Debido a que el agrupamiento en clústeres no está supervisado, no hay "verdad" disponible para verificar los resultados. La ausencia de información complica la evaluación de la calidad. Además, los conjuntos de datos del mundo real no suelen incluirse en clústeres obvios de ejemplos, como el conjunto de datos que se muestra en la Figura 1.
Lamentablemente, los datos reales se parecen más a la Figura 2, lo que dificulta la evaluación visual de la calidad del agrupamiento en clústeres.
En el siguiente diagrama de flujo, se resume cómo verificar la calidad de tu agrupamiento en clústeres. Ampliaremos el resumen en las siguientes secciones.

Paso uno: Calidad del agrupamiento en clústeres
Verificar la calidad del agrupamiento en clústeres no es un proceso riguroso porque la agrupación carece de “verdad”. Estos son lineamientos que puedes aplicar de forma iterativa para mejorar la calidad de tu agrupamiento en clústeres.
Primero, realiza una verificación visual de que los clústeres se vean como se espera y que los ejemplos que consideres similares aparezcan en el mismo clúster. Luego, verifica estas métricas de uso común como se describe en las siguientes secciones:
- Cardinalidad del clúster
- Magnitud del clúster
- Rendimiento del sistema descendente
Cardinalidad de clúster
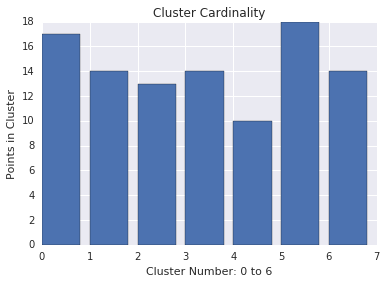
La cardinalidad de clúster es la cantidad de ejemplos por clúster. Traza la cardinalidad del clúster para todos los clústeres y, luego, investiga los clústeres que tienen valores atípicos importantes. Por ejemplo, en la Figura 2, investiga el clúster número 5.
Magnitud del clúster
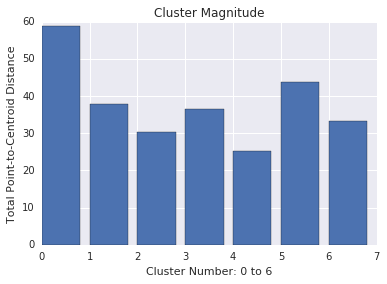
La magnitud del clúster es la suma de las distancias desde todos los ejemplos hasta el centroide del clúster. Al igual que la cardinalidad, verifica cómo varía la magnitud en los clústeres y, luego, investiga las anomalías. Por ejemplo, en la Figura 3, investiga el número de clúster 0.
Magnitud frente a cardinalidad
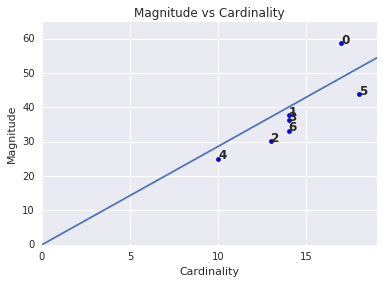
Ten en cuenta que una cardinalidad de clúster más alta tiende a generar una mayor magnitud de clúster, lo que tiene sentido de forma intuitiva. Los clústeres son anómalos cuando la cardinalidad no se correlaciona con la magnitud relativa a los otros clústeres. Encontrar clústeres anómalos mediante la representación de la magnitud en comparación con la cardinalidad Por ejemplo, en la Figura 4, el ajuste de una línea a las métricas del clúster muestra que el número de clúster 0 es anómalo.
Rendimiento del sistema descendente
Dado que el resultado del agrupamiento en clústeres suele usarse en sistemas de AA descendentes, verifica si el rendimiento del sistema descendente mejora cuando cambia el proceso de agrupamiento en clústeres. El impacto en el rendimiento posterior proporciona una prueba real de la calidad del agrupamiento en clústeres. La desventaja es que esta verificación es compleja.
Preguntas para investigar si se encuentran problemas
Si encuentras problemas, verifica la preparación de datos y la medida de similitud. Para ello, hazte las siguientes preguntas:
- ¿Tus datos se ajustan?
- ¿La medida de similitud es correcta?
- ¿Tu algoritmo realiza operaciones semánticamente significativas en los datos?
- ¿Las suposiciones de tu algoritmo coinciden con los datos?
Paso dos: Rendimiento de la medida de similitud
Su algoritmo de agrupamiento en clústeres es tan bueno como su medida de similitud. Asegúrate de que tu medida de similitud muestre resultados razonables. La verificación más simple es identificar pares de ejemplos que se conocen por ser más o menos similares que otros pares. Luego, calcula la medida de similitud para cada par de ejemplos. Asegúrate de que la medida de similitud para ejemplos similares sea mayor que la medida de similitud para ejemplos menos similares.
Los ejemplos que usas para verificar tu medida de similitud deben representar el conjunto de datos. Asegúrate de que la medida de similitud se aplique a todos los ejemplos. La verificación cuidadosa garantiza que la medida de similitud, ya sea manual o supervisada, sea coherente en todo el conjunto de datos. Si tu medida de similitud es incoherente para algunos ejemplos, esos ejemplos no se agruparán en clústeres con ejemplos similares.
Si encuentras ejemplos con similitudes imprecisas, es probable que tu medida de similitud no capture los datos de atributos que los distinguen. Experimenta con tu medida de similitud y determina si obtienes similitudes más precisas.
Paso tres: cantidad óptima de clústeres
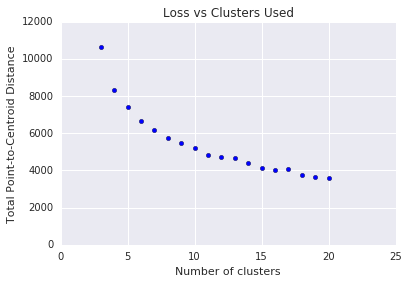
k-means requiere que decidas la cantidad de clústeres \(k\) de antemano. ¿Cómo se determina el valor óptimo de \(k\)? Intenta ejecutar el algoritmo para aumentar \(k\) y anota la suma de las magnitudes del clúster. A medida que \(k\)aumenta, los clústeres se vuelven más pequeños y la distancia total disminuye. Traza esta distancia con la cantidad de clústeres.
Como se muestra en la Figura 4, en un determinado \(k\), la reducción en la pérdida se vuelve marginal y aumenta \(k\). Desde el punto de vista matemático, ese es aproximadamente el \(k\)en el que la pendiente cruza por encima de -1 (\(\theta > 135^{\circ}\)). Este lineamiento no señala un valor exacto para un valor óptimo \(k\) , sino solo un valor aproximado. Para la representación que se muestra, el valor óptimo \(k\) es aproximadamente 11. Si prefieres clústeres más detallados, puedes elegir una \(k\) superior con este gráfico como guía.