由於叢集不受監督,因此沒有「真實資訊」可用於驗證結果。沒有真實資料可以評估品質。此外,實際資料集通常不會有明顯的範例叢集,如圖 1 所示資料集。
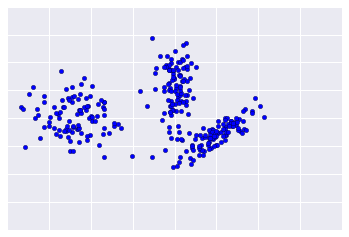
很遺憾,實際資料看起來與圖 2 類似,因此難以視覺化評估叢集品質。
下列流程圖說明如何檢查叢集品質。我們會在以下各節中展開摘要。

步驟 1:分群品質
檢查叢集品質並不是一項嚴謹的程序,因為分群過程「真相」。以下是您可以疊加的準則,以改善叢集品質。
首先,執行視覺化檢查,確認叢集看起來符合預期,且您認為類似的範例會在同一個叢集中顯示。接著,請參閱下列各節所述的常用指標:
- 叢集基數
- 叢集規模
- 下游系統的效能
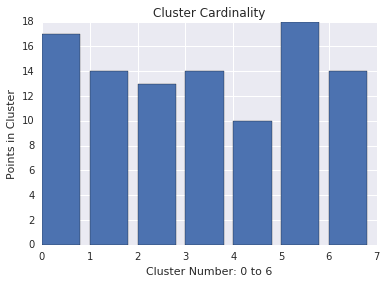
叢集基數
叢集基數是每個叢集的範例數量。找出所有叢集的叢集基數,並調查主要離群值的叢集。例如,在圖 2 中,調查叢集 5。
叢集規模
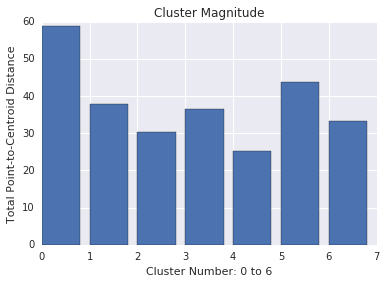
叢集規模是從所有範例到叢集的質心的距離總和。與基數類似,請查看叢集大小之間的差異,並調查異常狀況。例如,在圖 3 中,調查叢集編號 0。
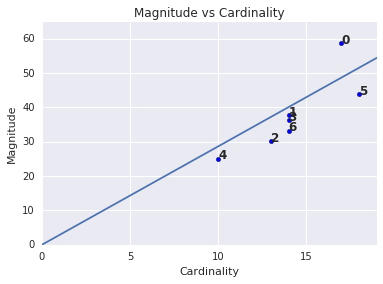
Magnitude 與 Cardinnom 比較
請注意,叢集基數較高通常會導致叢集規模較高,這相當直觀。如果基數與其他叢集的大小不同,叢集出現異常狀況。透過基數繪製規模,找出異常的叢集。例如,在圖 4 中,對齊叢集指標後,您發現叢集編號 0 是異常的。
下游系統的效能
由於下游機器學習系統通常會採用分群輸出,因此在分群程序變更時,檢查下游系統的效能是否有所改善。後續串流效能的影響,會針對叢集品質提供實際測試。缺點是執行這項檢查的複雜度。
在發現問題時調查的問題
若發現問題,請檢查資料準備和相似度評估方式,並問以下問題:
- 資料是否經過調整?
- 相似度評估結果是否正確?
- 您的演算法是否針對資料執行語意式操作?
- 演算法的假設與資料相符嗎?
步驟 2:相似度指標的成效
您的叢集演算法演算法的相似程度必須與相似度測量結果一樣高。確保您的相似度結果會傳回有意義的結果。最簡單的檢查方法就是識別已知比其他組合更相似或更少的樣本組合。然後計算每組樣本的相似度測量結果。確保類似範例的相似度測量值高於類似樣本的相似度測量結果。
用於檢查相似度測量的例子應與資料集代表。針對所有範例,確保相似度指標是保留的。請務必謹慎驗證,無論是以手動或受監督的方式,所有資料集中的相似度評估結果都一致。如果部分範例的相似度測量結果不一致,這些範例就無法分化為類似範例。
如果發現相似度有誤的範例,相似度評估就可能無法擷取區分這些範例的特徵資料。嘗試相似度評估,判斷能否更準確。
步驟 3:最佳叢集數量
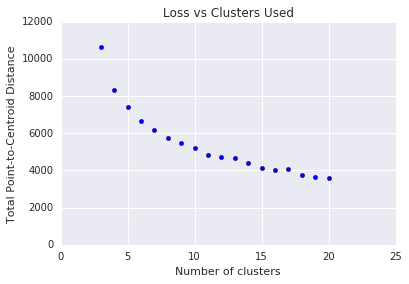
k-means 需要您預先決定 \(k\) 叢集數量。您要如何判斷 \(k\)的最佳值?請嘗試執行演算法以增加 \(k\) 數量,並留意叢集規模的總和。隨著 \(k\)增加,叢集會變小,而總距離會變小。請比對這個距離與叢集數量。
如圖 4 所示,特定 \(k\)的損失會因為 \(k\)增加而減少。從數學上來說,大概是 \(k\)坡度在 -1 以上的位置 (\(\theta > 135^{\circ}\))。這個準則並未準確判斷最佳 \(k\) 的值,但只有約略值。針對所顯示的圖,最佳 \(k\) 約為 11。如果您偏好更精細的叢集,可以使用這張圖表選擇較高的 \(k\) 。