Структурированные данные для наборов данных (Dataset, DataCatalog, DataDownload)
В поиске будет легче найти набор данных, если добавить о нем информацию в виде структурированных данных, таких как название, описание, имя автора и обозначение формата. Google стремится упростить поиск наборов данных из самых разных областей, включая медицину и биологию, социальные науки, машинное обучение и многое другое. Поэтому мы рекомендуем использовать стандартизированные метаданные, в частности описанные на сайте schema.org.
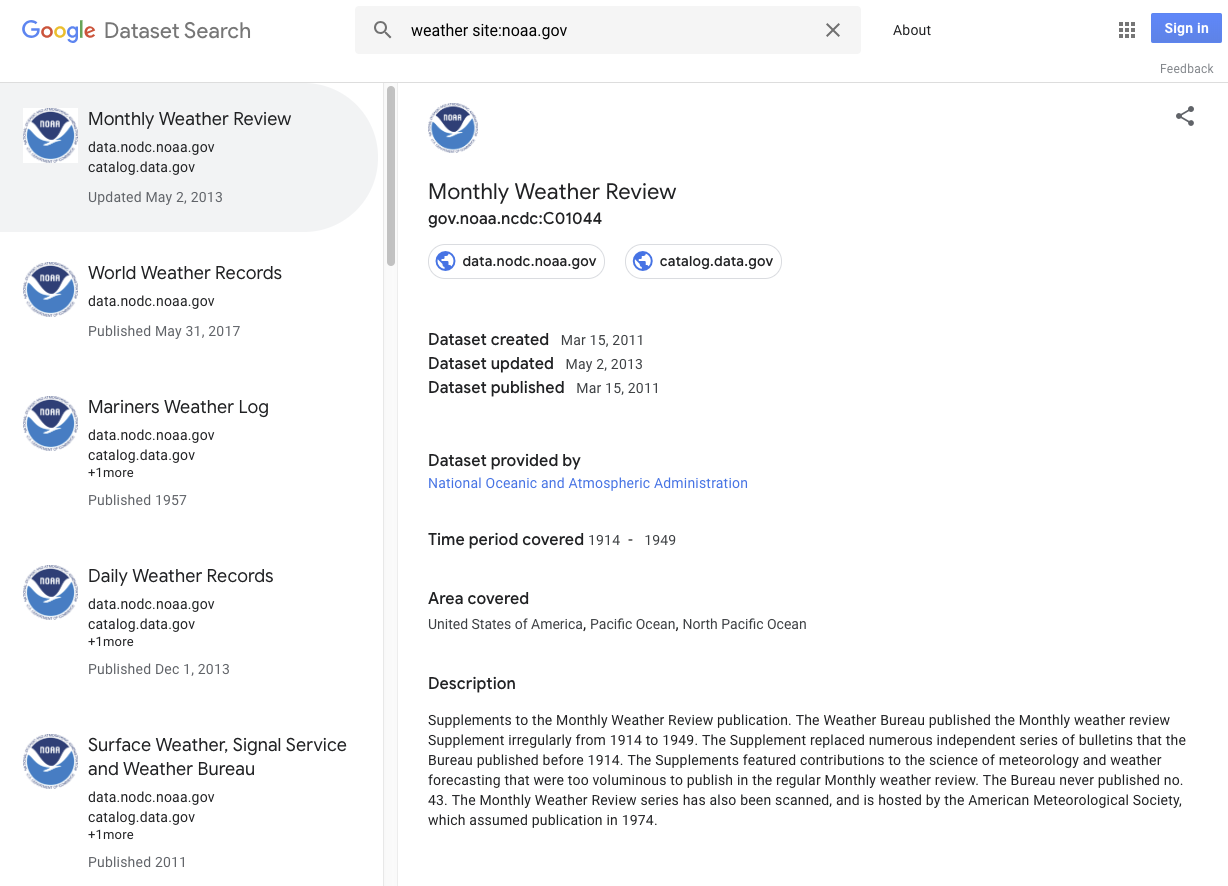
Примеры наборов данных:
- таблица или CSV-файл с определенной информацией;
- систематизированная группа таблиц;
- файл в проприетарном формате, содержащий определенные данные;
- группа файлов, которые в совокупности представляют полезный набор данных;
- структурированный объект с данными в другом формате, который можно загрузить в специальный инструмент для обработки;
- данные, полученные с помощью съемки изображений;
- файлы машинного обучения, например определения структур нейронной сети или параметры обучения.
Как добавить структурированные данные
Структурированные данные – стандартизированный формат, который позволяет предоставлять поисковым системам информацию о странице и классифицировать ее контент. Подробнее о принципах работы структурированных данных…
Ниже в общих чертах описано, как создать, проверить и добавить на сайт структурированные данные.
- Добавьте обязательные свойства. Узнайте, в каких частях страницы нужно размещать структурированные данные выбранного вами формата.
- Следуйте рекомендациям.
- Протестируйте свой код с помощью инструмента проверки расширенных результатов. Если будут обнаружены критические ошибки, устраните их. Мы также рекомендуем устранить некритические ошибки, отмеченные в инструменте. Это может привести к повышению качества структурированных данных, хотя страницы будут подходить для создания расширенных результатов и без этого.
- Опубликуйте страницу и с помощью инструмента проверки URL выясните, как она выглядит для робота Googlebot. Убедитесь, что доступ Google к странице не заблокирован файлом robots.txt или метатегом
noindexи авторизация на ней не требуется. Если все в порядке, то запросите повторное сканирование ваших URL. - Отправляйте нам файл Sitemap, чтобы информировать нас об изменениях на сайте. Отправку такого файла можно автоматизировать с помощью Search Console Sitemap API.
Как удалить набор данных из результатов поиска наборов данных
Если вы не хотите, чтобы набор данных показывался в результатах поиска Google, укажите с помощью тега robots meta, как его следует индексировать. Напоминаем, что прежде чем внесенные вами изменения отразятся в Поиске наборов данных, может пройти несколько дней или даже недель (в зависимости от расписания сканирования).
Наш подход к разметке наборов данных
Google распознает разметку schema.org Dataset или аналогичные элементы разметки для веб-страниц в формате DCAT, разработанные организацией W3C. Также мы проводим эксперимент по поддержке структурированных данных в формате CSVW от W3C и по мере выхода новых рекомендаций в отношении этой разметки планируем менять принципы ее обработки в соответствии с ними. Более подробная информация доступна в этой статье.
Примеры
В этом разделе приведены примеры кодов с использованием синтаксиса JSON-LD и schema.org (рекомендуемый вариант) для наборов данных в инструменте проверки расширенных результатов. Аналогичную терминологию schema.org можно применять для форматов RDFa 1.1 и Microdata. Для описания метаданных также можно использовать словарь DCAT от W3C. Примеры кода ниже основаны на реальном описании набора данных.
Нажмите кнопку ниже, чтобы увидеть пример кода JSON-LD для набора данных:
<html>
<head>
<title>NCDC Storm Events Database</title>
<script type="application/ld+json">
{
"@context":"https://schema.org/",
"@type":"Dataset",
"name":"NCDC Storm Events Database",
"description":"Storm Data is provided by the National Weather Service (NWS) and contain statistics on...",
"url":"https://catalog.data.gov/dataset/ncdc-storm-events-database",
"sameAs":"https://gis.ncdc.noaa.gov/geoportal/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510",
"identifier": ["https://doi.org/10.1000/182",
"https://identifiers.org/ark:/12345/fk1234"],
"keywords":[
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > CYCLONES",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > DROUGHT",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FOG",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FREEZE"
],
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"isAccessibleForFree" : true,
"hasPart" : [
{
"@type": "Dataset",
"name": "Sub dataset 01",
"description": "Informative description of the first subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 01 creator"
}
},
{
"@type": "Dataset",
"name": "Sub dataset 02",
"description": "Informative description of the second subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 02 creator"
}
}
],
"creator":{
"@type":"Organization",
"url": "https://www.ncei.noaa.gov/",
"name":"OC/NOAA/NESDIS/NCEI > National Centers for Environmental Information, NESDIS, NOAA, U.S. Department of Commerce",
"contactPoint":{
"@type":"ContactPoint",
"contactType": "customer service",
"telephone":"+1-828-271-4800",
"email":"ncei.orders@noaa.gov"
}
},
"funder":{
"@type": "Organization",
"sameAs": "https://ror.org/00tgqzw13",
"name": "National Weather Service"
},
"includedInDataCatalog":{
"@type":"DataCatalog",
"name":"data.gov"
},
"distribution":[
{
"@type":"DataDownload",
"encodingFormat":"CSV",
"contentUrl":"https://www.ncdc.noaa.gov/stormevents/ftp.jsp"
},
{
"@type":"DataDownload",
"encodingFormat":"XML",
"contentUrl":"https://gis.ncdc.noaa.gov/all-records/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510"
}
],
"temporalCoverage":"1950-01-01/2013-12-18",
"spatialCoverage":{
"@type":"Place",
"geo":{
"@type":"GeoShape",
"box":"18.0 -65.0 72.0 172.0"
}
}
}
</script>
</head>
<body>
</body>
</html>Пример кода RDFa для набора данных, в котором используется словарь DCAT (он не поддерживается в инструменте проверки расширенных результатов):
<article about="/node/1234" typeof="dcat:Dataset">
<dl>
<dt>Name:</dt>
<dd property="dc:title">ACME Inc Cash flow data</dd>
<dt>Identifiers:</dt>
<dd property="dc:identifier">https://doi.org/10.1000/182</dd>
<dd property="dc:identifier">https://identifiers.org/ark:/12345/fk1234</dd>
<dt>Description:</dt>
<dd property="dc:description">Financial Statements - Consolidated Statement of Cash Flows</dd>
<dt>Category:</dt>
<dd rel="dc:subject">Financial</dd>
<dt class="field-label">Downloads:</dt>
<dd>
<ul>
<li>
<a rel="dcat:distribution" href="Consolidated_Statement_of_Cash_Flows_en.csv"><span property="dcat:mediaType" content="text/csv" >Consolidated_Statement_of_Cash_Flows_en.csv</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/Consolidated_Statement_of_Cash_Flows_en.xls"><span property="dcat:mediaType" content="application/vnd.ms-excel">Consolidated_Statement_of_Cash_Flows_en.xls</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/consolidated_statement_of_cash_flows_en.xml"><span property="dcat:mediaType" content="application/xml">consolidated_statement_of_cash_flows_en.xml</span></a>
</li>
</ul>
</dd>
</dl>
</article>Правила
На сайте должны соблюдаться требования к структурированным данным. Кроме того, советуем следовать рекомендациям в отношении файлов Sitemap, а также источников и происхождения данных.
Рекомендации в отношении файлов Sitemap
Чтобы помочь Google найти ваши URL, используйте файлы Sitemap. Благодаря этим файлам и разметке sameAs можно указать, как найти описания наборов данных на сайте.
Если вы размещаете наборы данных в хранилище, скорее всего, у вас есть два типа страниц: канонические (целевые) для каждого набора и страницы со списками наборов (например, группы наборов или результаты поиска). Рекомендуем добавлять структурированные данные о наборах на канонические страницы. Если вы добавили разметку на страницу с несколькими копиями набора данных (например, с результатами поиска), используйте свойство sameAs, чтобы указать канонический URL.
Рекомендации в отношении источников и происхождения
Открытые наборы данных часто создаются на основе других наборов, агрегируются и публикуются повторно. Мы подготовили базовые инструкции, из которых вы узнаете, как действовать в подобных случаях. Если набор данных создан на основе другого набора (например, скопирован), следуйте рекомендациям ниже.
- Если набор данных или описание публикуются повторно, укажите исходные канонические URL оригинала с помощью свойства
sameAs. ЭлементsameAsдолжен однозначно идентифицировать набор данных, т. е. два разных набора не должны иметь одинаковые значенияsameAs. - Если ранее опубликованный набор данных (включая его метаданные) был существенно изменен, используйте свойство
isBasedOn. - Если набор данных создан на основе нескольких других наборов, используйте свойство
isBasedOn. - Чтобы указать подходящие цифровые идентификаторы объекта (ЦИО) или компактные идентификаторы, используйте свойство
identifier. Если в наборе данных представлено больше одного идентификатора, добавьте несколько свойствidentifier. Если вы используете JSON-LD, применяйте синтаксис списка JSON.
Мы продолжаем улучшать эти рекомендации, в частности в отношении источников, версий и дат, которые относятся к временным рядам. В этом нам помогают ваши отзывы. Присоединяйтесь к обсуждениям!
Рекомендации в отношении текстовых свойств
Google Поиск наборов данных в любом случае обрабатывает только первые 5000 символов текста в свойстве. Старайтесь не превышать это ограничение. Названия и заголовки обычно состоят всего из нескольких слов или одного короткого предложения.
Известные ошибки и предупреждения
Инструмент проверки расширенных результатов и похожие сервисы могут находить ошибки и показывать предупреждения, на которые не стоит обращать внимания. Системам проверки может потребоваться также контактная информация, в том числе свойство contactType. Примеры значений: customer service, emergency, journalist, newsroom, public engagement.
Также можно игнорировать сообщения о том, что csvw:Table – недопустимое значение свойства mainEntity.
Типы структурированных данных
Чтобы ваш контент мог показываться в расширенных результатах, необходимо задать все обязательные свойства. Вы также можете добавить рекомендуемые свойства, чтобы пользователям было удобнее изучать информацию.
Для проверки разметки рекомендуем использовать инструмент проверки расширенных результатов.
Ваша основная цель – указать информацию о наборе данных (его метаданные) и описать его содержимое. Например, в метаданных указана тема набора, измеряемые переменные, создатель набора и т. д. При этом конкретные значения переменных не указываются.
Dataset
Полное описание типа Dataset приведено на странице schema.org/Dataset.
Вы можете добавить дополнительную информацию о публикации набора данных, например лицензию, время публикации, ЦИО или значение sameAs, указывающее на каноническую версию набора в другом хранилище. Чтобы указать информацию о происхождении и лицензии, используйте элементы identifier, license и sameAs.
Google поддерживает следующие свойства:
| Обязательные свойства | |
|---|---|
description
|
Text
Краткое описание набора данных. Правила
|
name
|
Text
Информативное название набора данных. Пример: "Высота снежного покрова в Северном полушарии". Правила
Правильно: Неправильно: |
| Рекомендуемые свойства | |
|---|---|
alternateName
|
Text
Альтернативные имена, которые использовались для ссылки на этот набор данных: псевдонимы или сокращения. Пример в формате JSON-LD: "name": "The Quick, Draw! Dataset" "alternateName": ["Quick Draw Dataset", "quickdraw-dataset"] |
creator
|
Person или Organization
Создатель или автор этого набора данных. Для идентификации отдельных лиц используйте в свойстве "creator": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0000", "givenName": "Jane", "familyName": "Foo", "name": "Jane Foo" }, { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0001", "givenName": "Jo", "familyName": "Bar", "name": "Jo Bar" }, { "@type": "Organization", "sameAs": "https://ror.org/xxxxxxxxx", "name": "Fictitious Research Consortium" } ] |
citation
|
Text или CreativeWork
Ссылки на научные статьи, которые поставщик данных рекомендует процитировать в дополнение к основному набору. Добавьте цитирование в набор данных вместе с такими свойствами, как "citation": "https://doi.org/10.1111/111" "citation": "https://identifiers.org/pubmed:11111111" "citation": "https://identifiers.org/arxiv:0111.1111v1" "citation": "Doe J (2014) Influence of X ... https://doi.org/10.1111/111" Дополнительные правила
|
funder
|
Person или Organization
Имя спонсора или название организации-спонсора. Для идентификации отдельных лиц используйте в свойстве "funder": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0002", "givenName": "Jane", "familyName": "Funder", "name": "Jane Funder" }, { "@type": "Organization", "sameAs": "https://ror.org/yyyyyyyyy", "name": "Fictitious Funding Organization" } ] |
hasPart или isPartOf
|
URL или Dataset
Если набор данных состоит из нескольких наборов небольшого размера, укажите на это с помощью свойства "hasPart" : [ { "@type": "Dataset", "name": "Sub dataset 01", "description": "Informative description of the first subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 01 creator" } }, { "@type": "Dataset", "name": "Sub dataset 02", "description": "Informative description of the second subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 02 creator" } } ] "isPartOf" : "https://example.com/aggregate_dataset" |
identifier
|
URL, Text, или PropertyValue
Идентификатор набора данных, например ЦИО или компактный. Если в наборе данных не один идентификатор, добавьте несколько свойств |
isAccessibleForFree
|
Boolean
Указывает, является ли набор данных бесплатным. |
keywords
|
Text
Ключевые слова, характеризующие набор данных. |
license
|
URL или CreativeWork
Лицензия, по которой распространяется набор данных. Примеры приведены ниже. "license" : "https://creativecommons.org/publicdomain/zero/1.0/" "license" : { "@type": "CreativeWork", "name": "Custom license", "url": "https://example.com/custom_license" } Дополнительные правила
|
measurementTechnique
|
Text или URL
Технология или методология, используемая в наборе данных, которая соответствует переменным, описанным в свойстве |
sameAs
|
URL
URL веб-страницы с подробной информацией, которая позволяет однозначно идентифицировать набор данных. |
spatialCoverage |
Text или Place
Вы можете указать одну точку, описывающую пространственный аспект набора данных. Используйте это свойство, только если у набора есть пространственное измерение. Например, это может быть точка, где были собраны все измерения, или координаты ограничивающего параллелепипеда площади. Точки "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoCoordinates", "latitude": 39.3280, "longitude": 120.1633 } } Фигуры Используйте элемент "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoShape", "box": "39.3280 120.1633 40.445 123.7878" } } Координаты в свойствах Названия мест "spatialCoverage:" "Tahoe City, CA" |
temporalCoverage |
Text
Период времени, к которому относятся данные в наборе. Используйте это свойство, только если у набора есть временное измерение. Для описания периодов и моментов времени в schema.org используется стандарт ISO 8601. Вы можете указывать даты другим способом, если он подходит лучше. Обозначайте неограниченные периоды двумя десятичными знаками ( Дата "temporalCoverage" : "2008" Период времени "temporalCoverage" : "1950-01-01/2013-12-18" Неограниченный период "temporalCoverage" : "2013-12-19/.." |
variableMeasured
|
Text или PropertyValue
Переменная в наборе данных, измерение которой выполняется. Например, это может быть температура или давление. |
version
|
Text или Number
Номер версии набора. |
url
|
URL
Адрес страницы с описанием набора данных. |
DataCatalog
Полное описание типа DataCatalog приведено на странице schema.org/DataCatalog.
Наборы данных часто публикуются в хранилищах, содержащих множество других наборов. Один и тот же набор может находиться в нескольких хранилищах. Указывайте нужный каталог данных с помощью прямой ссылки на него. Используйте свойства, перечисленные ниже.
| Рекомендуемые свойства | |
|---|---|
includedInDataCatalog
|
DataCatalog
Каталог, в котором размещен набор данных.
|
DataDownload
Полное описание типа DataDownload приведено на странице schema.org/DataDownload. Если набор данных можно скачать, укажите не только свойства Dataset, но и свойства DataDownload, перечисленные ниже.
Свойство distribution описывает, как получить набор данных, поскольку URL набора часто указывает на целевую страницу с описанием набора, а не на страницу для скачивания. Свойство distribution указывает, где скачать данные и в каком формате. У этого свойства может быть несколько значений. Например, версия в формате CSV может быть доступна по одному URL, а версия в формате Excel – по другому.
| Обязательные свойства | |
|---|---|
distribution.contentUrl
|
URL
Ссылка для скачивания. |
| Рекомендуемые свойства | |
|---|---|
distribution
|
DataDownload
Описание места, из которого скачивается набор данных, и формата файла для скачивания.
|
distribution.encodingFormat
|
Text или URL
Формат дистрибутива.
|
Табличные наборы данных
Табличным называют набор данных, организованный преимущественно в виде сетки из строк и столбцов. Для страниц, содержащих табличные наборы данных, можно создавать более явную разметку на основе базовых инструкций, приведенных выше. В настоящее время Google может обрабатывать данные в формате CSVW (CSV on the Web), размещенные на HTML-странице параллельно с табличным контентом, предназначенным для пользователей.
Ниже приведен пример кода в формате CSVW JSON-LD для небольшой таблицы. Инструмент проверки расширенных результатов будет предупреждать вас о некоторых ошибках, которые можно игнорировать.
<html>
<head>
<title>American Humane Association</title>
<script type="application/ld+json">
{
"@context": ["https://schema.org", {"csvw": "https://www.w3.org/ns/csvw#"}],
"@type": "Dataset",
"name":"AMERICAN HUMANE ASSOCIATION",
"description": "ProPublica's Nonprofit Explorer lets you view summaries of 2.2 million tax returns from tax-exempt organizations and see financial details such as their executive compensation and revenue and expenses. You can browse raw IRS data released since 2013 and access over 9.4 million tax filing documents going back as far as 2001.",
"publisher": {
"@type": "Organization",
"name": "ProPublica"
},
"mainEntity" : {
"@type" : "csvw:Table",
"csvw:tableSchema": {
"csvw:columns": [
{
"csvw:name": "Year",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization name",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization address",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization NTEE Code",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Total functional expenses ($)",
"csvw:datatype": "integer",
"csvw:cells": [
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
}]
}]
}
}
}
</script>
</head>
<body>
</body>
</html>Сбор статистики по расширенным результатам в Search Console
С помощью Search Console вы можете собирать данные об эффективности страниц вашего ресурса в Google Поиске. Вам не обязательно регистрироваться в этом сервисе, чтобы ваши страницы попали в результаты поиска. Однако это позволит узнать, как роботы Google воспринимают сайт, и упростить им его обработку. Рекомендуем проверять информацию в Search Console в следующих случаях:
- После первого размещения структурированных данных
- После выпуска новых шаблонов или обновления кода
- При регулярном анализе трафика
После первого размещения структурированных данных
Когда ваши страницы будут проиндексированы, проверьте их на наличие ошибок с помощью отчета о статусе расширенных результатов. Желательно, чтобы количество объектов с правильной разметкой выросло, а число объектов с ошибками – нет. Если в структурированных данных будут обнаружены ошибки, примите следующие меры:
- Устраните проблемы в объектах.
- Проверьте исправленную страницу, чтобы узнать, обнаруживаются ли ошибки.
- Запросите проверку ресурса, используя отчет о статусе расширенных результатов.
После выпуска новых шаблонов или обновления кода
Если вы внесли значительные изменения на сайт, проверьте, не увеличилось ли число недействительных объектов, связанных со структурированными данными.- Увеличилось число недействительных объектов? Возможно, вы создали шаблон, с которым что-то не так, или имеющийся шаблон используется некорректно.
- Уменьшилось число действительных элементов, но не увеличилось количество недействительных? Возможно, на ваших страницах не размещены структурированные данные. Выяснить, с чем связаны ошибки, можно при помощи инструмента проверки URL.
При регулярном анализе трафика
Анализировать трафик сайта из Google Поиска можно с помощью отчета об эффективности. Из этого отчета вы узнаете, как часто страница появляется в Поиске в виде расширенного результата, с какой регулярностью пользователи нажимают на нее и какова ее средняя позиция в результатах поиска. Эти сведения также можно автоматически получать с помощью Search Console API.Устранение неполадок
Если у вас возникли трудности с добавлением или отладкой структурированных данных, вам помогут ресурсы и сведения, доступные по приведенным ниже ссылкам.
- Если вы используете систему управления контентом (CMS) или поручили настройку сайта другому человеку, обратитесь за помощью к нему или разработчику CMS. Не забудьте переслать ему сообщения о проблеме, полученные вами в Search Console.
- Google не гарантирует показ вашего контента в результатах поиска, которые формируются на основе структурированных данных. Возможные причины, по которым ваши материалы могут не показываться в виде расширенных результатов, перечислены в общих рекомендациях по использованию структурированных данных.
- Ознакомьтесь со списком типичных ошибок в структурированных данных и отчетом о структурированных данных, которые невозможно обработать, и проверьте, правильно ли вы добавили разметку.
- Если мы вручную приняли меры в отношении страницы, недопустимые структурированные данные на ней будут игнорироваться до тех пор, пока вы не исправите код. При этом сама страница может появляться в результатах поиска и дальше. Чтобы устранить проблемы со структурированными данными, воспользуйтесь отчетом о мерах, принятых вручную.
- Ещё раз изучите рекомендации, чтобы выяснить, соответствует ли им ваш контент. Проблема может быть связана со спамом в контенте или разметке, а не с ошибками в синтаксисе. Тогда ее не получится выявить с помощью инструмента проверки расширенных результатов.
- Узнайте, чем может быть вызвано отсутствие расширенных результатов или уменьшение их общего количества.
- Робот Googlebot сканирует и индексирует страницы не сразу после обновления контента. С момента публикации страницы может пройти несколько дней, пока Google обнаружит и просканирует ее. Мы собрали на отдельной странице ответы на часто задаваемые вопросы о сканировании и индексировании.
- В случае необходимости задавайте вопросы на форуме Центра Google Поиска
Набора данных нет в результатах поиска
error Причина проблемы. Страница ещё не просканирована или на ней нет разметки, относящейся к набору данных.
done Как устранить проблему
- С помощью инструмента проверки расширенных результатов протестируйте страницу, которая должна отображаться в результатах поиска по набору данных (для этого нужно указать в интерфейсе инструмента ее URL). Если появляется сообщение "Этот инструмент проверки не находит на выбранной странице контент, который можно показывать в расширенных результатах поиска" или "Для показа расширенных результатов подходит не вся разметка", значит на странице нет разметки для набора данных или она внедрена некорректно. О том, как решить эту проблему, читайте в разделе Как добавлять структурированные данные.
- Если на странице есть структурированные данные, возможно, что она ещё не обработана Google. Попробуйте проверить статус ее сканирования в Search Console.
Логотип компании отсутствует или неправильно отображается в результатах поиска
error Причина проблемы. На странице может отсутствовать разметка schema.org для логотипа компании, или ваша компания не зарегистрирована в Google.
done Как устранить проблему
- Добавьте на страницу структурированные данные для логотипов.
- Отправьте данные о своей компании в Google.