回避策としてのダイナミック レンダリング
一部のウェブサイトでは、JavaScript がブラウザで実行されたときに、ページ上に新たなコンテンツが生成されます。これをクライアントサイド レンダリングと呼びます。Google 検索は、このコンテンツをウェブサイトの HTML 内のコンテンツとともに認識します。Google 検索が対応していない JavaScript の機能もあります。そのため、ページによっては、レンダリングされた HTML にコンテンツが表示されないという問題が発生することがあります。他の検索エンジンでは JavaScript を無視し、JavaScript によって生成されたコンテンツが表示されない場合があります。
ダイナミック レンダリングは、検索エンジンが JavaScript 生成コンテンツに対応していない場合のウェブサイトでの回避策です。ダイナミック レンダリング サーバーは、JavaScript 生成コンテンツに関して問題がある可能性のある bot を検知し、検知した bot にはサーバーでレンダリングした JavaScript なしのバージョンのコンテンツを提供する一方で、ユーザーに対してはクライアントサイドでレンダリングされたバージョンのコンテンツを表示します。
ただし、ダイナミック レンダリングは回避策です。仕組みがより複雑になり、多くのリソースが必要になるため、推奨される解決策ではありません。
ダイナミック レンダリングを使用する可能性があるサイト
ダイナミック レンダリングは、JavaScript で生成される、変更頻度の高いインデックス登録可能な一般公開コンテンツや、クローラーではサポートされていない JavaScript の機能を使用する、サイト運営者にとって重要なコンテンツのための回避策です。すべてのサイトでダイナミック レンダリングを使用する必要はありません。ウェブでのレンダリングに関する概要で説明されているように、ダイナミック レンダリングよりも優れたソリューションがあります。
ダイナミック レンダリングの仕組みについて
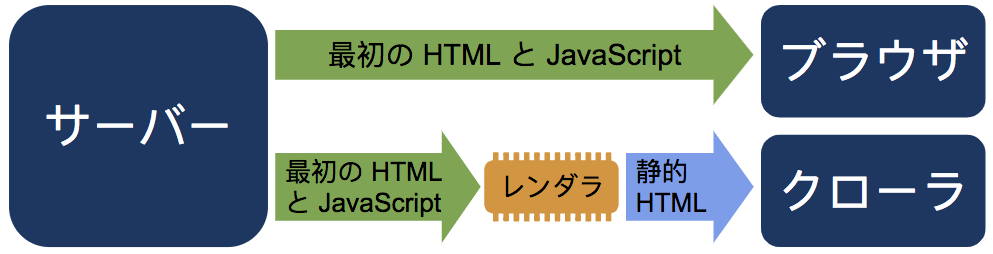
ダイナミック レンダリングでは、ユーザー エージェントを確認するなどの方法によって、ウェブサーバーがクローラーを検出する必要があります。ウェブサーバーが、JavaScript をサポートしていないクローラーや、コンテンツのレンダリングに必要な JavaScript の機能をサポートしていないクローラーからのリクエストを認識すると、そのリクエストはレンダリング サーバーにルーティングされます。JavaScript の問題がないユーザーやクローラーからのリクエストは、通常どおり処理されます。レンダリング サーバーは、クローラーに適したバージョンのコンテンツでリクエストに応答します。たとえば、静的 HTML バージョンを配信する場合もあります。ダイナミック レンダラは、すべてのページで有効にすることも、ページ単位で有効にすることもできます。
ダイナミック レンダリングはクローキングではない
Googlebot は通常、ダイナミック レンダリングをクローキングとは見なしません。ダイナミック レンダリングで同様のコンテンツを生成する限り、Googlebot はダイナミック レンダリングをクローキングとは見なしません。
ダイナミック レンダリングを設定していると、サイトでエラーページが生成される場合があります。Googlebot はこのようなエラーページをクローキングとは見なさず、他のエラーページと同様に扱います。
ただし、ダイナミック レンダリングを使用してユーザーとクローラーにまったく異なるコンテンツを提供すると、クローキングと見なされる場合があります。たとえば、ユーザーには猫に関するページが提供され、クローラーには犬に関するページが提供されるウェブサイトは、クローキングと見なされます。