在先前的教學課程 (簡介) 中,我們瞭解了衛星嵌入項目如何擷取衛星觀測和氣候變數的年度軌跡。因此,您可直接使用資料集繪製作物地圖,不必建立作物物候模型。作物類型對應是一項艱鉅的任務,通常需要模擬作物物候,並為該地區種植的所有作物收集田間樣本。
在本教學課程中,我們將採用非監督式分類方法進行作物對應,以便在不依賴田間標籤的情況下執行這項複雜工作。這項方法會運用該地區的在地知識,以及許多地區都可取得的作物統計資料。
選取區域
在本教學課程中,我們將為愛荷華州塞羅戈多郡建立作物類型地圖。這個郡位於美國玉米帶,主要有兩種作物:玉米和大豆。這項在地知識非常重要,有助於我們決定模型的關鍵參數。
首先,請取得所選郡的邊界。
// Select the region
// Cerro Gordo County, Iowa
var counties = ee.FeatureCollection('TIGER/2018/Counties');
var selected = counties
.filter(ee.Filter.eq('GEOID', '19033'));
var geometry = selected.geometry();
Map.centerObject(geometry, 12);
Map.addLayer(geometry, {color: 'red'}, 'Selected Region', false);

圖:所選區域
準備衛星嵌入資料集
接著,我們載入「衛星嵌入」資料集,篩選所選年份的圖片,並建立影像拼接。
var embeddings = ee.ImageCollection('GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL');
var year = 2022;
var startDate = ee.Date.fromYMD(year, 1, 1);
var endDate = startDate.advance(1, 'year');
var filteredembeddings = embeddings
.filter(ee.Filter.date(startDate, endDate))
.filter(ee.Filter.bounds(geometry));
var embeddingsImage = filteredembeddings.mosaic();
建立農地遮罩
在模型中,我們需要排除非農地區域。您可以使用許多全球和區域資料集建立作物遮罩。ESA WorldCover 或 GFSAD Global Cropland Extent Product 是全球耕地資料集的理想選擇。最近新增的歐洲太空總署 WorldCereal Active Cropland 產品,可提供季節性耕地地圖。由於我們的區域位於美國,因此可以使用更準確的區域資料集 USDA NASS Cropland Data Layers (CDL) 取得作物遮罩。
// Use Cropland Data Layers (CDL) to obtain cultivated cropland
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var croplandMask = cdl.select('cultivated').eq(2).rename('cropmask');
// Visualize the crop mask
var croplandMaskVis = {min: 0, max: 1, palette: ['white', 'green']};
Map.addLayer(croplandMask.clip(geometry), croplandMaskVis, 'Crop Mask');
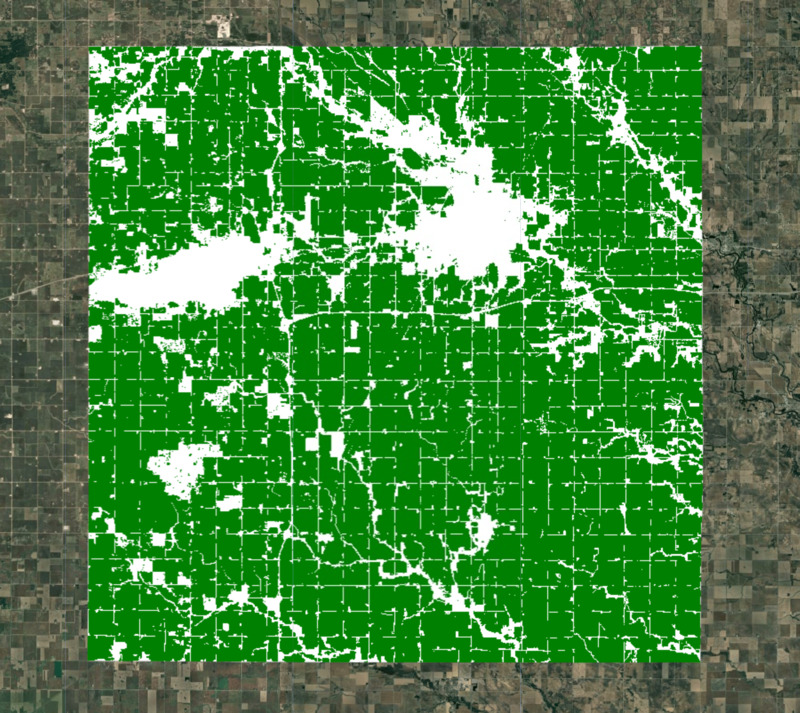
圖:選取的區域和農地遮罩
擷取訓練樣本
我們將農地遮罩套用至嵌入式鑲嵌。現在,我們只剩下代表該縣耕地的所有像素。
// Mask all non-cropland pixels
var clusterImage = embeddingsImage.updateMask(croplandMask);
我們需要取得衛星嵌入圖片,並取得隨機樣本來訓練叢集模型。由於感興趣的區域包含許多遮蓋的像素,簡單的隨機取樣可能會產生空值的樣本。為確保能擷取所需數量的非空值樣本,我們會使用分層抽樣,在未遮蓋的區域取得所需數量的樣本。
// Stratified random sampling
var training = clusterImage.addBands(croplandMask).stratifiedSample({
numPoints: 1000,
classBand: 'cropmask',
region: geometry,
scale: 10,
tileScale: 16,
seed: 100,
dropNulls: true,
geometries: true
});
將樣本匯出至素材資源 (選用)
擷取樣本需要大量運算資源,因此建議您將擷取的訓練樣本匯出為資產,並在後續步驟中使用匯出的資產。這樣一來,處理大型區域時,就能避免發生計算逾時或超出使用者記憶體限制錯誤。
啟動匯出工作,等待完成後再繼續操作。
// Replace this with your asset folder
// The folder must exist before exporting
var exportFolder = 'projects/spatialthoughts/assets/satellite_embedding/';
var samplesExportFc = 'cluster_training_samples';
var samplesExportFcPath = exportFolder + samplesExportFc;
Export.table.toAsset({
collection: training,
description: 'Cluster_Training_Samples',
assetId: samplesExportFcPath
});
匯出工作完成後,我們就能將擷取的樣本讀回程式碼,做為特徵集合。
// Use the exported asset
var training = ee.FeatureCollection(samplesExportFcPath);
以圖表呈現樣本
無論您是以互動方式執行樣本,還是匯出至特徵集合,現在都會有包含樣本點的訓練變數。讓我們列印第一個樣本進行檢查,並將訓練點新增至 Map。
print('Extracted sample', training.first());
Map.addLayer(training, {color: 'blue'}, 'Extracted Samples', false);

圖:用於叢集分析的隨機擷取樣本
執行非監督式分群
現在我們可以訓練叢集器,並將 64D 嵌入向量分組到所選數量的不同叢集。根據我們的在地知識,該區域主要有兩種作物,其餘作物則占少數。我們可以對衛星嵌入執行非監督式叢集分析,取得具有相似時間軌跡和模式的像素叢集。具有相似光譜和空間特徵,以及相似物候的像素會歸入同一叢集。
ee.Clusterer.wekaCascadeKMeans() 可讓我們指定叢集數量下限和上限,並根據訓練資料找出最佳叢集數量。這時,我們就能運用在地知識,決定叢集的最小和最大數量。由於我們預期會有幾種不同的叢集類型 (玉米、大豆和其他幾種作物),因此可將叢集數量下限設為 4,上限設為 5。您可能需要嘗試這些數字,找出最適合您所在地區的設定。
// Cluster the Satellite Embedding Image
var minClusters = 4;
var maxClusters = 5;
var clusterer = ee.Clusterer.wekaCascadeKMeans({
minClusters: minClusters, maxClusters: maxClusters}).train({
features: training,
inputProperties: clusterImage.bandNames()
});
var clustered = clusterImage.cluster(clusterer);
Map.addLayer(clustered.randomVisualizer().clip(geometry), {}, 'Clusters');
圖:從非監督式分類取得的叢集
為叢集指派標籤
經過目視檢查,先前步驟中取得的叢集與高解析度圖片中的農場邊界非常接近。根據當地知識,我們知道最大的兩個叢集是玉米和大豆。讓我們計算圖片中每個叢集的面積。
// Calculate Cluster Areas
// 1 Acre = 4046.86 Sq. Meters
var areaImage = ee.Image.pixelArea().divide(4046.86).addBands(clustered);
var areas = areaImage.reduceRegion({
reducer: ee.Reducer.sum().group({
groupField: 1,
groupName: 'cluster',
}),
geometry: geometry,
scale: 10,
maxPixels: 1e10
});
var clusterAreas = ee.List(areas.get('groups'));
// Process results to extract the areas and create a FeatureCollection
var clusterAreas = clusterAreas.map(function(item) {
var areaDict = ee.Dictionary(item);
var clusterNumber = areaDict.getNumber('cluster').format();
var area = areaDict.getNumber('sum');
return ee.Feature(null, {cluster: clusterNumber, area: area});
});
var clusterAreaFc = ee.FeatureCollection(clusterAreas);
print('Cluster Areas', clusterAreaFc);
我們會選取面積最大的 2 個叢集。
var selectedFc = clusterAreaFc.sort('area', false).limit(2);
print('Top 2 Clusters by Area', selectedFc);
但我們仍不知道哪個叢集代表哪種作物。如果您有幾種玉米或大豆的田間樣本,可以將這些樣本疊加在叢集上,找出各自的標籤。如果沒有田間樣本,我們可以使用匯總作物統計資料。世界各地許多地區都會定期收集並發布作物統計資料。在美國,國家農業統計局 (NASS) 提供各郡和各主要作物的詳細作物統計資料。2022 年,愛荷華州塞羅戈多郡的玉米種植面積為 161,500 英畝,大豆種植面積為 110,500 英畝。
根據這項資訊,我們現在知道在排名前 2 的叢集中,面積最大的叢集很可能是玉米,另一個則是黃豆。現在就來指派這些標籤,並比較計算出的區域與發布的統計資料。
var cornFeature = selectedFc.sort('area', false).first();
var soybeanFeature = selectedFc.sort('area').first();
var cornCluster = cornFeature.get('cluster');
var soybeanCluster = soybeanFeature.get('cluster');
print('Corn Area (Detected)', cornFeature.getNumber('area').round());
print('Corn Area (From Crop Statistics)', 163500);
print('Soybean Area (Detected)', soybeanFeature.getNumber('area').round());
print('Soybean Area (From Crop Statistics)', 110500);
建立作物地圖
我們現在知道每個叢集的標籤,可以擷取每種作物類型的像素,並合併這些像素來建立最終的作物地圖。
// Select the clusters to create the crop map
var corn = clustered.eq(ee.Number.parse(cornCluster));
var soybean = clustered.eq(ee.Number.parse(soybeanCluster));
var merged = corn.add(soybean.multiply(2));
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(merged.clip(geometry), cropVis, 'Crop Map (Detected)');
為協助解讀結果,我們也可以使用 UI 元素建立圖例並新增至地圖。
// Add a Legend
var legend = ui.Panel({
layout: ui.Panel.Layout.Flow('horizontal'),
style: {position: 'bottom-center', padding: '8px 15px'}});
var addItem = function(color, name) {
var colorBox = ui.Label({
style: {color: '#ffffff',
backgroundColor: color,
padding: '10px',
margin: '0 4px 4px 0',
}
});
var description = ui.Label({
value: name,
style: {
margin: '0px 10px 0px 2px',
}
});
return ui.Panel({
widgets: [colorBox, description],
layout: ui.Panel.Layout.Flow('horizontal')
});
};
var title = ui.Label({
value: 'Legend',
style: {
fontWeight: 'bold',
fontSize: '16px',
margin: '0px 10px 0px 4px'
}
});
legend.add(title);
legend.add(addItem('#ffd400', 'Corn'));
legend.add(addItem('#267300', 'Soybean'));
legend.add(addItem('#bdbdbd', 'Other Crops'));
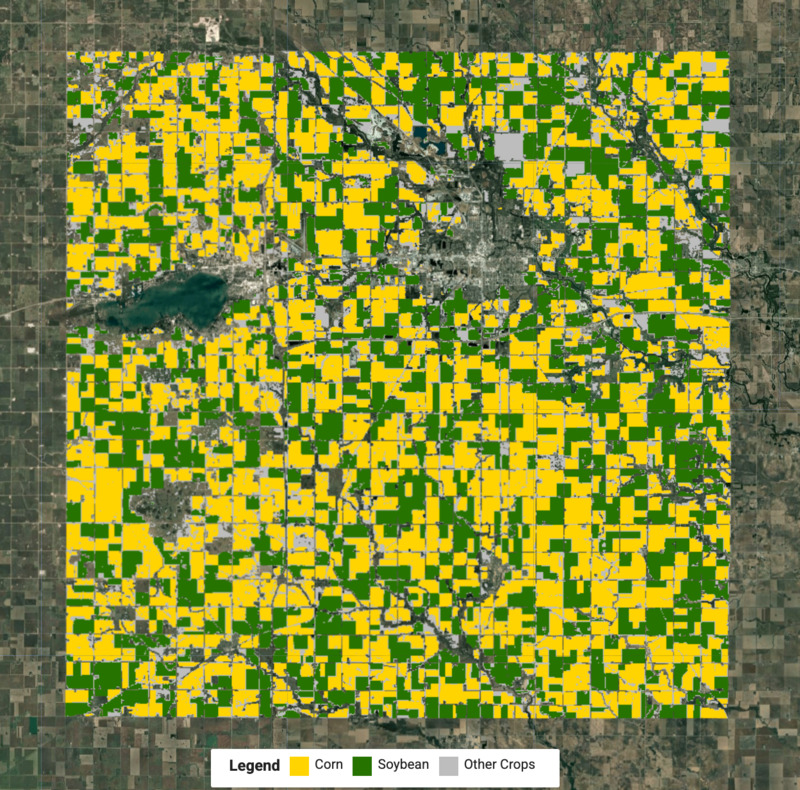
圖:偵測到的作物地圖,顯示玉米和大豆作物
驗證結果
我們只使用區域的匯總統計資料和在地知識,就從衛星嵌入資料集取得作物類型地圖,完全不需要任何田地標籤。讓我們將結果與美國農業部國家農業統計局 (NASS) 農地資料層 (CDL) 的官方作物類型地圖進行比較。
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var cropMap = cropLandcover.updateMask(croplandMask).rename('crops');
// Original data has unique values for each crop ranging from 0 to 254
var cropClasses = ee.List.sequence(0, 254);
// We remap all values as following
// Crop | Source Value | Target Value
// Corn | 1 | 1
// Soybean | 5 | 2
// All other| 0-255 | 0
var targetClasses = ee.List.repeat(0, 255).set(1, 1).set(5, 2);
var cropMapReclass = cropMap.remap(cropClasses, targetClasses).rename('crops');
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(cropMapReclass.clip(geometry), cropVis, 'Crop Landcover (CDL)');

圖:(左) 從衛星嵌入內容裁剪地圖;(右) 從 CDL 裁剪地圖
雖然我們的結果與官方地圖之間存在差異,但您會發現我們只需極少的心力,就能獲得相當不錯的結果。對結果套用後續處理步驟,即可移除部分雜訊並填補輸出內容中的空白處。