있습니다.
WITH excluded_cafes AS ( -- List the specific place IDs to exclude from the final count SELECT * FROM UNNEST([ 'ChIJLTcYGz-uEmsRmazk9oMnP5w', 'ChIJeWDDDNOvEmsRF8SMPUwPbhw', 'ChIJKdaKHbmvEmsRSdxq_1O05bU' ]) AS place_id ) SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `places_insights___au.places` AS places -- Perform a LEFT JOIN to identify which places are in the exclusion list LEFT JOIN excluded_cafes ON places.id = excluded_cafes.place_id WHERE -- Filter for specific place type and postal code places.primary_type = 'cafe' AND '2000' IN UNNEST(places.postal_code_names) -- Keep only the rows where the join failed (meaning the ID was NOT in the list) AND excluded_cafes.place_id IS NULL;
미리 정의된 데이터 값에 대한 필터링
많은 데이터 세트 필드에는 미리 정의된 값이 있습니다. 예를 들면 다음과 같습니다.
price_level필드는 다음과 같은 미리 정의된 값을 지원합니다.PRICE_LEVEL_FREEPRICE_LEVEL_INEXPENSIVEPRICE_LEVEL_MODERATEPRICE_LEVEL_EXPENSIVEPRICE_LEVEL_VERY_EXPENSIVE
business_status필드는 다음과 같은 미리 정의된 값을 지원합니다.OPERATIONALCLOSED_TEMPORARILYCLOSED_PERMANENTLY
이 예에서 쿼리는 뉴욕시의 엠파이어 스테이트 빌딩 반경 1000m 이내에 있는 business_status가 OPERATIONAL인 모든 꽃집의 수를 반환합니다.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000) AND business_status = "OPERATIONAL" AND 'florist' IN UNNEST(types)
운영 시간별로 필터링
이 예에서는 금요일 해피 아워가 있는 특정 지역의 모든 장소 개수를 반환합니다.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(regular_opening_hours_happy_hour.friday) AS friday_hours WHERE '17:00:00' BETWEEN friday_hours.start_time AND friday_hours.end_time AND ST_DWITHIN(ST_GEOGPOINT(-73.9857, 40.7484), point, 1000);
지역별 필터링 (주소 구성요소)
장소 데이터 세트에는 정치적 경계를 기반으로 결과를 필터링하는 데 유용한 주소 구성요소도 포함되어 있습니다. 각 주소 구성요소는 텍스트 코드 이름 (NYC의 우편번호는 10002) 또는 해당 우편번호 ID의 장소 ID(ChIJm5NfgIBZwokR6jLqucW0ipg)로 식별됩니다.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE '10002' IN UNNEST(postal_code_names) --- 'ChIJm5NfgIBZwokR6jLqucW0ipg' IN UNNEST(postal_code_ids) -- same filter as above using postal code ID
전기 자동차 충전으로 필터링
이 예에서는 전기차 충전기가 8개 이상인 장소의 수를 제공합니다.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ev_charge_options.connector_count > 8;
이 예에서는 빠른 충전을 지원하는 테슬라 충전기가 10개 이상 있는 장소의 수를 계산합니다.
SELECT WITH AGGREGATION_THRESHOLD COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places`, UNNEST(ev_charge_options.connector_aggregation) as connectors WHERE connectors.type ='EV_CONNECTOR_TYPE_TESLA' AND connectors.max_charge_rate_kw >= 50 AND connectors.count >= 10
결과 그룹 반환
지금까지 표시된 쿼리는 쿼리에 대한 집계 횟수를 포함하는 단일 행을 결과로 반환합니다. GROUP BY 연산자를 사용하여 그룹화 기준에 따라 응답에서 여러 행을 반환할 수도 있습니다.
예를 들어 다음 쿼리는 검색 영역에 있는 각 장소의 기본 유형별로 그룹화된 결과를 반환합니다.
SELECT WITH AGGREGATION_THRESHOLD primary_type, COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` WHERE ST_DWITHIN(ST_GEOGPOINT(-73.99992071622756, 40.71818785986936), point, 1000) GROUP BY primary_type
다음 이미지는 이 쿼리의 출력 예시를 보여줍니다.

이 예에서는 위치 테이블을 정의합니다. 그런 다음 각 위치에 대해 근처에 있는 음식점(1, 000미터 이내)의 수를 계산합니다.
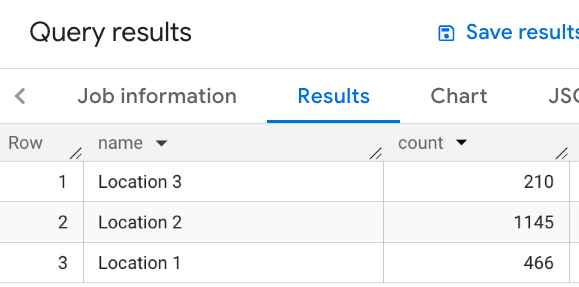
WITH my_locations AS ( SELECT 'Location 1' AS name, ST_GEOGPOINT(-74.00776440888504, 40.70932825380786) AS location UNION ALL SELECT 'Location 2' AS name, ST_GEOGPOINT(-73.98257192833559, 40.750738934863215) AS location UNION ALL SELECT 'Location 3' AS name, ST_GEOGPOINT(-73.94701794263223, 40.80792954838445) AS location ) SELECT WITH AGGREGATION_THRESHOLD l.name, COUNT(*) as count FROM `PROJECT_NAME.places_insights___us.places` JOIN my_locations l ON ST_DWITHIN(l.location, p.point, 1000) WHERE primary_type = "restaurant" AND business_status = "OPERATIONAL" GROUP BY l.name
다음 이미지는 이 쿼리의 출력 예시를 보여줍니다.