مقدمة
يوضّح هذا المستند كيفية إنشاء حل لاختيار المواقع الجغرافية من خلال الجمع بين مجموعة بيانات إحصاءات الأماكن والبيانات الجغرافية المكانية العامة في BigQuery وPlace Details API.
ويستند إلى عرض توضيحي تم تقديمه في مؤتمر Google Cloud Next 2025، وهو متاح للمشاهدة على YouTube. يتوفّر أيضًا مثال على دفتر ملاحظات Colab، يحتوي على الرمز البرمجي للعملية الموضّحة في المستند، بتنسيق جاهز للتنفيذ.
التحدّي التجاري
لنفترض أنّك تملك سلسلة ناجحة من المقاهي وتريد التوسّع إلى ولاية جديدة، مثل نيفادا، حيث لا تتوفّر أي فروع لك. يُعدّ افتتاح موقع جغرافي جديد استثمارًا كبيرًا، لذا من الضروري اتّخاذ قرار مستند إلى البيانات لضمان النجاح. كيف يمكنك البدء في استخدامها؟
يرشدك هذا الدليل إلى كيفية إجراء تحليل متعدّد الطبقات لتحديد الموقع الجغرافي الأمثل لمقهى جديد. سنبدأ بعرض على مستوى الولاية، ثم نضيّق نطاق البحث تدريجيًا ليشمل مقاطعة ومنطقة تجارية محدّدتَين، وأخيرًا، سنُجري تحليلًا على مستوى المنطقة لتحديد نقاط القوة والضعف في كل منطقة وتحديد الفجوات في السوق من خلال تحديد المنافسين.
سير عمل الحل
تتّبع هذه العملية مسارًا منطقيًا، بدءًا من نطاق واسع ثمّ تضييقه تدريجيًا لتحسين مساحة البحث وزيادة الثقة في اختيار الموقع الإلكتروني النهائي.
المتطلّبات الأساسية وإعداد البيئة
قبل الخوض في التحليل، تحتاج إلى بيئة تتضمّن بعض الإمكانات الأساسية. على الرغم من أنّ هذا الدليل سيتضمّن شرحًا تفصيليًا لعملية التنفيذ باستخدام SQL وPython، يمكن تطبيق المبادئ العامة على حِزم التكنولوجيا الأخرى.
كشرط أساسي، تأكَّد من أنّ بيئتك يمكنها إجراء ما يلي:
- تنفيذ طلبات البحث في BigQuery
- الوصول إلى Places Insights، راجِع إعداد Places Insights للحصول على مزيد من المعلومات
- الاشتراك في مجموعات البيانات العامة من
bigquery-public-dataوإجمالي عدد السكان في مقاطعات مكتب الإحصاء الأمريكي
يجب أيضًا أن تكون قادرًا على تصوّر البيانات الجغرافية المكانية على خريطة، وهو أمر بالغ الأهمية لتفسير نتائج كل خطوة تحليلية. وهناك العديد من الطرق لتحقيق ذلك. يمكنك استخدام أدوات ذكاء الأعمال، مثل Looker Studio، التي تتصل مباشرةً بـ BigQuery، أو يمكنك استخدام لغات علوم البيانات، مثل Python.
تحليل على مستوى الولاية: العثور على أفضل مقاطعة
تتمثل خطوتنا الأولى في إجراء تحليل شامل لتحديد المقاطعة الأكثر واعدًا في ولاية نيفادا. نعرّف المدن الواعدة بأنّها المدن التي تضم عددًا كبيرًا من السكان وكثافة عالية من المطاعم الحالية، ما يشير إلى ثقافة قوية في مجال الأطعمة والمشروبات.
يحقّق طلب البحث في BigQuery ذلك من خلال الاستفادة من مكوّنات العناوين المضمّنة المتوفّرة ضمن مجموعة بيانات Places Insights. يحسب طلب البحث عدد المطاعم من خلال فلترة البيانات أولاً لتضمين الأماكن الواقعة في ولاية نيفادا فقط، وذلك باستخدام الحقل administrative_area_level_1_name. بعد ذلك، يتم تحسين هذه المجموعة لتشمل فقط الأماكن التي تحتوي مصفوفة الأنواع فيها على restaurant. وأخيرًا، يتم تجميع هذه النتائج حسب اسم المقاطعة (administrative_area_level_2_name) لإنشاء عدد لكل مقاطعة. يستفيد هذا الأسلوب من بنية العناوين المضمّنة والمفهرسة مسبقًا في مجموعة البيانات.
تعرض المقتطفة التالية كيفية ربط الأشكال الهندسية الخاصة بالمقاطعات بـ "إحصاءات الأماكن" وفلترة
نوع مكان محدّد، restaurant:
SELECT WITH AGGREGATION_THRESHOLD
administrative_area_level_2_name,
COUNT(*) AS restaurant_count
FROM
`places_insights___us.places`
WHERE
-- Filter for the state of Nevada
administrative_area_level_1_name = 'Nevada'
-- Filter for places that are restaurants
AND 'restaurant' IN UNNEST(types)
-- Filter for operational places only
AND business_status = 'OPERATIONAL'
-- Exclude rows where the county name is null
AND administrative_area_level_2_name IS NOT NULL
GROUP BY
administrative_area_level_2_name
ORDER BY
restaurant_count DESC
لا يكفي توفير عدد أولي للمطاعم، بل يجب موازنة ذلك مع بيانات السكان للحصول على فكرة حقيقية عن مدى تشبّع السوق والفرص المتاحة. سنستخدم بيانات السكان من إجمالي عدد السكان في المقاطعات وفقًا لمكتب الإحصاء الأمريكي.
للمقارنة بين هذين المقياسَين المختلفَين تمامًا (عدد الأماكن مقابل عدد كبير من السكان)، نستخدم عملية التسوية بين الحدّين الأدنى والأقصى. تؤدي هذه التقنية إلى توسيع نطاق المقياسَين إلى نطاق مشترك (من 0 إلى 1). بعد ذلك، نجمعها في
normalized_score واحدة، ونمنح كل مقياس وزنًا بنسبة% 50 لإجراء مقارنة متوازنة.
يعرض هذا المقتطف المنطق الأساسي لاحتساب النتيجة. وهي تجمع بين عدد السكان والمطاعم بعد تسويتهما:
(
-- Normalize restaurant count (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(restaurant_count - min_restaurants, max_restaurants - min_restaurants) * 0.5
+
-- Normalize population (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(population_2023 - min_pop, max_pop - min_pop) * 0.5
) AS normalized_score
بعد تنفيذ الاستعلام الكامل، يتم عرض قائمة بالمقاطعات وعدد المطاعم وعدد السكان والنتيجة المعدَّلة. يؤدي الترتيب حسب normalized_score
DESC إلى ظهور مقاطعة "كلارك" كخيار أفضل بوضوح يستحق المزيد من البحث باعتباره الخيار الأفضل.
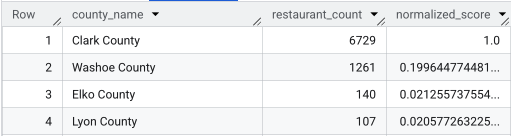
تعرض لقطة الشاشة هذه أهم 4 مقاطعات حسب النتيجة المعدَّلة. تم حذف عدد السكان الأولي عمدًا من هذا المثال.
التحليل على مستوى المقاطعة: العثور على المناطق التجارية الأكثر ازدحامًا
بعد تحديد مقاطعة كلارك، الخطوة التالية هي تكبير الخريطة للعثور على الرموز البريدية التي تشهد أعلى مستوى من النشاط التجاري. استنادًا إلى بيانات من مقاهينا الحالية، نعلم أنّ الأداء يكون أفضل عندما يكون الموقع الجغرافي بالقرب من عدد كبير من العلامات التجارية الكبرى، لذا سنستخدم ذلك كبديل لعدد الزوّار الكبير.
يستخدم طلب البحث هذا الجدول brands ضمن "إحصاءات الأماكن"، والذي يتضمّن معلومات حول علامات تجارية معيّنة. يمكن الاستعلام عن هذا الجدول للاطّلاع على قائمة
العلامات التجارية المتوافقة. نحدّد أولاً قائمة بالعلامات التجارية المستهدَفة، ثم ندمجها مع مجموعة بيانات Places Insights الرئيسية لاحتساب عدد المتاجر المحدّدة التي تقع ضمن كل رمز بريدي في مقاطعة كلارك.
الطريقة الأكثر فعالية لتحقيق ذلك هي اتّباع الخطوات التالية:
- أولاً، سننفّذ عملية تجميع سريعة غير مكانية جغرافية لاحتساب عدد العلامات التجارية داخل كل رمز بريدي.
- ثانيًا، سنربط هذه النتائج بمجموعة بيانات عامة للحصول على حدود الخريطة اللازمة لإنشاء التمثيل المرئي.
احتساب العلامات التجارية باستخدام الحقل postal_code_names
ينفّذ طلب البحث الأول منطق الاحتساب الأساسي. تتم فلترة الأماكن في مقاطعة كلارك، ثم يتم إلغاء تداخل مصفوفة postal_code_names لتجميع عدد العلامات التجارية حسب الرمز البريدي.
WITH brand_names AS (
-- First, select the chains we are interested in by name
SELECT
id,
name
FROM
`places_insights___us.brands`
WHERE
name IN ('7-Eleven', 'CVS', 'Walgreens', 'Subway Restaurants', "McDonald's")
)
SELECT WITH AGGREGATION_THRESHOLD
postal_code,
COUNT(*) AS total_brand_count
FROM
`places_insights___us.places` AS places_table,
-- Unnest the built-in postal code and brand ID arrays
UNNEST(places_table.postal_code_names) AS postal_code,
UNNEST(places_table.brand_ids) AS brand_id
JOIN
brand_names
ON brand_names.id = brand_id
WHERE
-- Filter directly on the administrative area fields in the places table
places_table.administrative_area_level_2_name = 'Clark County'
AND places_table.administrative_area_level_1_name = 'Nevada'
GROUP BY
postal_code
ORDER BY
total_brand_count DESC
الناتج هو جدول يتضمّن الرموز البريدية وأعداد العلامات التجارية المقابلة لها.

إرفاق أشكال هندسية للرموز البريدية من أجل إنشاء الخرائط
بعد أن أصبح لدينا عدد مرات الظهور، يمكننا الحصول على أشكال المضلّعات اللازمة للعرض المرئي. يأخذ الاستعلام الثاني الاستعلام الأول، ويضعه في تعبير جدول مشترك (CTE) باسم brand_counts_by_zip، ثم يربط نتائجه بالجدول geo_us_boundaries.zip_codes table العام. يؤدي ذلك إلى ربط الشكل الهندسي بشكل فعّال بالأعداد التي تم احتسابها مسبقًا.
WITH brand_counts_by_zip AS (
-- This will be the entire query from the previous step, without the final ORDER BY (excluded for brevity).
. . .
)
-- Now, join the aggregated results to the boundaries table
SELECT
counts.postal_code,
counts.total_brand_count,
-- Simplify the geometry for faster rendering in maps
ST_SIMPLIFY(zip_boundaries.zip_code_geom, 100) AS geography
FROM
brand_counts_by_zip AS counts
JOIN
`bigquery-public-data.geo_us_boundaries.zip_codes` AS zip_boundaries
ON counts.postal_code = zip_boundaries.zip_code
ORDER BY
counts.total_brand_count DESC
يكون الناتج جدولاً يتضمّن الرموز البريدية وعدد العلامات التجارية المرتبطة بها والشكل الهندسي للرمز البريدي.

يمكننا تصوّر هذه البيانات على شكل خريطة تمثيل لوني. تشير المناطق الحمراء الداكنة إلى تركيز أعلى للعلامات التجارية المستهدَفة، ما يوجّهنا نحو المناطق الأكثر كثافة من الناحية التجارية في لاس فيغاس.
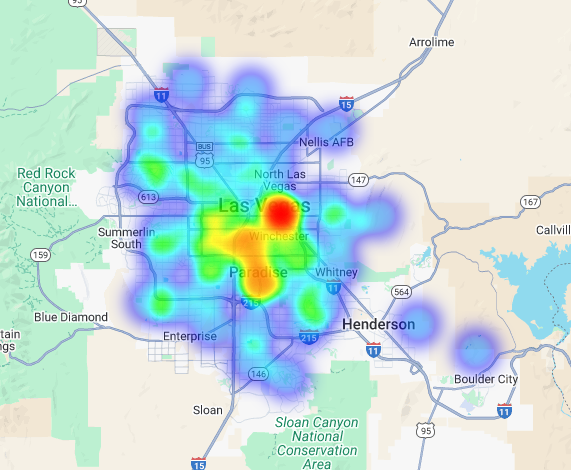
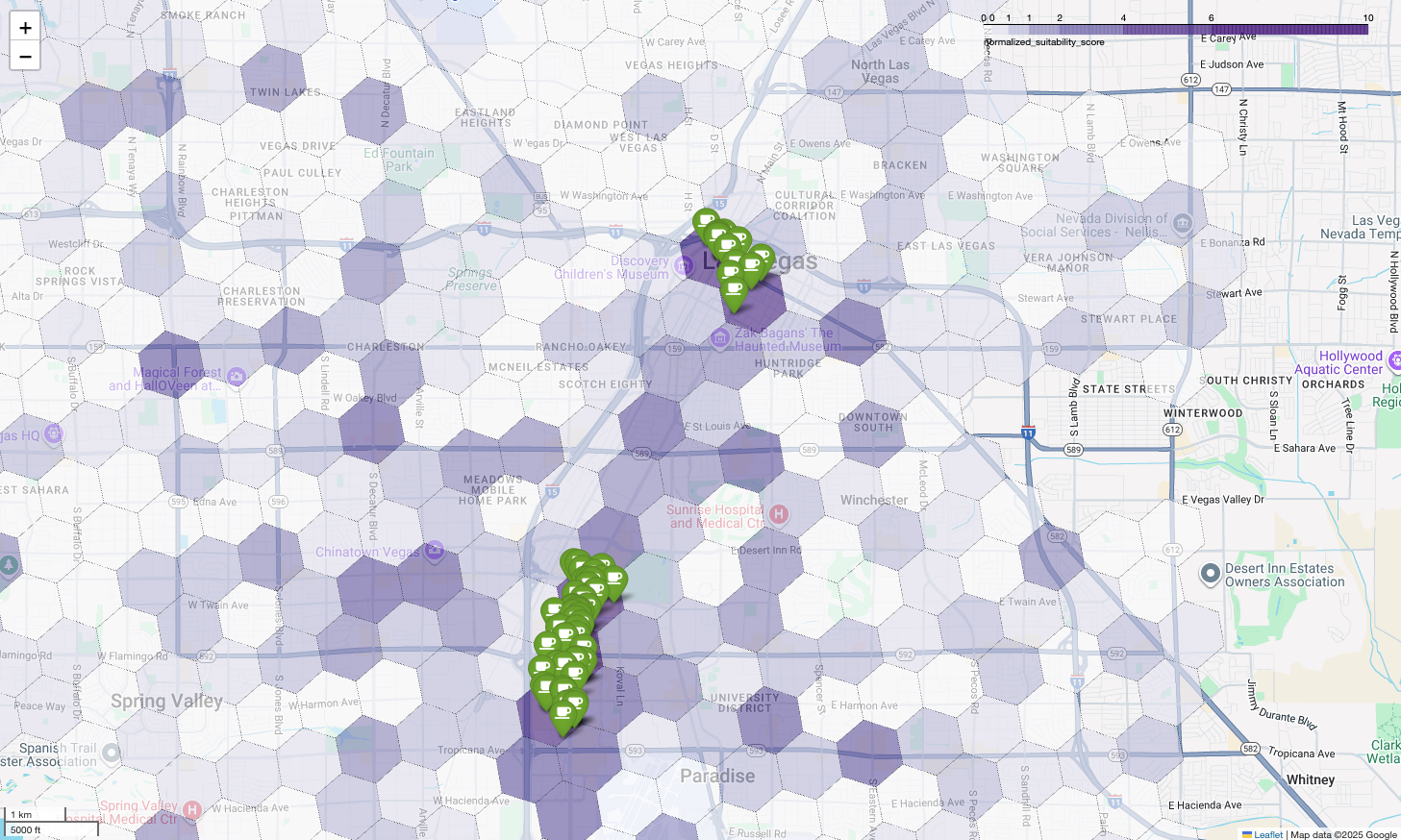
التحليل على مستوى المنطقة: تسجيل نقاط لمناطق الشبكة الفردية
بعد تحديد المنطقة العامة لمدينة لاس فيغاس، حان الوقت لإجراء تحليل مفصّل. هنا نُضيف معرفتنا المحدّدة بالنشاط التجاري. نعلم أنّ المقهى الناجح يقع بالقرب من أنشطة تجارية أخرى تشهد ازدحامًا خلال ساعات الذروة، مثل الفترة بين الصباح المتأخر ووقت الغداء.
يصبح الاستعلام التالي أكثر تحديدًا. تبدأ العملية بإنشاء شبكة سداسية دقيقة التفاصيل فوق منطقة لاس فيغاس الحضرية باستخدام فهرس H3 الجغرافي المكاني العادي (بدقة 8) لتحليل المنطقة على مستوى دقيق. يحدّد طلب البحث أولاً جميع الأنشطة التجارية التكميلية المفتوحة خلال فترة الذروة (من الاثنين إلى الجمعة، من الساعة 10 صباحًا إلى الساعة 2 ظهرًا).
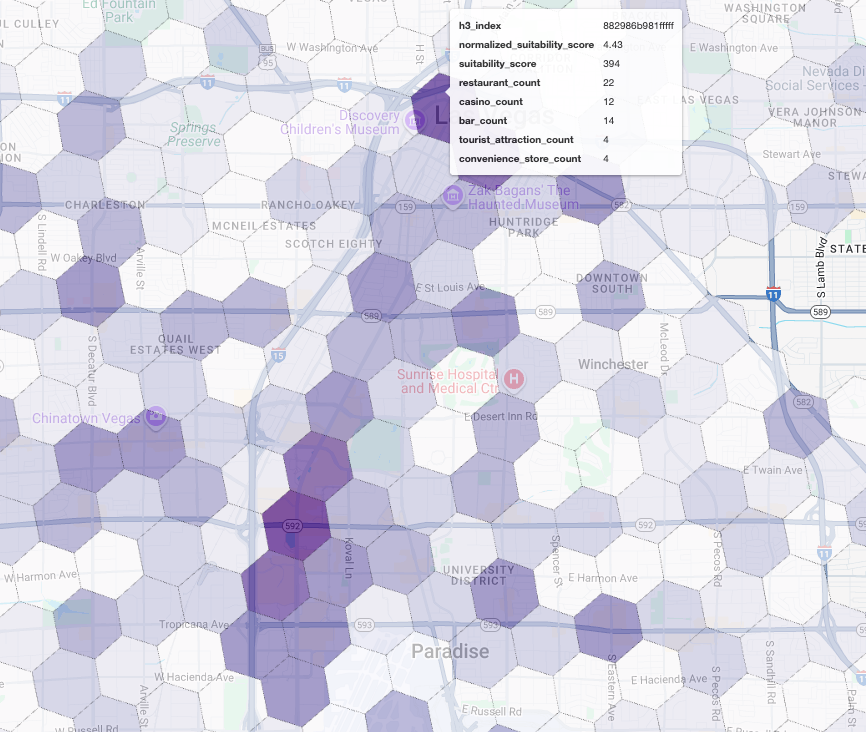
بعد ذلك، نطبّق نتيجة مرجّحة على كل نوع من الأماكن. ويكون المطعم القريب أكثر أهمية بالنسبة إلينا من المتجر الصغير، لذا يحصل على عامل مضاعف أعلى. يمنحنا ذلك suitability_score مخصّصًا لكل منطقة صغيرة.
يسلّط هذا المقتطف الضوء على منطق التسجيل المرجّح الذي يشير إلى علامة (is_open_monday_window) تم احتسابها مسبقًا للتحقّق من ساعات العمل:
. . .
(
COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 +
COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 +
COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 +
COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 +
COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7
) AS suitability_score
. . .
توسيع الطلب الكامل
-- This query calculates a custom 'suitability score' for different areas in the Las Vegas -- metropolitan area to identify prime commercial zones. It uses a weighted model based -- on the density of specific business types that are open during a target time window. -- Step 1: Pre-filter the dataset to only include relevant places. -- This CTE finds all places in our target localities (Las Vegas, Spring Valley, etc.) and -- adds a boolean flag 'is_open_monday_window' for those open during the target time. WITH PlacesInTargetAreaWithOpenFlag AS ( SELECT point, types, EXISTS( SELECT 1 FROM UNNEST(regular_opening_hours.monday) AS monday_hours WHERE monday_hours.start_time <= TIME '10:00:00' AND monday_hours.end_time >= TIME '14:00:00' ) AS is_open_monday_window FROM `places_insights___us.places` WHERE EXISTS ( SELECT 1 FROM UNNEST(locality_names) AS locality WHERE locality IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester') ) AND administrative_area_level_1_name = 'Nevada' ), -- Step 2: Aggregate the filtered places into H3 cells and calculate the suitability score. -- Each place's location is converted to an H3 index (at resolution 8). The query then -- calculates a weighted 'suitability_score' and individual counts for each business type -- within that cell. TileScores AS ( SELECT WITH AGGREGATION_THRESHOLD -- Convert each place's geographic point into an H3 cell index. `carto-os.carto.H3_FROMGEOGPOINT`(point, 8) AS h3_index, -- Calculate the weighted score based on the count of places of each type -- that are open during the target window. ( COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 + COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 + COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 + COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 + COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7 ) AS suitability_score, -- Also return the individual counts for each category for detailed analysis. COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) AS restaurant_count, COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) AS convenience_store_count, COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) AS bar_count, COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) AS tourist_attraction_count, COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) AS casino_count FROM -- CHANGED: This now references the CTE with the expanded area. PlacesInTargetAreaWithOpenFlag -- Group by the H3 index to ensure all calculations are per-cell. GROUP BY h3_index ), -- Step 3: Find the maximum suitability score across all cells. -- This value is used in the next step to normalize the scores to a consistent scale (e.g., 0-10). MaxScore AS ( SELECT MAX(suitability_score) AS max_score FROM TileScores ) -- Step 4: Assemble the final results. -- This joins the scored tiles with the max score, calculates the normalized score, -- generates the H3 cell's polygon geometry for mapping, and orders the results. SELECT ts.h3_index, -- Generate the hexagonal polygon for the H3 cell for visualization. `carto-os.carto.H3_BOUNDARY`(ts.h3_index) AS h3_geography, ts.restaurant_count, ts.convenience_store_count, ts.bar_count, ts.tourist_attraction_count, ts.casino_count, ts.suitability_score, -- Normalize the score to a 0-10 scale for easier interpretation. ROUND( CASE WHEN ms.max_score = 0 THEN 0 ELSE (ts.suitability_score / ms.max_score) * 10 END, 2 ) AS normalized_suitability_score FROM -- A cross join is efficient here as MaxScore contains only one row. TileScores ts, MaxScore ms -- Display the highest-scoring locations first. ORDER BY normalized_suitability_score DESC;
ويؤدي عرض هذه النتائج على خريطة إلى الكشف عن المواقع الجغرافية الفائزة بوضوح. تشير المربّعات الأرجوانية الداكنة، والتي تقع بشكل أساسي بالقرب من شارع "لاس فيغاس ستريب" ووسط المدينة، إلى المناطق التي تضمّ أكبر عدد من العملاء المحتملين لمقهانا الجديد.
تحليل المنافسين: تحديد المقاهي الحالية
لقد حدّد نموذج الملاءمة المناطق الواعدة بنجاح، ولكنّ الحصول على درجة عالية وحده لا يضمن النجاح. يجب الآن دمج هذه البيانات مع بيانات المنافسين. الموقع المثالي هو منطقة ذات إمكانات عالية وكثافة منخفضة من المقاهي الحالية، لأنّنا نبحث عن فجوة واضحة في السوق.
لتحقيق ذلك، نستخدم الدالة
PLACES_COUNT_PER_H3. تم تصميم هذه الدالة لعرض أعداد الأماكن بكفاءة ضمن منطقة جغرافية محدّدة، وذلك حسب خلية H3.
أولاً، نحدّد بشكل ديناميكي الموقع الجغرافي لمنطقة لاس فيغاس الحضرية بأكملها.
بدلاً من الاعتماد على منطقة محلية واحدة، نطلب من مجموعة بيانات Overture Maps العامة الحصول على حدود لاس فيغاس والمناطق المحلية الرئيسية المحيطة بها، ثم ندمجها في مضلّع واحد باستخدام ST_UNION_AGG. بعد ذلك، نمرّر هذه المنطقة إلى الدالة، ونطلب منها احتساب جميع المقاهي التي تعمل.
يحدّد هذا الاستعلام منطقة العاصمة ويستدعي الدالة للحصول على عدد المقاهي في خلايا H3:
-- Define a variable to hold the combined geography for the Las Vegas metro area.
DECLARE las_vegas_metro_area GEOGRAPHY;
-- Set the variable by fetching the shapes for the five localities from Overture Maps
-- and merging them into a single polygon using ST_UNION_AGG.
SET las_vegas_metro_area = (
SELECT
ST_UNION_AGG(geometry)
FROM
`bigquery-public-data.overture_maps.division_area`
WHERE
country = 'US'
AND region = 'US-NV'
AND names.primary IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester')
);
-- Call the PLACES_COUNT_PER_H3 function with our defined area and parameters.
SELECT
*
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
-- Use the metro area geography we just created.
'geography', las_vegas_metro_area,
-- Specify 'coffee_shop' as the place type to count.
'types', ["coffee_shop"],
-- Best practice: Only count places that are currently operational.
'business_status', ['OPERATIONAL'],
-- Set the H3 grid resolution to 8.
'h3_resolution', 8
)
);
تعرض الدالة جدولاً يتضمّن فهرس خلية H3 وشكلها الهندسي وإجمالي عدد المقاهي وعيّنة من معرّفات الأماكن الخاصة بها:

على الرغم من أنّ العدد الإجمالي مفيد، إلا أنّ الاطّلاع على المنافسين الفعليين أمر ضروري.
هذا هو المكان الذي ننتقل فيه من مجموعة بيانات Places Insights إلى Places API. من خلال استخراج
sample_place_ids من الخلايا التي تتضمّن أعلى نتيجة ملاءمة معدَّلة،
يمكننا طلب Place Details
API لاسترداد تفاصيل غنية
لكل منافس، مثل اسمه وعنوانه وتقييمه وموقعه الجغرافي.
يتطلّب ذلك مقارنة نتائج الاستعلام السابق الذي تم فيه إنشاء نتيجة الملاءمة بالاستعلام PLACES_COUNT_PER_H3. يمكن استخدام فهرس خلايا H3 للحصول على أعداد المقاهي ومعرّفاتها من الخلايا التي تتضمّن أعلى نتيجة ملاءمة معدَّلة.
يوضّح رمز Python هذا كيفية إجراء هذه المقارنة.
# Isolate the Top 5 Most Suitable H3 Cells
top_suitability_cells = gdf_suitability.head(5)
# Extract the 'h3_index' values from these top 5 cells into a list.
top_h3_indexes = top_suitability_cells['h3_index'].tolist()
print(f"The top 5 H3 indexes are: {top_h3_indexes}")
# Now, we find the rows in our DataFrame where the
# 'h3_cell_index' matches one of the indexes from our top 5 list.
coffee_counts_in_top_zones = gdf_coffee_shops[
gdf_coffee_shops['h3_cell_index'].isin(top_h3_indexes)
]
بعد أن أصبح لدينا قائمة بمعرّفات الأماكن الخاصة بالمقاهي المتوفّرة ضمن خلايا H3 التي تتضمّن أعلى درجة ملاءمة، يمكن طلب المزيد من التفاصيل حول كل مكان.
ويمكن إجراء ذلك إما عن طريق إرسال طلب إلى Place Details API مباشرةً لكل معرّف مكان، أو باستخدام مكتبة برامج للعملاء لتنفيذ عملية الاستدعاء. تذكَّر ضبط المَعلمة
FieldMask
لطلب البيانات التي تحتاج إليها فقط.
أخيرًا، نجمع كل شيء في مخطط مرئي واحد وفعّال. ننشئ خريطة مساحية للون الأرجواني كطبقة أساسية، ثم نضيف دبابيس لكل مقهى تم استرجاعه من Places API. تقدّم هذه الخريطة النهائية نظرة سريعة تجمع كل تحليلاتنا: تشير المناطق الأرجوانية الداكنة إلى الإمكانات، وتشير الدبابيس الخضراء إلى واقع السوق الحالي.

من خلال البحث عن مربّعات باللون الأرجواني الداكن لا تحتوي على دبابيس أو تحتوي على عدد قليل منها، يمكننا تحديد المناطق التي توفّر أفضل فرصة لإنشاء موقع جغرافي جديد.

تحتوي الخليتان أعلاه على نتيجة ملاءمة عالية، ولكن هناك بعض الفجوات الواضحة التي يمكن أن تكون مواقع محتملة لمقهانا الجديد.
الخاتمة
في هذا المستند، انتقلنا من سؤال على مستوى الولاية حول أين يجب التوسّع؟ إلى إجابة محلية مستندة إلى البيانات. من خلال دمج مجموعات بيانات مختلفة وتطبيق منطق مخصّص للنشاط التجاري، يمكنك تقليل المخاطر المرتبطة باتخاذ قرار تجاري كبير بشكل منهجي. يوفر سير العمل هذا، الذي يجمع بين نطاق BigQuery وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثرائه وثر
الخطوات التالية
- يمكنك تعديل سير العمل هذا باستخدام منطق نشاطك التجاري والمناطق الجغرافية المستهدَفة ومجموعات البيانات الخاصة بك.
- استكشِف حقول البيانات الأخرى في مجموعة بيانات "إحصاءات الأماكن"، مثل عدد المراجعات ومستويات الأسعار وتقييمات المستخدمين، لإثراء نموذجك بشكل أكبر.
- يمكنك إعداد هذه العملية بشكل آلي لإنشاء لوحة بيانات داخلية لاختيار المواقع الإلكترونية، ويمكن استخدامها لتقييم الأسواق الجديدة بشكل ديناميكي.
الاطّلاع على مزيد من التفاصيل في المستندات:
- نظرة عامة حول "إحصاءات الأماكن"
- وظائف "إحصاءات حول الأماكن"
- BigQuery Geospatial Analytics
- Places API
المساهمون
هنريك فالف | مهندس DevX