Veri kümesi (Dataset, DataCatalog, DataDownload) yapılandırılmış verisi
Bir veri kümesinin adı, açıklaması, oluşturucusu ve dağıtım biçimleri gibi destekleyici bilgileri yapılandırılmış veri olarak sağladığınızda söz konusu veri kümesini Veri Kümesi Arama aracında bulmak daha kolay olur. Google'ın veri kümesi keşfine yaklaşımı, schema.org'dan ve veri kümelerini açıklayan sayfalara eklenebilecek diğer meta veri standartlarından faydalanır. Bu işaretlemenin amacı; yaşam bilimleri, sosyal bilimler, makine öğrenimi gibi alanlardan, şehre ve devlete ait verilerden elde edilen veri kümelerinin keşfedilmesini kolaylaştırmaktır.
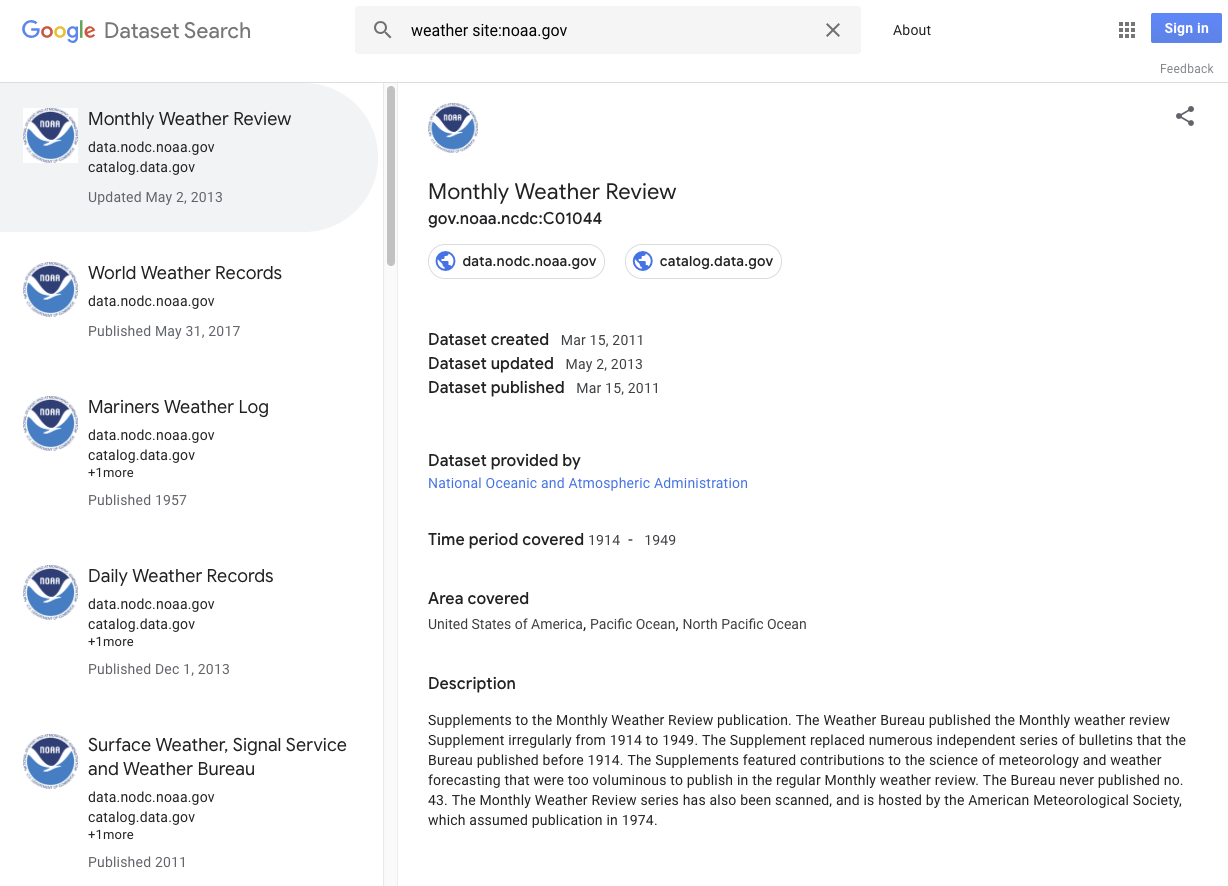
Burada, veri kümesi olarak nitelendirilebilecek bazı örnekleri görebilirsiniz:
- Bazı veriler içeren bir tablo veya CSV dosyası
- Düzenlenmiş bir tablo koleksiyonu
- Veri içeren özel bir biçimdeki bir dosya
- Birlikte anlamlı bir veri kümesi oluşturan dosya koleksiyonu
- İşlemek üzere özel bir araca yüklemek isteyebileceğiniz, başka biçimde veriler içeren bir yapılandırılmış nesne
- Veri yakalayan resimler
- Eğitilmiş parametreler veya sinir ağı yapısı tanımları gibi makine öğrenimiyle ilgili dosyalar
Yapılandırılmış veri ekleme
Yapılandırılmış veri, bir sayfa hakkında bilgi sağlamak ve sayfa içeriğini sınıflandırmak için kullanılan standart bir biçimdir. Yapılandırılmış veri konusunda yeniyseniz yapılandırılmış verinin nasıl çalıştığı hakkında daha fazla bilgi edinebilirsiniz.
Aşağıda, yapılandırılmış verinin nasıl oluşturulacağı, test edileceği ve yayınlanacağı hakkında bir genel bakış sunulmuştur.
- Zorunlu özellikleri ekleyin. Kullandığınız biçime bağlı olarak sayfada yapılandırılmış verilerin nereye ekleneceğini öğrenin.
- Yönergeleri uygulayın.
- Zengin Sonuçlar Testini kullanarak kodunuzu doğrulayın ve kritik hataları düzeltin. Ayrıca, araçta işaretlenmiş olabilecek kritik olmayan sorunları düzeltmek de yapılandırılmış verilerinizin kalitesini iyileştirmeye yardımcı olabilir (ancak bunların düzeltilmesi, zengin sonuçlara uygunluk için gerekli değildir).
- Yapılandırılmış verinizi içeren birkaç sayfa dağıtıp Google'ın sayfayı nasıl gördüğünü test etmek için URL Denetleme aracını kullanın. Google'ın sayfanıza erişebildiğinden ve bir robots.txt dosyası,
noindexetiketi veya giriş gereksinimleri tarafından engellenmediğinden emin olun. Sayfa düzgün görünüyorsa Google'dan URL'lerinizi yeniden taramasını isteyebilirsiniz. - İleride yapılacak değişiklikler konusunda Google'a bilgi vermeye devam etmek için site haritası gönderin. Bu işlemi Search Console Sitemap API ile otomatikleştirebilirsiniz.
Veri Kümesi Arama sonuçlarından veri kümesi silme
Veri Seti Arama sonuçlarında bir veri kümesinin görünmesini istemiyorsanız veri kümenizin nasıl dizine eklendiğini kontrol etmek için robots metaetiketini kullanın. Değişikliklerin Veri Seti Arama'ya yansımasının biraz zaman alabileceğini (tarama zamanına bağlı olarak günler veya haftalar sürebilir) unutmayın.
Veri kümesi keşfi konusundaki yaklaşımımız
Web sayfalarındaki veri kümeleriyle ilgili yapılandırılmış verileri, schema.org Dataset işaretlemesini veya W3C'nin Veri Kataloğu Sözlüğü (DCAT) biçiminde gösterilen eşdeğer yapıları kullanarak anlayabiliriz. Ayrıca, yapılandırılmış verilere yönelik deneysel desteği W3C CSVW doğrultusunda araştırıyoruz ve veri kümesi açıklamasına yönelik en iyi uygulamalar ortaya çıktıkça yaklaşımımızı geliştirmeyi ve uyarlamayı umuyoruz. Veri kümesi keşfi konusundaki yaklaşımımız hakkında daha fazla bilgi için Veri kümelerinin keşfini kolaylaştırma bölümüne bakın.
Örnekler
Zengin Sonuçlar Testi'nde JSON-LD ve schema.org söz dizimini (tercih edilen) kullanan veri kümeleriyle ilgili bir örneği burada bulabilirsiniz. Aynı schema.org sözlüğü, RDFa 1.1 veya Mikro veri söz dizimlerinde de kullanılabilir. Meta verileri açıklamak için W3C DCAT sözlüğünü de kullanabilirsiniz. Aşağıdaki örnek, gerçek bir veri kümesi açıklamasına dayanmaktadır.
Bir JSON-LD veri kümesi örneğini burada bulabilirsiniz:
<html>
<head>
<title>NCDC Storm Events Database</title>
<script type="application/ld+json">
{
"@context":"https://schema.org/",
"@type":"Dataset",
"name":"NCDC Storm Events Database",
"description":"Storm Data is provided by the National Weather Service (NWS) and contain statistics on...",
"url":"https://catalog.data.gov/dataset/ncdc-storm-events-database",
"sameAs":"https://gis.ncdc.noaa.gov/geoportal/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510",
"identifier": ["https://doi.org/10.1000/182",
"https://identifiers.org/ark:/12345/fk1234"],
"keywords":[
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > CYCLONES",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > DROUGHT",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FOG",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FREEZE"
],
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"isAccessibleForFree" : true,
"hasPart" : [
{
"@type": "Dataset",
"name": "Sub dataset 01",
"description": "Informative description of the first subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 01 creator"
}
},
{
"@type": "Dataset",
"name": "Sub dataset 02",
"description": "Informative description of the second subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 02 creator"
}
}
],
"creator":{
"@type":"Organization",
"url": "https://www.ncei.noaa.gov/",
"name":"OC/NOAA/NESDIS/NCEI > National Centers for Environmental Information, NESDIS, NOAA, U.S. Department of Commerce",
"contactPoint":{
"@type":"ContactPoint",
"contactType": "customer service",
"telephone":"+1-828-271-4800",
"email":"ncei.orders@noaa.gov"
}
},
"funder":{
"@type": "Organization",
"sameAs": "https://ror.org/00tgqzw13",
"name": "National Weather Service"
},
"includedInDataCatalog":{
"@type":"DataCatalog",
"name":"data.gov"
},
"distribution":[
{
"@type":"DataDownload",
"encodingFormat":"CSV",
"contentUrl":"https://www.ncdc.noaa.gov/stormevents/ftp.jsp"
},
{
"@type":"DataDownload",
"encodingFormat":"XML",
"contentUrl":"https://gis.ncdc.noaa.gov/all-records/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510"
}
],
"temporalCoverage":"1950-01-01/2013-12-18",
"spatialCoverage":{
"@type":"Place",
"geo":{
"@type":"GeoShape",
"box":"18.0 -65.0 72.0 172.0"
}
}
}
</script>
</head>
<body>
</body>
</html>Aşağıda, DCAT sözlüğünü kullanan bir RDFa veri kümesi örneği verilmiştir (Zengin Sonuçlar Testi'nde desteklenmez):
<article about="/node/1234" typeof="dcat:Dataset">
<dl>
<dt>Name:</dt>
<dd property="dc:title">ACME Inc Cash flow data</dd>
<dt>Identifiers:</dt>
<dd property="dc:identifier">https://doi.org/10.1000/182</dd>
<dd property="dc:identifier">https://identifiers.org/ark:/12345/fk1234</dd>
<dt>Description:</dt>
<dd property="dc:description">Financial Statements - Consolidated Statement of Cash Flows</dd>
<dt>Category:</dt>
<dd rel="dc:subject">Financial</dd>
<dt class="field-label">Downloads:</dt>
<dd>
<ul>
<li>
<a rel="dcat:distribution" href="Consolidated_Statement_of_Cash_Flows_en.csv"><span property="dcat:mediaType" content="text/csv" >Consolidated_Statement_of_Cash_Flows_en.csv</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/Consolidated_Statement_of_Cash_Flows_en.xls"><span property="dcat:mediaType" content="application/vnd.ms-excel">Consolidated_Statement_of_Cash_Flows_en.xls</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/consolidated_statement_of_cash_flows_en.xml"><span property="dcat:mediaType" content="application/xml">consolidated_statement_of_cash_flows_en.xml</span></a>
</li>
</ul>
</dd>
</dl>
</article>Yönergeler
Siteler, yapılandırılmış veri yönergelerine uymalıdır. Yapılandırılmış veri yönergelerine ek olarak, aşağıdaki site haritasının yanı sıra kaynak ve köken ile ilgili en iyi uygulamaları öneririz.
Site haritası en iyi uygulamaları
Google’ın URL’lerinizi bulmasına yardımcı olmak için bir site haritası dosyası kullanın. Site haritası dosyalarının ve sameAs işaretlemesinin kullanılması, veri kümesi açıklamalarının sitenizde nasıl yayınlandığını belgelemeye yardımcı olur.
Bir veri kümesi havuzunuz varsa muhtemelen en az iki sayfa türünüz olur: her bir veri kümesi için standart ("açılış") sayfalar ve birden fazla veri kümesinin listelendiği sayfalar (örneğin, arama sonuçları veya bazı veri kümelerinin alt kümeleri). Standart sayfalara bir veri kümesiyle ilgili yapılandırılmış veri eklemenizi öneririz. Arama sonuçları sayfalarındaki girişler gibi veri kümesinin birden çok kopyasına yapılandırılmış veri eklerseniz standart sayfaya bağlantı vermek için sameAs özelliğini kullanın.
Kaynak ve köken en iyi uygulamaları
Açık veri kümelerinin yeniden yayınlanması, toplanması ve başka veri kümelerine dayanması yaygın görülen bir durumdur. Bu, bir veri kümesinin başka bir veri kümesinin kopyası olduğu veya başka bir veri kümesine dayandığı durumları göstermek için kullandığımız yaklaşımın bir ilk taslağıdır.
- Veri kümesi veya açıklamanın başka yerde yayınlanmış materyallerin yeniden yayını olduğu durumlarda, orijinale en uygun standart URL’leri belirtmek için
sameAsözelliğini kullanın.sameAsdeğerinin, veri kümesinin kimliğini açık bir şekilde belirtmesi gerekir. Diğer bir deyişle, iki farklı veri kümesi için aynısameAsdeğerini kullanmayın. - Yeniden yayınlanan veri kümesinin (meta verileri dahil) önemli ölçüde değiştiği durumlarda
isBasedOnözelliğini kullanın. - Bir veri kümesi birkaç orijinalden türetildiğinde veya toplandığında
isBasedOnözelliğini kullanın. - Alakalı Dijital Nesne tanımlayıcılarını (DOI'ler) veya Kompakt Tanımlayıcıları eklemek için
identifierözelliğini kullanın. Veri kümesinde birden fazla tanımlayıcı varsaidentifierözelliğini tekrarlayın. JSON-LD kullanılıyorsa bu, JSON listesi söz dizimi kullanılarak gösterilir.
Önerilerimizi, özellikle köken açıklaması, sürüm oluşturma ve zaman serisi yayınlarıyla ilişkili tarihlerle ilgili geri bildirimlere dayanarak daha iyi hale getirmeyi umuyoruz. Lütfen topluluk tartışmalarına katılın.
Metin özelliği önerileri
Tüm metin özelliklerini en fazla 5.000 karakter ile sınırlandırmanızı öneririz. Google Veri Seti Arama, metin özelliklerinin yalnızca ilk 5.000 karakterini kullanır. Adlar ve başlıklar genellikle birkaç kelimeden veya kısa bir cümleden oluşur.
Bilinen Hatalar ve Uyarılar
Google'ın Zengin Sonuçlar Testi'nde ve diğer doğrulama sistemlerinde hatalar veya uyarılarla karşılaşabilirsiniz. Doğrulama sistemleri, kuruluşların iletişim bilgilerinin contactType içermesi gerektiğini de belirtebilir; faydalı değerler arasında customer service, emergency, journalist, newsroom ve public engagement bulunur.
Ayrıca, mainEntity özelliği için beklenmedik bir değer olan csvw:Table hatalarını yok sayabilirsiniz.
Yapılandırılmış veri türü tanımları
İçeriğinizin zengin sonuç olarak görüntülenmeye uygun olması için gereken özellikleri eklemeniz gerekir. İçeriğiniz hakkında daha fazla bilgi ekleyerek daha iyi bir kullanıcı deneyimi sağlamak için önerilen özellikleri de dahil edebilirsiniz.
İşaretlemenizi doğrulamak için Zengin Sonuçlar Testi'ni kullanabilirsiniz.
Buradaki asıl amaç, bir veri kümesi ile ilgili bilgileri (kümenin meta verileri) açıklamak ve içeriklerini temsil etmektir. Örneğin, veri kümesi meta verileri, veri kümesinin ne hakkında olduğunu, hangi değişkenleri ölçtüğünü, kimin tarafından oluşturulduğunu ve benzer bilgileri belirtir. Örneğin, değişkenler için belirli değerler içermez.
Dataset
Dataset öğesinin tam tanımını schema.org/Dataset adresinde bulabilirsiniz.
Lisans, yayınlanma zamanı, DOI'si veya farklı bir veri havuzundaki veri kümesi standart sürümünü işaret eden bir sameAs özelliği gibi veri kümesinin yayınlanmasıyla ilgili ek bilgileri açıklayabilirsiniz. Köken ve lisans bilgileri sağlayan veri kümeleri için identifier, license ve sameAs ekleyin.
Google tarafından desteklenen özellikler şunlardır:
| Zorunlu özellikler | |
|---|---|
description
|
Text
Veri kümesini açıklayan kısa bir özet. Yönergeler
|
name
|
Text
Veri kümesinin açıklayıcı adı. Örneğin, "Kuzey Yarım Küre'de kar kalınlığı". Yönergeler
Önerilen: İki farklı veri kümesi için Önerilmeyen: İki farklı veri kümesi için |
| Önerilen özellikler | |
|---|---|
alternateName
|
Text
Bu veri kümesini tanımlamak için kullanılmış olan takma adlar veya kısaltmalar gibi alternatif adlar. Örneğin (JSON-LD biçiminde): "name": "The Quick, Draw! Dataset" "alternateName": ["Quick Draw Dataset", "quickdraw-dataset"] |
creator
|
Person veya
Organization
Bu veri kümesinin üreticisi veya yazarı. Kullanıcıları benzersiz bir şekilde tanımlamak için "creator": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0000", "givenName": "Jane", "familyName": "Foo", "name": "Jane Foo" }, { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0001", "givenName": "Jo", "familyName": "Bar", "name": "Jo Bar" }, { "@type": "Organization", "sameAs": "https://ror.org/xxxxxxxxx", "name": "Fictitious Research Consortium" } ] |
citation
|
Text veya CreativeWork
Alıntı yapılan veri kümesinin kendisine ek olarak veri sağlayıcısı tarafından önerilen akademik makaleleri tanımlar. Veri kümesinin kendisi için olan alıntıyı, "citation": "https://doi.org/10.1111/111" "citation": "https://identifiers.org/pubmed:11111111" "citation": "https://identifiers.org/arxiv:0111.1111v1" "citation": "Doe J (2014) Influence of X ... https://doi.org/10.1111/111" Ek yönergeler
|
funder
|
Person veya
Organization
Bu veri kümesi için maddi destek sağlayan bir kişi veya kuruluş. Kullanıcıları benzersiz bir şekilde tanımlamak için "funder": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0002", "givenName": "Jane", "familyName": "Funder", "name": "Jane Funder" }, { "@type": "Organization", "sameAs": "https://ror.org/yyyyyyyyy", "name": "Fictitious Funding Organization" } ] |
hasPart veya isPartOf
|
URL veya
Dataset
Veri kümesi daha küçük veri kümelerinden oluşan bir koleksiyonsa
bu ilişkiyi belirtmek için "hasPart" : [ { "@type": "Dataset", "name": "Sub dataset 01", "description": "Informative description of the first subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 01 creator" } }, { "@type": "Dataset", "name": "Sub dataset 02", "description": "Informative description of the second subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 02 creator" } } ] "isPartOf" : "https://example.com/aggregate_dataset" |
identifier
|
URL, Text veya PropertyValue
DOI veya Kompakt Tanımlayıcı gibi bir tanımlayıcı. Veri kümesinde birden fazla tanımlayıcı varsa |
isAccessibleForFree
|
Boolean
Veri kümesinin ücretsiz olarak erişilebilir olup olmadığı. |
keywords
|
Text
Veri kümesini özetleyen anahtar kelimeler. |
license
|
URL veya CreativeWorkVeri kümesinin dağıtımını belirleyen bir lisans. Örneğin: "license" : "https://creativecommons.org/publicdomain/zero/1.0/" "license" : { "@type": "CreativeWork", "name": "Custom license", "url": "https://example.com/custom_license" } Ek yönergeler
|
measurementTechnique
|
Text veya URL
|
sameAs
|
URL
Veri kümesinin kimliğini açık bir şekilde tanımlayan bir referans web sayfasının URL'si. |
spatialCoverage |
Text veya PlaceVeri kümesinin uzamsal yönünü açıklayan tek bir nokta sağlayabilirsiniz. Bu özelliği yalnızca veri kümesi uzamsal bir boyuta sahipse ekleyin. Örneğin, tüm ölçümlerin toplandığı tek bir nokta veya bir alan için sınırlayıcı kutunun koordinatları. Noktalar "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoCoordinates", "latitude": 39.3280, "longitude": 120.1633 } } Şekiller Farklı şekillerdeki alanları açıklamak için "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoShape", "box": "39.3280 120.1633 40.445 123.7878" } }
Adlandırılmış konumlar "spatialCoverage:" "Tahoe City, CA" |
temporalCoverage |
Text
Veri kümesindeki veriler belirli bir zaman aralığını kapsar. Bu özelliği yalnızca veri kümesi geçici bir boyuta sahipse ekleyin. Schema.org, zaman aralıklarını ve zaman noktalarını açıklamak için ISO 8601 standardını kullanır. Veri kümesi aralığına bağlı olarak tarihleri farklı biçimde tanımlayabilirsiniz. Açık uçlu aralıkları iki ondalık basamakla ( Tek tarih "temporalCoverage" : "2008" Dönem "temporalCoverage" : "1950-01-01/2013-12-18" Açık uçlu dönem "temporalCoverage" : "2013-12-19/.." |
variableMeasured
|
Text veya PropertyValueBu veri kümesinin ölçtüğü değişken. Örneğin, sıcaklık veya basınç. |
version
|
Text veya NumberVeri kümesinin sürüm numarası. |
url
|
URL
Veri kümesini açıklayan bir sayfanın konumu. |
DataCatalog
DataCatalog öğesinin tam tanımını schema.org/DataCatalog adresinde bulabilirsiniz.
Veri kümeleri genellikle başka birçok veri kümesi içeren veri havuzlarında yayınlanır. Aynı veri kümesi, böyle birden fazla veri havuzuna dahil edilebilir. Aşağıdaki özellikleri kullanıp doğrudan başvuruda bulunarak bu veri kümesinin ait olduğu veri kataloğuna referans verebilirsiniz.
| Önerilen özellikler | |
|---|---|
includedInDataCatalog
|
DataCatalog
Veri kümesinin ait olduğu katalog.
|
DataDownload
DataDownload öğesinin tam tanımını schema.org/DataDownload adresinde bulabilirsiniz. Dataset özelliklerine ek olarak, indirme seçenekleri sunan veri kümeleri için aşağıdaki özellikleri ekleyin.
URL genellikle veri kümesini tanımlayan açılış sayfasını işaret ettiğinden distribution özelliği, veri kümesinin kendisinin nasıl alınacağını açıklar. distribution özelliği, verilerin nereden alınacağını ve hangi biçimde olacağını açıklar. Bu özelliğin birkaç değeri olabilir: Örneğin, bir CSV sürümünün bir URL'si vardır ve bir Excel sürümü başka bir URL'de bulunmaktadır.
| Zorunlu özellikler | |
|---|---|
distribution.contentUrl
|
URL
İndirme bağlantısı. |
| Önerilen özellikler | |
|---|---|
distribution
|
DataDownload
Veri kümesi indirme dosyasının konumunun ve indirilecek dosya biçiminin açıklaması.
|
distribution.encodingFormat
|
Text veya URLDağıtımın dosya biçimi.
|
Tablo biçiminde veri kümeleri
Tablo biçiminde veri kümesi, öncelikle bir satır ve sütun ızgarası şeklinde düzenlenir. Tablo biçiminde veri kümelerini yerleştiren sayfalar için temel yaklaşıma dayanarak, daha belirgin bir işaretleme de oluşturabilirsiniz. Şu anda, HTML sayfasındaki kullanıcı odaklı tablo biçimli içeriğe paralel olarak sağlanan bir CSVW ("Web’deki CSV", bkz. W3C) çeşidini anlıyoruz.
Burada, CSVW JSON-LD biçiminde kodlanmış küçük bir tabloyu gösteren bir örneği görebilirsiniz. Zengin Sonuçlar Testi'nde bazı bilinen hatalar bulunmaktadır.
<html>
<head>
<title>American Humane Association</title>
<script type="application/ld+json">
{
"@context": ["https://schema.org", {"csvw": "https://www.w3.org/ns/csvw#"}],
"@type": "Dataset",
"name":"AMERICAN HUMANE ASSOCIATION",
"description": "ProPublica's Nonprofit Explorer lets you view summaries of 2.2 million tax returns from tax-exempt organizations and see financial details such as their executive compensation and revenue and expenses. You can browse raw IRS data released since 2013 and access over 9.4 million tax filing documents going back as far as 2001.",
"publisher": {
"@type": "Organization",
"name": "ProPublica"
},
"mainEntity" : {
"@type" : "csvw:Table",
"csvw:tableSchema": {
"csvw:columns": [
{
"csvw:name": "Year",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization name",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization address",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization NTEE Code",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Total functional expenses ($)",
"csvw:datatype": "integer",
"csvw:cells": [
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
}]
}]
}
}
}
</script>
</head>
<body>
</body>
</html>Search Console ile zengin sonuçları izleme
Search Console, sayfalarınızın Google Arama'daki performansını izlemenize yardımcı olan bir araçtır. Google Arama sonuçlarına dahil olmak için Search Console'a kaydolmanız gerekmez, ancak Google'ın sitenizi nasıl gördüğünü anlamanıza ve iyileştirmenize yardımcı olabilir. Aşağıdaki durumlarda Search Console'u kontrol etmenizi öneririz:
- Yapılandırılmış verileri ilk kez dağıttıktan sonra
- Yeni şablonlar yayınladıktan veya kodunuzu güncelledikten sonra
- Düzenli olarak trafiği analiz etmek için
Yapılandırılmış verileri ilk kez dağıttıktan sonra
Google sayfalarınızı dizine ekledikten sonra, ilgili Zengin sonuç durum raporunu kullanarak sorunları arayın. İdeal olan, geçerli öğelerin sayısı artarken geçersiz olanlarda artış olmamasıdır. Yapılandırılmış verilerinizde sorun bulursanız:
- Geçersiz öğeleri düzeltin.
- Sorunun devam edip etmediğini kontrol etmek için yayındaki URL'yi inceleyin.
- Durum raporunu kullanarak doğrulama isteğinde bulunun.
Yeni şablonlar yayınladıktan veya kodunuzu güncelledikten sonra
Web sitenizde önemli değişiklikler yaptığınızda yapılandırılmış verilerdeki geçersiz öğelerin sayısında artış olup olmadığını takip edin.- Geçersiz öğe sayısında artış görürseniz çalışmayan yeni bir şablonu kullanıma sunmuş olabilirsiniz veya siteniz mevcut şablonla yeni ve kötü bir şekilde etkileşime giriyor olabilir.
- Geçerli öğelerde azalma görürseniz (geçersiz öğelerdeki artışla eşleşmeyen), artık sayfalarınıza yapılandırılmış veri yerleştirmiyor olabilirsiniz. Soruna neyin neden olduğunu öğrenmek için URL Denetleme aracı'nı kullanın.
Düzenli olarak trafiği analiz etme
Performans Raporu'nu kullanarak Google Arama trafiğinizi analiz edin. Veriler, sayfanızın Arama'da ne sıklıkta zengin sonuç olarak göründüğünü, kullanıcıların bu zengin sonucu ne sıklıkta tıkladığını ve arama sonuçlarında göründüğünüz ortalama konumu gösterir. Bu sonuçlara Search Console API ile otomatik olarak da ulaşabilirsiniz.Sorun giderme
Yapılandırılmış verileri uygulamada veya hata ayıklamada sorun yaşıyorsanız size yardımcı olabilecek bazı kaynaklar aşağıda verilmiştir.
- İçerik yönetim sistemi (İYS) kullanıyorsanız veya sitenizle başka biri ilgileniyorsa bu kişiden size yardım etmesini isteyin. Sorunla ilgili ayrıntılı bilgiler içeren Search Console mesajlarını bu kişiye yönlendirdiğinizden emin olun.
- Google, yapılandırılmış veriler kullanan özelliklerin arama sonuçlarında görüneceğini garanti etmez. Google'ın içeriğinizi zengin sonuç içinde göstermemesinin yaygın nedenlerini içeren liste için Genel Yapılandırılmış Veri Yönergeleri'ni inceleyin.
- Yapılandırılmış verilerinizde bir hata olabilir. Yapılandırılmış veri hatalarının listesini ve Ayrıştırılamayan yapılandırılmış veri raporunu kontrol edin.
- Sayfanıza yönelik bir yapılandırılmış veri manuel işlemi varsa sayfadaki yapılandırılmış veriler dikkate alınmaz (sayfa Google Arama sonuçlarında görünmeye devam edebilir). Yapılandırılmış veri sorunlarını düzeltmek için Manuel İşlemler raporunu kullanın.
- İçeriğinizin kurallara uygun olup olmadığını belirlemek için yönergeleri tekrar inceleyin. Sorun, spam içeriği veya spam içerikli işaretleme kullanımından kaynaklanıyor olabilir. Bununla birlikte, sorunun söz diziminden kaynaklanmadığı durumlarda Zengin Sonuçlar Testi bu sorunları tanımlayamaz.
- Eksik zengin sonuçlar/toplam zengin sonuç sayısında düşüş sorununu giderin.
- Yeniden tarama ve yeniden dizine ekleme için zaman tanıyın. Google’ın yayınlandıktan sonra bir sayfayı bulmasının ve taramasının birkaç gün sürebileceğini unutmayın. Tarama ve dizine ekleme hakkında genel sorular için Google Arama tarama ve dizine ekleme için SSS bölümüne bakın.
- Google Arama Merkezi forumunda soru yayınlayın.
Belirli veri kümesi, Veri Kümesi Arama sonuçlarında görünmüyor
error Sorunun nedeni: Sitenizde veri kümelerini açıklayan sayfada yapılandırılmış veriler yoktur veya sayfa henüz taranmamıştır.
done Sorunu düzeltme
- Veri Seti Arama sonuçlarında görmeyi beklediğiniz sayfanın bağlantısını kopyalayıp Zengin Sonuçlar Testi'ne yapıştırın. "Sayfa bu test tarafından bilinen zengin sonuçlar için uygun değil" veya "Tüm işaretleme zengin sonuçlar için uygun değil" mesajı görüntüleniyorsa bu, sayfada veri kümesi işaretlemesi bulunmadığı veya işaretlemenin hatalı olduğu anlamına gelir. Bu sorunu, Yapılandırılmış veri ekleme bölümüne bakarak düzeltebilirsiniz.
- Sayfada işaretleme varsa henüz taranmamış olabilir. Search Console ile tarama durumunu kontrol edebilirsiniz.
Sonuçlara göre şirket logosu eksik veya doğru görünmüyor
error Sorunun nedeni: Sayfanızda kuruluş logoları için schema.org işaretlemesi eksik olabilir veya işletmeniz Google ile oluşturulmamış olabilir.
done Sorunu düzeltme
- Sayfanıza yapılandırılmış logo verileri ekleyin.
- İşletme bilgilerinizi Google ile oluşturun.