במדריך הקודם (מבוא), ראינו איך הטמעות של נתוני לוויין מתעדות מסלולים שנתיים של תצפיות לוויין ומשתני אקלים. כך קל להשתמש במערך הנתונים למיפוי גידולים בלי צורך ליצור מודל של פנולוגיה של גידולים. מיפוי סוגי הגידולים הוא משימה מאתגרת שבדרך כלל דורשת מידול של הפנוולוגיה של הגידולים ואיסוף דגימות מהשטח של כל הגידולים שגדלים באזור.
במדריך הזה נשתמש בגישה של סיווג לא מפוקח למיפוי של גידולים, שתאפשר לנו לבצע את המשימה המורכבת הזו בלי להסתמך על תוויות של שדות. השיטה הזו מתבססת על ידע מקומי לגבי האזור ועל נתונים סטטיסטיים מצטברים לגבי היבול, שזמינים בקלות לגבי חלקים רבים בעולם.
בחירת אזור
במדריך הזה ניצור מפה של סוגי הגידולים במחוז סרו גורדו באיווה. המחוז הזה נמצא באזור גידול התירס בארצות הברית, שבו שני גידולים עיקריים: תירס ופולי סויה. הידע המקומי הזה חשוב ויעזור לנו להחליט על פרמטרים מרכזיים למודל שלנו.
נתחיל בהשגת הגבול של המחוז שנבחר.
// Select the region
// Cerro Gordo County, Iowa
var counties = ee.FeatureCollection('TIGER/2018/Counties');
var selected = counties
.filter(ee.Filter.eq('GEOID', '19033'));
var geometry = selected.geometry();
Map.centerObject(geometry, 12);
Map.addLayer(geometry, {color: 'red'}, 'Selected Region', false);

איור: אזור נבחר
הכנת מערך הנתונים של הטמעת הלוויין
לאחר מכן, אנחנו טוענים את מערך הנתונים של הטמעת הלוויין, מסננים את התמונות לפי השנה שנבחרה ויוצרים פסיפס.
var embeddings = ee.ImageCollection('GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL');
var year = 2022;
var startDate = ee.Date.fromYMD(year, 1, 1);
var endDate = startDate.advance(1, 'year');
var filteredembeddings = embeddings
.filter(ee.Filter.date(startDate, endDate))
.filter(ee.Filter.bounds(geometry));
var embeddingsImage = filteredembeddings.mosaic();
יצירת כיסוי של שטחי גידול
כדי ליצור את המודל שלנו, אנחנו צריכים להחריג אזורים שלא משמשים לגידולים. יש הרבה מערכי נתונים גלובליים ואזוריים שאפשר להשתמש בהם כדי ליצור מסכת גידולים. ESA WorldCover או GFSAD Global Cropland Extent Product הן אפשרויות טובות למערכי נתונים גלובליים של שטחי גידולים. תוסף חדש יותר הוא המוצר ESA WorldCereal Active Cropland, שכולל מיפוי עונתי של שטחי גידול פעילים. מכיוון שהאזור שלנו נמצא בארה"ב, אנחנו יכולים להשתמש במערך נתונים אזורי מדויק יותר USDA NASS Cropland Data Layers (CDL) כדי לקבל מסיכת גידולים.
// Use Cropland Data Layers (CDL) to obtain cultivated cropland
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var croplandMask = cdl.select('cultivated').eq(2).rename('cropmask');
// Visualize the crop mask
var croplandMaskVis = {min: 0, max: 1, palette: ['white', 'green']};
Map.addLayer(croplandMask.clip(geometry), croplandMaskVis, 'Crop Mask');
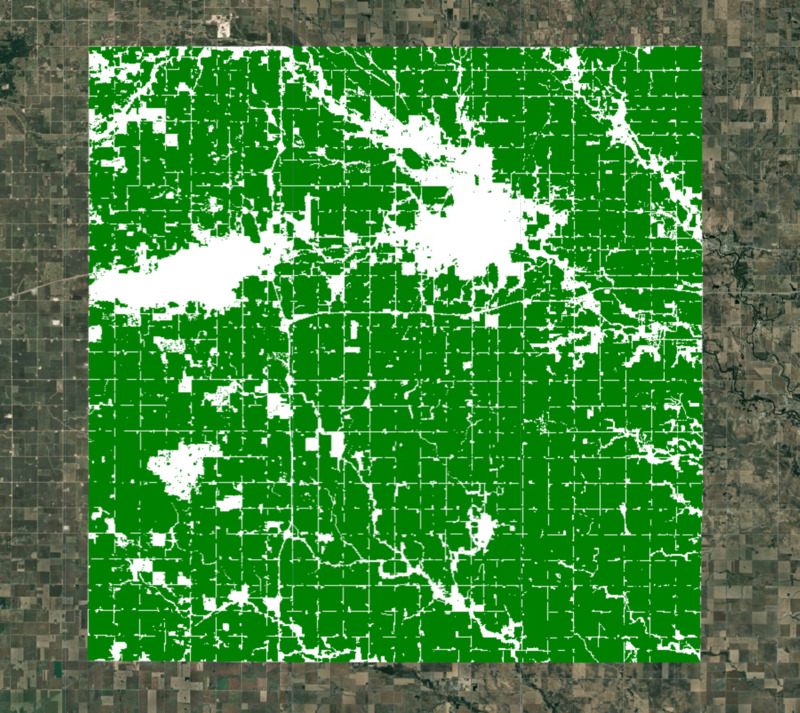
איור: אזור נבחר עם מסכת שטחי גידול
חילוץ דוגמאות לאימון
אנחנו מחילים את מסכת השדות החקלאיים על פסיפס ההטמעה. עכשיו נשארנו עם כל הפיקסלים שמייצגים שטחי חקלאות מעובדים במחוז.
// Mask all non-cropland pixels
var clusterImage = embeddingsImage.updateMask(croplandMask);
אנחנו צריכים לקחת את תמונת ההטמעה של הלוויין ולקבל דגימות אקראיות כדי לאמן מודל אשכול. מכיוון שהאזור שמעניין אותנו מכיל הרבה פיקסלים מוסתרים, דגימה אקראית פשוטה עלולה להניב דגימות עם ערכי null. כדי לוודא שנוכל לחלץ את מספר הדגימות הרצוי שאינו null, אנחנו משתמשים בדגימה שכבתית כדי לקבל את מספר הדגימות הרצוי באזורים לא מוסתרים.
// Stratified random sampling
var training = clusterImage.addBands(croplandMask).stratifiedSample({
numPoints: 1000,
classBand: 'cropmask',
region: geometry,
scale: 10,
tileScale: 16,
seed: 100,
dropNulls: true,
geometries: true
});
ייצוא דוגמה לנכס (אופציונלי)
שליפת דוגמאות היא פעולה שדורשת הרבה משאבי מחשוב, ולכן מומלץ לייצא את הדוגמאות שחולצו כנכסים ולהשתמש בנכסים המיוצאים בשלבים הבאים. הפעולה הזו תעזור לכם להתגבר על שגיאות שקשורות לזמן קצוב לתפוגה של חישוב או שגיאות שקשורות לחריגה מזיכרון המשתמש כשעובדים עם אזורים גדולים.
מתחילים את משימת הייצוא וממתינים עד שהיא מסתיימת לפני שממשיכים.
// Replace this with your asset folder
// The folder must exist before exporting
var exportFolder = 'projects/spatialthoughts/assets/satellite_embedding/';
var samplesExportFc = 'cluster_training_samples';
var samplesExportFcPath = exportFolder + samplesExportFc;
Export.table.toAsset({
collection: training,
description: 'Cluster_Training_Samples',
assetId: samplesExportFcPath
});
אחרי שמשימת הייצוא מסתיימת, אפשר לקרוא את הדגימות שחולצו בחזרה לקוד שלנו כקולקציית תכונות.
// Use the exported asset
var training = ee.FeatureCollection(samplesExportFcPath);
הצגת הדוגמאות
לא משנה אם הפעלתם את הדוגמה באופן אינטראקטיבי או ייצאתם אותה לאוסף תכונות, עכשיו יש לכם משתנה אימון עם נקודות הדוגמה. נניח שנרצה להדפיס את הדוגמה הראשונה כדי לבדוק אותה ולהוסיף את נקודות האימון שלנו ל-Map.
print('Extracted sample', training.first());
Map.addLayer(training, {color: 'blue'}, 'Extracted Samples', false);

איור: דוגמאות אקראיות שחולצו לצורך אשכולות
ביצוע אשכולות ללא פיקוח
עכשיו אפשר לאמן את האלגוריתם לקלאסטרינג ולקבץ את וקטורי ההטמעה של 64D למספר נבחר של קלאסטרים נפרדים. על סמך הידע המקומי שלנו, יש שני סוגים עיקריים של גידולים שמייצגים את רוב האזור, ועוד כמה גידולים שמכסים את החלק הנותר. אנחנו יכולים לבצע אשכול לא מפוקח על הטמעת הלוויין כדי לקבל אשכולות של פיקסלים עם מסלולים ודפוסים זמניים דומים. פיקסלים עם מאפיינים ספקטרליים ומרחביים דומים, ועם פנולוגיה דומה, יקובצו באותו אשכול.
הפרמטר ee.Clusterer.wekaCascadeKMeans() מאפשר לנו לציין מספר מינימלי ומקסימלי של אשכולות ולמצוא את המספר האופטימלי של אשכולות על סמך נתוני האימון. כאן הידע המקומי שלנו שימושי כדי להחליט מהו המספר המינימלי והמקסימלי של אשכולות. מכיוון שאנחנו מצפים לכמה סוגים שונים של אשכולות – תירס, פולי סויה ועוד כמה גידולים אחרים – אנחנו יכולים להשתמש ב-4 כמספר המינימלי של אשכולות וב-5 כמספר המקסימלי של אשכולות. יכול להיות שתצטרכו לערוך ניסויים עם המספרים האלה כדי לגלות מה הכי מתאים לאזור שלכם.
// Cluster the Satellite Embedding Image
var minClusters = 4;
var maxClusters = 5;
var clusterer = ee.Clusterer.wekaCascadeKMeans({
minClusters: minClusters, maxClusters: maxClusters}).train({
features: training,
inputProperties: clusterImage.bandNames()
});
var clustered = clusterImage.cluster(clusterer);
Map.addLayer(clustered.randomVisualizer().clip(geometry), {}, 'Clusters');
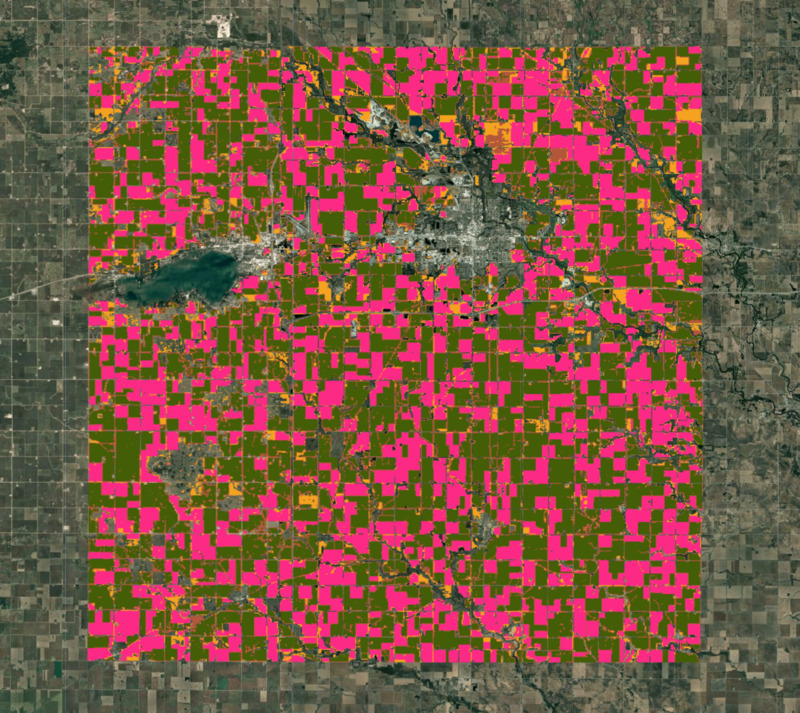
איור: אשכולות שהתקבלו מסיווג לא מפוקח
הקצאת תוויות לאשכולות
בבדיקה ויזואלית, המקבצים שהתקבלו בשלבים הקודמים תואמים באופן הדוק לגבולות החווה שמופיעים בתמונה ברזולוציה גבוהה. מהידע המקומי שלנו, אנחנו יודעים ששתי הקבוצות הגדולות ביותר הן תירס ופולי סויה. נחשב את השטח של כל אשכול בתמונה.
// Calculate Cluster Areas
// 1 Acre = 4046.86 Sq. Meters
var areaImage = ee.Image.pixelArea().divide(4046.86).addBands(clustered);
var areas = areaImage.reduceRegion({
reducer: ee.Reducer.sum().group({
groupField: 1,
groupName: 'cluster',
}),
geometry: geometry,
scale: 10,
maxPixels: 1e10
});
var clusterAreas = ee.List(areas.get('groups'));
// Process results to extract the areas and create a FeatureCollection
var clusterAreas = clusterAreas.map(function(item) {
var areaDict = ee.Dictionary(item);
var clusterNumber = areaDict.getNumber('cluster').format();
var area = areaDict.getNumber('sum');
return ee.Feature(null, {cluster: clusterNumber, area: area});
});
var clusterAreaFc = ee.FeatureCollection(clusterAreas);
print('Cluster Areas', clusterAreaFc);
אנחנו בוחרים את 2 האשכולות עם השטח הגדול ביותר.
var selectedFc = clusterAreaFc.sort('area', false).limit(2);
print('Top 2 Clusters by Area', selectedFc);
אבל עדיין לא ברור לנו איזה אשכול מייצג איזה גידול. אם יש לכם כמה דגימות שדה של תירס או פולי סויה, תוכלו להציג אותן בשכבת-על על האשכולות כדי להבין מה התוויות המתאימות שלהן. אם אין דגימות מהשדה, אפשר להשתמש בנתונים סטטיסטיים מצטברים של היבול. בחלקים רבים בעולם, נאספים נתונים סטטיסטיים מצטברים על יבולים ומתפרסמים באופן קבוע. בארה"ב, שירות הסטטיסטיקה הלאומי לחקלאות (NASS) מפרסם נתונים סטטיסטיים מפורטים על יבולים לכל מחוז ולכל יבול מרכזי. בשנת 2022, שטח התירס שנזרע במחוז סרו גורדו שבאיווה היה 653, 500 דונם,ושטח הסויה שנזרעה היה 447,000 דונם.
בעזרת המידע הזה, אנחנו יודעים שעבור 2 האזורים המובילים, סביר להניח שהאזור הגדול ביותר הוא תירס והאזור השני הוא פולי סויה. נשייך את התוויות האלה ונשווה בין האזורים המחושבים לבין הנתונים הסטטיסטיים שפורסמו.
var cornFeature = selectedFc.sort('area', false).first();
var soybeanFeature = selectedFc.sort('area').first();
var cornCluster = cornFeature.get('cluster');
var soybeanCluster = soybeanFeature.get('cluster');
print('Corn Area (Detected)', cornFeature.getNumber('area').round());
print('Corn Area (From Crop Statistics)', 163500);
print('Soybean Area (Detected)', soybeanFeature.getNumber('area').round());
print('Soybean Area (From Crop Statistics)', 110500);
יצירת מפת גידולים
עכשיו אנחנו יודעים את התוויות של כל אשכול, ואנחנו יכולים לחלץ את הפיקסלים של כל סוג חיתוך ולמזג אותם כדי ליצור את מפת החיתוך הסופית.
// Select the clusters to create the crop map
var corn = clustered.eq(ee.Number.parse(cornCluster));
var soybean = clustered.eq(ee.Number.parse(soybeanCluster));
var merged = corn.add(soybean.multiply(2));
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(merged.clip(geometry), cropVis, 'Crop Map (Detected)');
כדי לעזור לכם להבין את התוצאות, אנחנו יכולים גם להשתמש ברכיבי ממשק משתמש כדי ליצור מקרא ולהוסיף אותו למפה.
// Add a Legend
var legend = ui.Panel({
layout: ui.Panel.Layout.Flow('horizontal'),
style: {position: 'bottom-center', padding: '8px 15px'}});
var addItem = function(color, name) {
var colorBox = ui.Label({
style: {color: '#ffffff',
backgroundColor: color,
padding: '10px',
margin: '0 4px 4px 0',
}
});
var description = ui.Label({
value: name,
style: {
margin: '0px 10px 0px 2px',
}
});
return ui.Panel({
widgets: [colorBox, description],
layout: ui.Panel.Layout.Flow('horizontal')
});
};
var title = ui.Label({
value: 'Legend',
style: {
fontWeight: 'bold',
fontSize: '16px',
margin: '0px 10px 0px 4px'
}
});
legend.add(title);
legend.add(addItem('#ffd400', 'Corn'));
legend.add(addItem('#267300', 'Soybean'));
legend.add(addItem('#bdbdbd', 'Other Crops'));
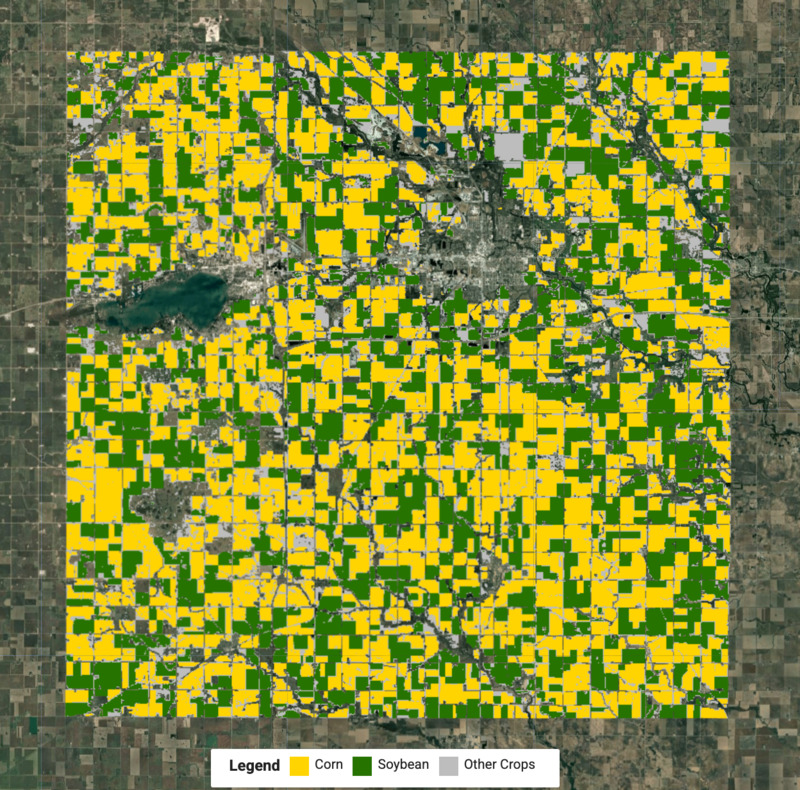
איור: מפה של גידולים חקלאיים שזוהו, עם גידולי תירס ופולי סויה
אימות התוצאות
הצלחנו להשיג מפה של סוגי הגידולים עם מערך הנתונים של הטמעת הלוויין בלי תוויות שדה, רק באמצעות נתונים סטטיסטיים מצטברים וידע מקומי על האזור. בואו נשווה את התוצאות שלנו למפת סוגי הגידולים הרשמית מ-USDA NASS Cropland Data Layers (CDL).
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var cropMap = cropLandcover.updateMask(croplandMask).rename('crops');
// Original data has unique values for each crop ranging from 0 to 254
var cropClasses = ee.List.sequence(0, 254);
// We remap all values as following
// Crop | Source Value | Target Value
// Corn | 1 | 1
// Soybean | 5 | 2
// All other| 0-255 | 0
var targetClasses = ee.List.repeat(0, 255).set(1, 1).set(5, 2);
var cropMapReclass = cropMap.remap(cropClasses, targetClasses).rename('crops');
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(cropMapReclass.clip(geometry), cropVis, 'Crop Landcover (CDL)');

איור: (מימין) חיתוך מפה מנתוני CDL (משמאל) חיתוך מפה מנתוני לוויין
למרות שיש הבדלים בין התוצאות שלנו לבין המפה הרשמית, אפשר לראות שהצלחנו לקבל תוצאות טובות למדי עם מינימום מאמץ. על ידי יישום שלבים של עיבוד אחרי העיבוד על התוצאות, אנחנו יכולים להסיר חלק מהרעשים ולמלא פערים בפלט.
אפשר לנסות את הסקריפט המלא של ההדרכה הזו בעורך הקוד של Earth Engine.