由于聚类是不受监管的,因此没有“事实”可用于验证结果。缺少事实会使评估质量变得复杂。此外,实际数据集通常不属于图 1 所示的数据集的明显示例聚类。
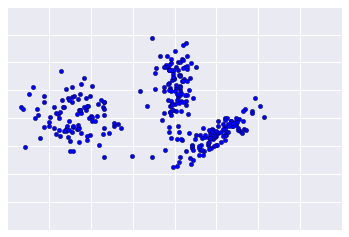
遗憾的是,实际数据更像图 2 所示,这使得很难直观地评估聚类质量。
以下流程图总结了如何检查聚类的质量。我们将在后面的几节内容中对此摘要进行详细说明。

第 1 步:聚类质量
检查聚类的质量并不是一个严格的流程,因为聚类缺乏“事实”。您可以反复遵循以下准则来提高聚类的质量。
首先,请进行直观检查,确认集群看起来符合预期,并且认为相似的示例是否出现在同一集群中。然后,按照以下部分中的说明检查这些常用指标:
- 集群基数
- 集群大小
- 下游系统的性能
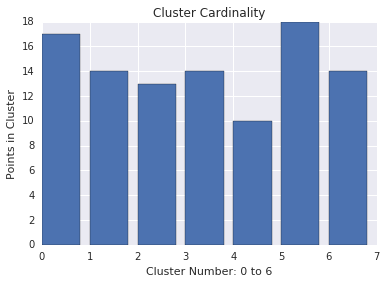
集群基数
聚类基数是每个聚类的样本数。绘制所有集群的集群基数,并调查主要离群值的集群。例如,在图 2 中调查集群编号 5。
集群规模
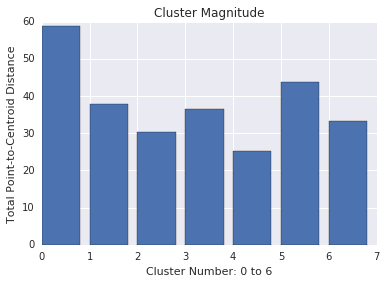
聚类数量是指从所有样本到聚类形心之间的距离的总和。与基数类似,请检查各集群的大小如何变化,并调查异常情况。例如,在图 3 中,调查集群编号 0。
大小与基数
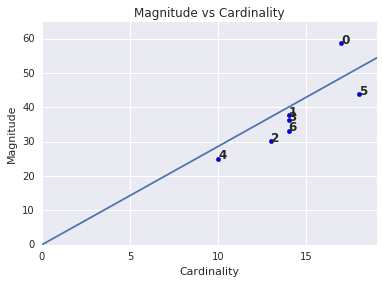
请注意,集群基数越高往往会产生较高的集群规模,这在视觉上是有意义的。当基数与数量相对于其他聚类数量无关时,聚类就会出现异常。通过根据基数绘制幅度来发现异常聚类。例如,在图 4 中,拟合一条线段显示聚类指标表明集群编号 0 是异常值。
下游系统的性能
由于聚类输出通常用于下游机器学习系统,因此请检查聚类进程在聚类进程更改时的性能是否有所提高。对下游性能的影响可对集群质量进行实际测试。缺点是执行此项检查比较复杂。
发现问题后应调查的问题
如果您发现了问题,请检查数据准备和相似度衡量,并思考以下问题:
- 您的数据是否已调整?
- 相似度衡量是否正确?
- 您的算法是否对数据执行了语义上有意义的操作?
- 您的算法假设是否与数据匹配?
第 2 步:相似度衡量的效果
您的聚类算法的效果取决于相似度衡量。确保您的相似度测量返回合理的结果。最简单的检查是,确定已知与其他对相似或不同的样本对。然后,计算每对样本的相似度衡量。确保相似度较高的相似度度量值高于相似度较低的相似度度量值。
用于检测相似度衡量的示例应能代表数据集。确保所有样本的相似度衡量结果均有效。仔细验证可确保您的相似度衡量(手动或监督式)在整个数据集中保持一致。如果某些示例的相似度衡量结果不一致,则这些示例将不会与类似示例汇总。
如果您发现具有相似性的样本不正确,则相似度衡量可能无法捕获区分这些样本的特征数据。对您的相似度指标进行实验,确定您是否能够获得更准确的相似度。
第 3 步:最佳聚类数量
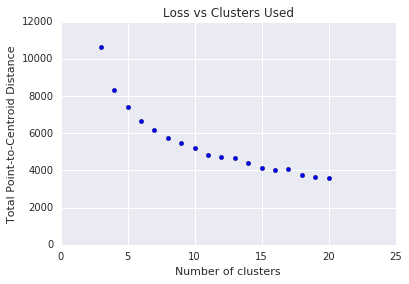
k-average 需要您预先确定聚类数量。 \(k\) 如何确定 \(k\)的最佳值?请尝试运行算法来增加 \(k\) ,并记下聚类数量的总和。随着 \(k\)的增加,集群会变小,总距离会变小。根据集群数量绘制此距离。
如图 4 所示,在特定 \(k\)时,损失减少随 \(k\)增加而增加。从数学上看,这大概是斜率超过 -1 (\(\theta > 135^{\circ}\)) 的 \(k\)。该准则并不能精确指出优化的最佳值 \(k\) ,而只能确定近似值。对于所示的图表, \(k\) 最佳值约为 11。如果您更喜欢更精细的集群,可以使用此图表作为指导,选择更高的 \(k\) 。