Dados estruturados de conjunto de dados (Dataset, DataCatalog, DataDownload)
É mais fácil encontrar conjuntos de dados na ferramenta Pesquisa de Datasets quando são fornecidas informações de suporte, como nome, descrição, criador e formatos de distribuição, como dados estruturados. A abordagem do Google para a descoberta de conjuntos de dados usa o schema.org e outros padrões de metadados que podem ser adicionados a páginas com descrições dos conjuntos de dados. O objetivo dessa marcação é melhorar a descoberta de conjuntos de dados de campos como ciências biológicas, ciências sociais, aprendizado de máquina, dados cívicos e governamentais, entre outros.
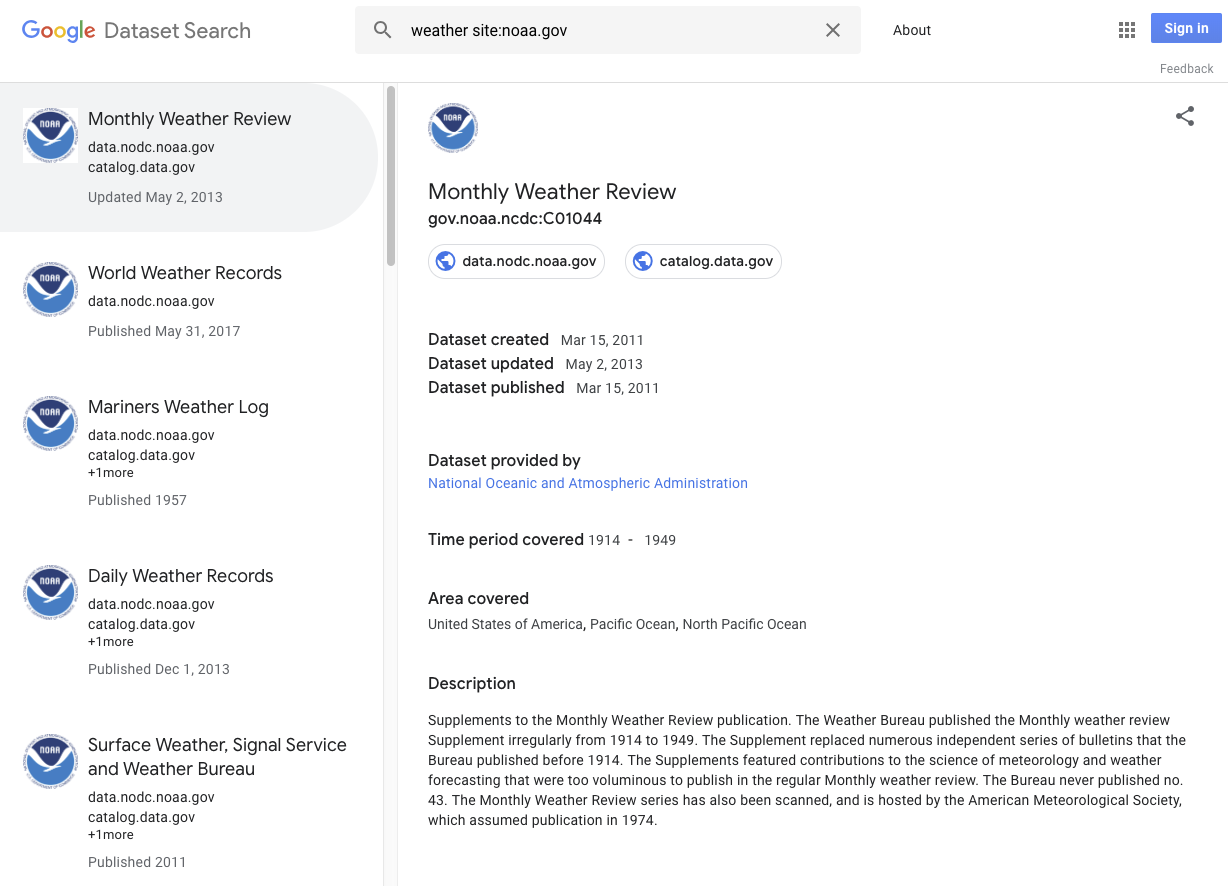
Veja alguns exemplos do que pode se qualificar como um conjunto de dados:
- Uma tabela ou um arquivo CSV com alguns dados
- Um conjunto organizado de tabelas
- Um arquivo em formato específico que contenha dados
- Uma coleção de arquivos que unidos formam um conjunto de dados significativo
- Um objeto estruturado com dados em algum outro formato que você queira carregar em uma ferramenta especial para processamento
- Imagens que capturam dados
- Arquivos relacionados ao aprendizado de máquina, como parâmetros treinados ou definições de estrutura de rede neural
Como adicionar dados estruturados
Os dados estruturados são um formato padronizado para fornecer informações sobre uma página e classificar o conteúdo dela. Caso você não saiba muito sobre o assunto, veja como os dados estruturados funcionam.
Esta é uma visão geral de como criar, testar e lançar dados estruturados.
- Adicione as propriedades obrigatórias. Com base no formato que você está usando, saiba onde inserir dados estruturados na página.
- Siga as diretrizes.
- Valide o código com o Teste de pesquisa aprimorada e corrija os erros críticos. Corrija também os problemas não críticos que possam ser sinalizados na ferramenta, porque eles podem melhorar a qualidade dos dados estruturados, mas isso não é necessário para se qualificar para pesquisas aprimoradas.
- Implante algumas páginas que incluam os dados estruturados e use a Ferramenta de inspeção de URL para testar como o Google vê a página. Verifique se a página está
acessível ao Google e se não está bloqueada por um arquivo robots.txt, pela tag
noindexou por requisitos de login. Se estiver tudo certo, peça ao Google para rastrear novamente seus URLs. - Para informar o Google sobre mudanças futuras, recomendamos que você envie um sitemap. É possível automatizar isso com a API Search Console Sitemap.
Como excluir um conjunto de dados dos resultados da Pesquisa de Datasets
Se você não quiser que um conjunto de dados apareça nos resultados da Pesquisa de Datasets, use a tag robots meta para controlar como ele é indexado. Talvez leve algum tempo (dias ou semanas, dependendo da programação de rastreamento) para que as mudanças entrem em vigor na Pesquisa de Datasets.
Nossa abordagem para a descoberta de conjuntos de dados
Podemos processar dados estruturados em páginas da Web sobre conjuntos de dados com a marcação Dataset do schema.org ou com estruturas equivalentes representadas no formato de vocabulário do catálogo de dados (DCAT, na sigla em inglês) do W3C (páginas em inglês). Também estamos testando
um suporte experimental para dados estruturados com base no CSVW do W3C. Esperamos aprimorar e adaptar nossa abordagem à medida que surjam práticas recomendadas para a descrição de conjuntos de dados. Para ver mais informações sobre nossa abordagem
para a descoberta de conjunto de dados, consulte
Como facilitar a descoberta de conjuntos de dados (em inglês).
Exemplos
Veja um exemplo de conjuntos de dados que usam a sintaxe JSON-LD e schema.org (preferencial) no teste de pesquisa aprimorada. O mesmo vocabulário do schema.org também pode ser usado nas sintaxes RDFa 1.1 ou microdados. Também é possível usar o vocabulário W3C DCAT para descrever os metadados. O exemplo a seguir se baseia em uma descrição real de conjunto de dados .
Veja um exemplo de conjunto de dados em JSON-LD:
<html>
<head>
<title>NCDC Storm Events Database</title>
<script type="application/ld+json">
{
"@context":"https://schema.org/",
"@type":"Dataset",
"name":"NCDC Storm Events Database",
"description":"Storm Data is provided by the National Weather Service (NWS) and contain statistics on...",
"url":"https://catalog.data.gov/dataset/ncdc-storm-events-database",
"sameAs":"https://gis.ncdc.noaa.gov/geoportal/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510",
"identifier": ["https://doi.org/10.1000/182",
"https://identifiers.org/ark:/12345/fk1234"],
"keywords":[
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > CYCLONES",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > DROUGHT",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FOG",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FREEZE"
],
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"isAccessibleForFree" : true,
"hasPart" : [
{
"@type": "Dataset",
"name": "Sub dataset 01",
"description": "Informative description of the first subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 01 creator"
}
},
{
"@type": "Dataset",
"name": "Sub dataset 02",
"description": "Informative description of the second subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 02 creator"
}
}
],
"creator":{
"@type":"Organization",
"url": "https://www.ncei.noaa.gov/",
"name":"OC/NOAA/NESDIS/NCEI > National Centers for Environmental Information, NESDIS, NOAA, U.S. Department of Commerce",
"contactPoint":{
"@type":"ContactPoint",
"contactType": "customer service",
"telephone":"+1-828-271-4800",
"email":"ncei.orders@noaa.gov"
}
},
"funder":{
"@type": "Organization",
"sameAs": "https://ror.org/00tgqzw13",
"name": "National Weather Service"
},
"includedInDataCatalog":{
"@type":"DataCatalog",
"name":"data.gov"
},
"distribution":[
{
"@type":"DataDownload",
"encodingFormat":"CSV",
"contentUrl":"https://www.ncdc.noaa.gov/stormevents/ftp.jsp"
},
{
"@type":"DataDownload",
"encodingFormat":"XML",
"contentUrl":"https://gis.ncdc.noaa.gov/all-records/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510"
}
],
"temporalCoverage":"1950-01-01/2013-12-18",
"spatialCoverage":{
"@type":"Place",
"geo":{
"@type":"GeoShape",
"box":"18.0 -65.0 72.0 172.0"
}
}
}
</script>
</head>
<body>
</body>
</html>Confira um exemplo de conjunto de dados em RDFa que usa o vocabulário DCAT (não compatível com o Teste de pesquisa aprimorada):
<article about="/node/1234" typeof="dcat:Dataset">
<dl>
<dt>Name:</dt>
<dd property="dc:title">ACME Inc Cash flow data</dd>
<dt>Identifiers:</dt>
<dd property="dc:identifier">https://doi.org/10.1000/182</dd>
<dd property="dc:identifier">https://identifiers.org/ark:/12345/fk1234</dd>
<dt>Description:</dt>
<dd property="dc:description">Financial Statements - Consolidated Statement of Cash Flows</dd>
<dt>Category:</dt>
<dd rel="dc:subject">Financial</dd>
<dt class="field-label">Downloads:</dt>
<dd>
<ul>
<li>
<a rel="dcat:distribution" href="Consolidated_Statement_of_Cash_Flows_en.csv"><span property="dcat:mediaType" content="text/csv" >Consolidated_Statement_of_Cash_Flows_en.csv</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/Consolidated_Statement_of_Cash_Flows_en.xls"><span property="dcat:mediaType" content="application/vnd.ms-excel">Consolidated_Statement_of_Cash_Flows_en.xls</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/consolidated_statement_of_cash_flows_en.xml"><span property="dcat:mediaType" content="application/xml">consolidated_statement_of_cash_flows_en.xml</span></a>
</li>
</ul>
</dd>
</dl>
</article>Diretrizes
Os sites precisam seguir as diretrizes de dados estruturados. Além dessas diretrizes, indicamos as práticas recomendadas de sitemap e origem e procedência abaixo.
Práticas recomendadas de sitemap
Use um arquivo do sitemap para ajudar
o Google a encontrar seus URLs. O uso de arquivos do sitemap e da marcação sameAs ajuda a documentar o modo como
as descrições dos conjuntos de dados são publicadas em todo o site.
Se você tem um repositório de conjunto de dados, provavelmente mantém pelo menos dois tipos de páginas: as canônicas
("de destino") para cada conjunto e as que listam vários conjuntos (por exemplo, resultados
da pesquisa ou algum subconjunto desses conjuntos). Recomendamos que você adicione dados estruturados sobre um conjunto de dados às
páginas canônicas. Use a propriedade sameAs para vincular à página canônica se você adicionar dados estruturados a várias cópias do conjunto, como informações de produtos em páginas de resultados da pesquisa.
Práticas recomendadas de origem e procedência
É comum que conjuntos de dados abertos sejam republicados, agregados e baseados em outros conjuntos de dados. Este texto é um esboço inicial da nossa abordagem para representar situações em que um conjunto de dados é uma cópia ou se baseia em outro conjunto de dados.
- Use a propriedade
sameAspara indicar os URLs mais canônicos do original nos casos em que o conjunto de dados ou a descrição for uma simples republicação de materiais publicados em outro lugar. O valor desameAsprecisa indicar inequivocamente a identidade do conjunto de dados. Ou seja, não use o mesmo valor desameAspara dois conjuntos de dados diferentes. - Use a propriedade
isBasedOnquando o conjunto de dados republicado (incluindo os metadados) tiver sido alterado significativamente. - Quando um conjunto de dados derivar de vários originais ou os agregar, use a propriedade
isBasedOn. - Use a propriedade
identifierpara anexar qualquer Identificador de objeto digital (DOI, na sigla em inglês) ou identificador compacto relevante. Se o conjunto de dados tiver mais de um identificador, repita a propriedadeidentifier. Ao usar JSON-LD, isso será representado usando a sintaxe de lista JSON.
Esperamos melhorar nossas recomendações com base no feedback recebido, especialmente a respeito da descrição de procedência, controle de versão e datas associadas à publicação de séries temporais. Participe das discussões da comunidade.
Recomendações de propriedade textual
Recomendamos limitar todas as propriedades textuais a, no máximo, 5.000 caracteres. O Google Pesquisa de Datasets só usa os primeiros 5.000 caracteres da propriedade de texto. Normalmente, são usadas poucas palavras ou uma frase curta para nomes e títulos.
Erros conhecidos e avisos
É possível que você encontre erros ou avisos no teste de pesquisa aprimorada do Google e em outros sistemas de validação. Talvez esses sistemas também sugiram que as organizações precisam ter dados de contato, incluindo um contactType. Os valores úteis incluem customer service, emergency, journalist, newsroom e public engagement.
Você também pode ignorar erros de que csvw:Table é um valor inesperado para a propriedade mainEntity.
Definições de tipos de dados estruturados
É necessário incluir as propriedades obrigatórias para que seu conteúdo esteja qualificado para exibição em uma pesquisa aprimorada. Você também pode incluir as propriedades recomendadas para adicionar mais informações sobre o conteúdo, o que pode proporcionar uma melhor experiência do usuário.
É possível usar o teste de pesquisa aprimorada para validar sua marcação.
O foco está em descrever informações sobre um conjunto de dados (os metadados dele) e representar o conteúdo desse conjunto. Por exemplo, os metadados do conjunto de dados informam do que se trata esse conjunto, quais variáveis ele mede, quem o criou e assim por diante. Eles não contêm, por exemplo, valores específicos para as variáveis.
Dataset
A definição completa de Dataset está disponível em
schema.org/Dataset (em inglês).
É possível descrever mais informações sobre a publicação do conjunto de dados, como a
licença, a data em que foi publicado, o
Identificador de objeto digital (DOI, na sigla em inglês)
ou um sameAs apontando para uma versão canônica do conjunto de dados em um repositório
diferente. Adicione identifier, license e sameAs para
conjuntos de dados que forneçam informações de procedência e licença.
Veja as propriedades aceitas pelo Google:
| Propriedades obrigatórias | |
|---|---|
description
|
Text
É um breve resumo que descreve um conjunto de dados. Diretrizes
|
name
|
Text
É um nome descritivo de um conjunto de dados. Por exemplo, "Profundidade da neve no Hemisfério Norte". Diretrizes
Recomendado: Não recomendado: |
| Propriedades recomendadas | |
|---|---|
alternateName
|
Text
São nomes alternativos que foram usados para se referir ao conjunto de dados, como aliases ou abreviações. Exemplo (no formato JSON-LD): "name": "The Quick, Draw! Dataset" "alternateName": ["Quick Draw Dataset", "quickdraw-dataset"] |
creator
|
Person ou
Organization
É o criador ou autor deste conjunto de dados. Para identificar exclusivamente os indivíduos, use o
ID ORCID (em inglês) como o valor da propriedade "creator": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0000", "givenName": "Jane", "familyName": "Foo", "name": "Jane Foo" }, { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0001", "givenName": "Jo", "familyName": "Bar", "name": "Jo Bar" }, { "@type": "Organization", "sameAs": "https://ror.org/xxxxxxxxx", "name": "Fictitious Research Consortium" } ] |
citation
|
Text ou CreativeWork
Identifica os artigos acadêmicos que são recomendados pelo provedor de dados citado, além do conjunto de dados em si. Forneça a citação do próprio conjunto de dados com outras propriedades, como "citation": "https://doi.org/10.1111/111" "citation": "https://identifiers.org/pubmed:11111111" "citation": "https://identifiers.org/arxiv:0111.1111v1" "citation": "Doe J (2014) Influence of X ... https://doi.org/10.1111/111" Diretrizes adicionais
|
funder
|
Person ou
Organization
É uma pessoa ou organização que fornece apoio financeiro para esse conjunto de dados. Para identificar exclusivamente os indivíduos, use o
ID ORCID (em inglês) como o valor da propriedade "funder": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0002", "givenName": "Jane", "familyName": "Funder", "name": "Jane Funder" }, { "@type": "Organization", "sameAs": "https://ror.org/yyyyyyyyy", "name": "Fictitious Funding Organization" } ] |
hasPart ou isPartOf
|
URL ou
Dataset
Se o conjunto de dados for uma série de conjuntos menores, use a propriedade "hasPart" : [ { "@type": "Dataset", "name": "Sub dataset 01", "description": "Informative description of the first subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 01 creator" } }, { "@type": "Dataset", "name": "Sub dataset 02", "description": "Informative description of the second subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 02 creator" } } ] "isPartOf" : "https://example.com/aggregate_dataset" |
identifier
|
URL, Text ou PropertyValue
É um identificador, como um DOI ou um identificador compacto. Se o conjunto de dados tiver mais de um
identificador, repita a propriedade |
isAccessibleForFree
|
Boolean
Indica se o conjunto de dados pode ser acessado sem pagamento. |
keywords
|
Text
São palavras-chave que resumem o conjunto de dados. |
license
|
URL ou CreativeWork
É uma licença usada para distribuição do conjunto de dados. Exemplo: "license" : "https://creativecommons.org/publicdomain/zero/1.0/" "license" : { "@type": "CreativeWork", "name": "Custom license", "url": "https://example.com/custom_license" } Diretrizes adicionais
|
measurementTechnique
|
Text ou URL
É a técnica, tecnologia ou metodologia usada em um conjunto de dados, que pode corresponder às variáveis descritas em |
sameAs
|
URL
É o URL de uma página da Web de referência que indica claramente a identidade do conjunto de dados. |
spatialCoverage |
Text ou Place
Você pode fornecer um único ponto que descreva o aspecto espacial do conjunto de dados. Só inclua essa propriedade se o conjunto de dados tiver uma dimensão espacial. Por exemplo, um único ponto em que todas as medidas foram coletadas, ou as coordenadas de uma caixa delimitadora para uma área. Pontos "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoCoordinates", "latitude": 39.3280, "longitude": 120.1633 } } Formas Use "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoShape", "box": "39.3280 120.1633 40.445 123.7878" } } Pontos nas propriedades Locais nomeados "spatialCoverage:" "Tahoe City, CA" |
temporalCoverage |
Text
São os dados do conjunto que abrangem um intervalo de tempo específico. Só inclua essa propriedade se o
conjunto de dados tiver uma dimensão temporal. O schema.org usa o padrão ISO 8601
para descrever intervalos e pontos de tempo. Você pode descrever datas de forma diferente, dependendo
do intervalo do conjunto de dados. Indique intervalos abertos com dois pontos decimais ( Data única "temporalCoverage" : "2008" Período "temporalCoverage" : "1950-01-01/2013-12-18" Período aberto "temporalCoverage" : "2013-12-19/.." |
variableMeasured
|
Text ou PropertyValue
É a variável que o conjunto de dados mede. Por exemplo, temperatura ou pressão. |
version
|
Text ou Number
É o número da versão do conjunto de dados. |
url
|
URL
Localização de uma página que descreve o conjunto de dados. |
DataCatalog
A definição completa de DataCatalog está disponível em
schema.org/DataCatalog (em inglês).
Os conjuntos de dados são frequentemente publicados em repositórios que contêm muitos outros conjuntos de dados. O mesmo conjunto de dados pode ser incluído em mais de um desses repositórios. Para indicar o catálogo de dados a que esse conjunto de dados pertence, faça referência a ele usando as seguintes propriedades:
| Propriedades recomendadas | |
|---|---|
includedInDataCatalog
|
DataCatalog
É o catálogo a que o conjunto de dados pertence.
|
DataDownload
A definição completa de DataDownload está disponível em
schema.org/DataDownload (em inglês). Além das propriedades do conjunto de dados,
adicione as propriedades a seguir para conjuntos que forneçam opções de download.
A propriedade distribution descreve como conseguir o conjunto de dados em si, considerando que o URL
geralmente aponta para a página de destino que descreve esse conjunto. A propriedade distribution
descreve onde conseguir os dados e em que formato. Essa propriedade pode
ter vários valores: por exemplo, uma versão em CSV tem um URL, e uma versão em Excel
está disponível em outro.
| Propriedades obrigatórias | |
|---|---|
distribution.contentUrl
|
URL
É o link para o download. |
| Propriedades recomendadas | |
|---|---|
distribution
|
DataDownload
É a descrição do local para o download do conjunto de dados e o formato de arquivo para o download.
|
distribution.encodingFormat
|
Text ou URL
É o formato de arquivo da distribuição.
|
Conjuntos de dados tabulares
Um conjunto de dados tabular é organizado principalmente em termos de uma grade de linhas e colunas. Para páginas que incorporam conjuntos de dados tabulares, você também pode criar uma marcação mais explícita, com base na abordagem básica. No momento, processamos uma variação do CSVW ("CSV na Web", consulte W3C), fornecida em paralelo ao conteúdo tabular orientado ao usuário na página HTML.
Veja um exemplo que mostra uma pequena tabela codificada no formato CSVW JSON-LD. Há alguns erros conhecidos no teste de pesquisa aprimorada.
<html>
<head>
<title>American Humane Association</title>
<script type="application/ld+json">
{
"@context": ["https://schema.org", {"csvw": "https://www.w3.org/ns/csvw#"}],
"@type": "Dataset",
"name":"AMERICAN HUMANE ASSOCIATION",
"description": "ProPublica's Nonprofit Explorer lets you view summaries of 2.2 million tax returns from tax-exempt organizations and see financial details such as their executive compensation and revenue and expenses. You can browse raw IRS data released since 2013 and access over 9.4 million tax filing documents going back as far as 2001.",
"publisher": {
"@type": "Organization",
"name": "ProPublica"
},
"mainEntity" : {
"@type" : "csvw:Table",
"csvw:tableSchema": {
"csvw:columns": [
{
"csvw:name": "Year",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization name",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization address",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization NTEE Code",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Total functional expenses ($)",
"csvw:datatype": "integer",
"csvw:cells": [
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
}]
}]
}
}
}
</script>
</head>
<body>
</body>
</html>Monitorar pesquisas aprimoradas com o Search Console
O Search Console é uma ferramenta que ajuda você a monitorar o desempenho das suas páginas na Pesquisa Google. Não é preciso se inscrever na plataforma para ser incluído nos resultados da Pesquisa Google, mas isso pode ajudar você a entender e melhorar como vemos seu site. Recomendamos verificar o Search Console nos seguintes casos:
- Depois de implantar os dados estruturados pela primeira vez
- Depois de lançar novos modelos ou atualizar o código
- Análise periódica do tráfego
Depois de implantar os dados estruturados pela primeira vez
Depois que o Google indexar as páginas, procure problemas com o relatório de status da pesquisa aprimorada relevante. Em condições ideais, vai haver um aumento de itens válidos e nenhum aumento de itens inválidos. Se você encontrar problemas nos dados estruturados, faça o seguinte:
- Corrija os itens inválidos.
- Inspecione um URL ativo para verificar se o problema persiste.
- Solicite a validação com o relatório de status.
Depois de lançar novos modelos ou atualizar o código
Ao fazer mudanças significativas no site, monitore aumentos nos itens inválidos de dados estruturados.- Caso você perceba um aumento nos itens inválidos, talvez tenha lançado um novo modelo que não funcione ou o site esteja interagindo com o modelo existente de uma maneira nova e incorreta.
- Caso você veja uma diminuição nos itens válidos (não correspondidos por um aumento nos itens inválidos), talvez não esteja mais incorporando os dados estruturados às páginas. Use a Ferramenta de inspeção de URL para saber o que está causando o problema.
Análise periódica do tráfego
Analise o tráfego da Pesquisa Google com o Relatório de desempenho. Os dados vão mostrar com que frequência sua página aparece como aprimorada na Pesquisa, com que frequência os usuários clicam nela e qual é a posição média dela nos resultados. Também é possível extrair automaticamente esses resultados com a API Search Console.Solução de problemas
Se você tiver problemas para implementar ou depurar dados estruturados, veja alguns recursos que podem ajudar.
- Se você usa um sistema de gerenciamento de conteúdo (CMS) ou se alguém está cuidando do seu site, peça ajuda para o prestador de serviço. Não se esqueça de encaminhar todas as mensagens do Search Console com os detalhes do problema.
- O Google não garante que os recursos que consomem dados estruturados vão ser exibidos nos resultados da pesquisa. Para ver uma lista de motivos comuns por que o Google pode não exibir seu conteúdo na pesquisa aprimorada, consulte as diretrizes gerais de dados estruturados.
- Pode haver um erro nos dados estruturados. Confira a lista de erros de dados estruturados e o Relatório de dados estruturados que não podem ser analisados.
- Se você recebeu uma ação manual de dados estruturados relacionada à sua página, esses dados serão ignorados, embora a página ainda possa aparecer nos resultados da Pesquisa Google. Para corrigir problemas de dados estruturados, use o Relatório de ações manuais.
- Consulte as diretrizes novamente para identificar se o conteúdo não está em conformidade com elas. O problema pode ser causado por conteúdo com spam ou uso de marcação com spam. No entanto, talvez o problema não seja de sintaxe e, por isso, o teste de pesquisa aprimorada não poderá identificá-lo.
- Resolva problemas relacionados à ausência e à queda no total de pesquisas aprimoradas.
- Aguarde algum tempo antes de voltar a rastrear e reindexar. Pode levar vários dias depois da publicação de uma página para que o Google a localize e rastreie. Para perguntas gerais sobre rastreamento e indexação, consulte as Perguntas frequentes sobre rastreamento e indexação da Pesquisa Google.
- Poste uma pergunta no fórum da Central da Pesquisa Google
O conjunto de dados específico não está aparecendo nos resultados da Pesquisa de Datasets
error O que causou o problema: o site não tem dados estruturados na página que descreve os conjuntos de dados, ou a página ainda não foi rastreada.
done Corrigir o problema
- Copie o link da página que você quer ver nos resultados da Pesquisa de Datasets e coloque-o no teste de pesquisa aprimorada. Se a mensagem "A página não está qualificada para os rich results conhecidos por este teste" ou "Nem todas as marcações estão qualificadas para rich results" for exibida, isso significa que não há marcação de conjunto de dados na página ou está incorreta. Se você quiser corrigir esse problema, consulte a seção Como adicionar dados estruturados.
- Se houver marcação na página, talvez ela ainda não tenha sido rastreada. Verifique o status de rastreamento com o Search Console.
O logotipo da empresa não aparece ou não é exibido corretamente pelos resultados
error O que causou o problema: talvez a página não tenha a marcação do schema.org para logotipos de organizações, ou a empresa não esteja registrada no Google.
done Corrigir o problema
- Adicione dados estruturados de logotipo à página.
- Estabeleça os detalhes da empresa com o Google.