فهم أساسيات تحسين محرّكات البحث المستندة إلى JavaScript
لغة JavaScript هي جزء مهم من منصة الويب لأنّها توفّر العديد من الميزات التي تجعل الويب منصة فعّالة للتطبيقات. وإذا أتحت اكتشاف تطبيقات الويب المستندة إلى JavaScript من خلال "بحث Google"، يمكنك العثور على مستخدمين جدد وإعادة جذب المستخدمين الحاليين أثناء بحثهم عن المحتوى الذي يوفره تطبيق الويب الخاص بك. على الرغم من أنّ محرّك بحث Google يشغِّل JavaScript باستخدام أحد إصدارات Chromium المحدّثة باستمرار، هناك بعض الجوانب التي يمكنك تحسينها.
يشرح هذا الدليل طريقة محرّك بحث Google في معالجة لغة JavaScript، ويوضّح أفضل الممارسات لتحسين تطبيقات الويب المستندة إلى JavaScript كي تتوافق مع "بحث Google".
طريقة محرّك بحث Google في معالجة لغة JavaScript
يعالج محرّك بحث Google تطبيقات الويب المستندة إلى JavaScript في ثلاث مراحل رئيسية:
- الزحف
- العرض
- الفهرسة
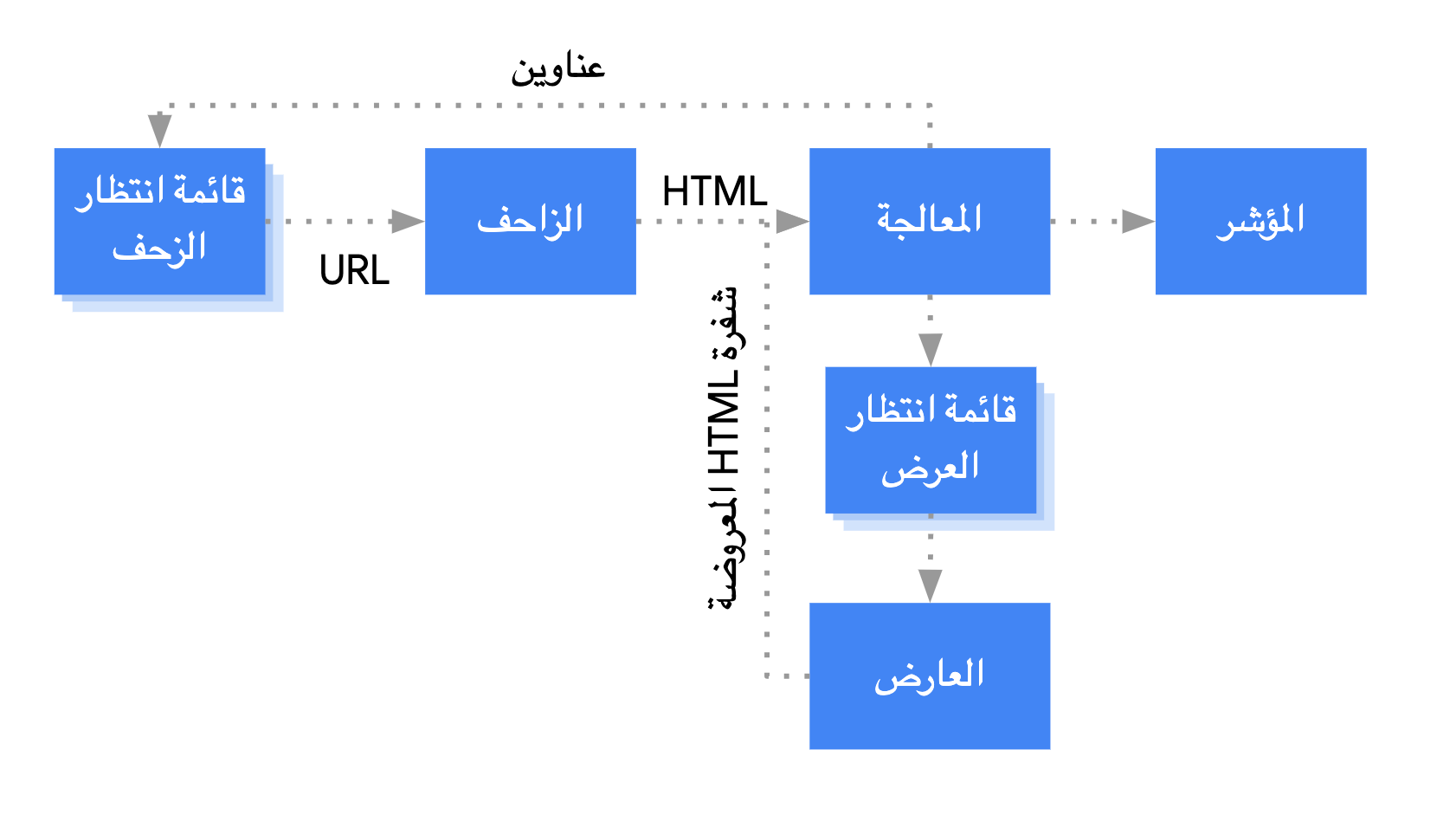
يضع Googlebot الصفحات ضمن قائمة انتظار لكلٍّ من الزحف والعرض. ولا يظهر على الفور ما إذا كانت الصفحة بانتظار الزحف إليها أو عرضها. عندما يجلب Googlebot عنوان URL من قائمة انتظار الزحف عن طريق تقديم طلب HTTP، يتأكّد أولاً مما إذا كان الزحف مسموحًا به. يقرأ Googlebot ملف robots.txt. وفي حال وضع الملف علامة على عنوان URL تفيد بأنّه غير مسموح بالزحف إليه، لا يقدم Googlebot طلب HTTP إلى هذا العنوان ويتخطّاه. ولا يعرض محرّك بحث Google لغة JavaScript من الملفات المحظورة أو في الصفحات المحظورة.
بعد ذلك، يحلّل Googlebot الاستجابة الواردة من عناوين URL الأخرى في السمة href لروابط HTML ويضيف عناوين URL إلى قائمة انتظار الزحف. يمكنك استخدام آلية nofollow لمنع رصد الروابط.
في المواقع الإلكترونية الكلاسيكية والصفحات التي تُعرض من جهة الخادم، يمكن الزحف إلى عنوان URL وتحليل استجابة HTML لأنّ رموز HTML في استجابة HTTP تتضمّن كل المحتوى. قد تستخدم بعض المواقع الإلكترونية المستندة إلى JavaScript نموذج هيكل التطبيق الذي لا تشتمل رموز HTML الأولية فيه على المحتوى الفعلي، ويحتاج محرّك بحث Google إلى تنفيذ JavaScript حتى يتمكّن من رؤية محتوى الصفحة الفعلي الذي تنشئه لغة JavaScript.
ينظّم Googlebot جميع الصفحات في قائمة انتظار لعرضها، إلا إذا طلب عنوان أو علامة meta لبرامج robots من Google عدم فهرسة صفحة معيّنة.
تبقى الصفحة في قائمة الانتظار هذه لبضع ثوانٍ، لكن قد تستغرق وقتًا أطول من ذلك. بعد أن تسمح موارد Google بالعرض، يعرض Chromium الذي لا يتضمّن واجهة مستخدم رسومية الصفحة وينفّذ JavaScript.
يحلّل Googlebot محتوى HTML المعروض بحثًا عن الروابط مرةً أخرى ويضيف عناوين URL التي يعثر عليها إلى قائمة انتظار الزحف. يستخدم محرّك بحث Google أيضًا محتوى HTML المعروض لفهرسة الصفحة.
يُرجى العِلم أنّ العرض على جهة الخادم أو العرض المسبق هما من الطرق الفعّالة، لأنّهما يجعلان موقعك الإلكتروني أسرع بالنسبة إلى المستخدمين وبرامج الزحف، كما يسمحان بتنفيذ لغة JavaScript إذا لم تتمكّن برامج التتبُّع من ذلك.
إضافة وصف إلى صفحتك باستخدام العناوين والمقتطفات الفريدة
تساعد عناصر <title> الوصفية الفريدة والأوصاف التعريفية المستخدمين على أن يحدّدوا بسرعة أفضل نتيجة تحقّق هدفهم.
يمكنك استخدام JavaScript لتحديد الوصف التعريفي وعنصر <title> أو تغييرهما.
كتابة رمز متوافق
توفر المتصفّحات العديد من واجهات برمجة التطبيقات ويواكب ذلك تطورًا سريعًا في لغة JavaScript. هناك بعض القيود المفروضة على محرّك بحث Google في ما يتعلق بواجهات برمجة التطبيقات وميزات JavaScript المتوافقة معه. ولضمان توافق رمزك البرمجي مع Google، اتّبِع إرشاداتنا الخاصة بتحديد مشاكل JavaScript وحلّها.
نقترح عليك استخدام العرض التفاضلي ورموز polyfill التفاضلية إذا اكتشفت من خلال الميزات أنّ هناك واجهة برمجة تطبيقات خاصة بالمتصفّح تحتاجها وهي غير متوفّرة. وبما أنه لا يمكن إضافة رموز polyfill إلى بعض ميزات المتصفّح، ننصحك بالاطّلاع على وثائق رموز polyfill لمعرفة القيود المحتمَلة.
استخدام رموز حالة HTTP المفيدة
يستخدم Googlebot رموز حالة HTTP لاكتشاف أي أخطاء عند الزحف إلى الصفحة.
لإعلام Googlebot بعدم إمكانية الزحف إلى صفحة أو فهرستها، استخدِم رمز حالة مفيدًا، مثل 404 لصفحة لا يمكن العثور عليها، أو رمز 401 للصفحات المحمية بتسجيل الدخول.
ويمكنك استخدام رموز حالة HTTP لإعلام Googlebot عند نقل الصفحة إلى عنوان URL جديد لكي يكون بالإمكان تعديل الفهرس وفقًا لذلك.
في ما يلي قائمة برموز حالة HTTP وكيفية تأثيرها في "بحث Google".
تجنُّب أخطاء soft 404 في تطبيقات الصفحة الواحدة
في تطبيقات الصفحة الواحدة المعروضة من جهة العميل، غالبًا ما يتم تنفيذ التوجيه كتوجيه من جهة العميل.
في هذه الحالة، قد يكون استخدام رموز حالة HTTP المفيدة غير ممكن أو غير عملي.
لتجنُّب أخطاء soft 404 عند استخدام العرض والتوجيه من جهة العميل، استخدِم إحدى الاستراتيجيتَين التاليتَين:
- استخدِم إعادة توجيه JavaScript إلى عنوان URL يستجيب له الخادم برمز حالة HTTP
404(مثلاً،/not-found). - أضِف
<meta name="robots" content="noindex">إلى صفحات الخطأ باستخدام JavaScript.
في ما يلي رمز نموذجي لطريقة إعادة التوجيه:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. window.location.href = '/not-found'; // redirect to 404 page on the server. } })
في ما يلي رمز نموذجي لطريقة استخدام العلامة noindex:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. // Note: This example assumes there is no other robots meta tag present in the HTML. const metaRobots = document.createElement('meta'); metaRobots.name = 'robots'; metaRobots.content = 'noindex'; document.head.appendChild(metaRobots); } })
استخدام History API بدلاً من الأجزاء
ليس بإمكان محرّك بحث Google اكتشاف الروابط الخاصة بك إلا إذا كانت عناصر HTML تتضمن <a> مع سمة href.
في تطبيقات الصفحة الواحدة التي تتضمّن توجيهًا من جهة العميل، استخدِم History API لتنفيذ التوجيه بين طرق العرض المختلفة لتطبيق الويب. ولضمان أنّه يمكن لبرنامج Googlebot تحليل عناوين URL واستخراجها، تجنَّب استخدام الأجزاء لتحميل محتوى من صفحة مختلفة. في ما يلي مثال عن إجراء غير صحيح يمنع Googlebot من معالجة عناوين URL بشكل موثوق:
<nav> <ul> <li><a href="#/products">Our products</a></li> <li><a href="#/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="#/products">our products</a> and <a href="#/services">our services</a></p> </div> <script> window.addEventListener('hashchange', function goToPage() { // this function loads different content based on the current URL fragment const pageToLoad = window.location.hash.slice(1); // URL fragment document.getElementById('placeholder').innerHTML = load(pageToLoad); }); </script>
بدلاً من ذلك، يمكنك التأكّد من إمكانية وصول Googlebot إلى عناوين URL من خلال تنفيذ History API:
<nav> <ul> <li><a href="/products">Our products</a></li> <li><a href="/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="/products">our products</a> and <a href="/services">our services</a></p> </div> <script> function goToPage(event) { event.preventDefault(); // stop the browser from navigating to the destination URL. const hrefUrl = event.target.getAttribute('href'); const pageToLoad = hrefUrl.slice(1); // remove the leading slash document.getElementById('placeholder').innerHTML = load(pageToLoad); window.history.pushState({}, window.title, hrefUrl) // Update URL as well as browser history. } // Enable client-side routing for all links on the page document.querySelectorAll('a').forEach(link => link.addEventListener('click', goToPage)); </script>
إدخال علامة رابط rel="canonical" بشكل صحيح
لا ننصح باستخدام JavaScript لهذا الإجراء، ولكن من الممكن إدخال علامة رابط rel="canonical" من خلال JavaScript.
سيختار محرّك بحث Google عنوان URL الأساسي الذي تم إدخاله عند عرض الصفحة. في ما يلي مثال على إدخال علامة رابط rel="canonical" باستخدام JavaScript:
fetch('/api/cats/' + id) .then(function (response) { return response.json(); }) .then(function (cat) { // creates a canonical link tag and dynamically builds the URL // e.g. https://example.com/cats/simba const linkTag = document.createElement('link'); linkTag.setAttribute('rel', 'canonical'); linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName; document.head.appendChild(linkTag); });
استخدام العلامات meta لبرامج robots بعناية
يمكنك منع محرّك بحث Google من فهرسة إحدى الصفحات أو متابعة الروابط من خلال العلامات meta لبرامج robots.
على سبيل المثال، إذا أضفت العلامة meta التالية إلى أعلى صفحتك، ستمنع محرّك بحث Google من فهرستها:
<!-- Google won't index this page or follow links on this page --> <meta name="robots" content="noindex, nofollow">
يمكنك استخدام JavaScript لإضافة العلامة meta لبرامج robots إلى صفحة معيّنة أو تغيير محتواها.
يعرض الرمز في المثال التالي طريقة تغيير العلامة meta لبرامج robots باستخدام JavaScript لمنع فهرسة الصفحة الحالية إذا لم يؤدِّ طلب البيانات من واجهة برمجة التطبيقات إلى عرض أي محتوى.
fetch('/api/products/' + productId) .then(function (response) { return response.json(); }) .then(function (apiResponse) { if (apiResponse.isError) { // get the robotsmetatag var metaRobots = document.querySelector('meta[name="robots"]'); // if there was no robotsmetatag, add one if (!metaRobots) { metaRobots = document.createElement('meta'); metaRobots.setAttribute('name', 'robots'); document.head.appendChild(metaRobots); } // tell Google to exclude this page from the index metaRobots.setAttribute('content', 'noindex'); // display an error message to the user errorMsg.textContent = 'This product is no longer available'; return; } // display product information // ... });
عندما يصادف محرّك بحث Google noindex في العلامة meta لبرامج robots قبل تشغيل JavaScript، لا يعرض الصفحة ولا يفهرسها.
استخدام التخزين المؤقّت الطويل الأجل
ينشط Googlebot في التخزين المؤقّت لتقليل طلبات الشبكة واستخدام الموارد. وقد تتجاهل خدمة WRS رؤوس التخزين المؤقّت. وقد يؤدي ذلك إلى استخدام WRS لموارد JavaScript أو CSS قديمة.
تتجنّب بصمة المحتوى هذه المشكلة من خلال جعل بصمة من المحتوى جزءًا من اسم الملف، مثل main.2bb85551.js.
وتعتمد البصمة على محتوى الملف، لذا يتم إنشاء اسم ملف مختلف كلما تم إجراء تعديلات.
يمكنك الاطّلاع على دليل web.dev لمزيد من المعلومات عن استراتيجيات التخزين المؤقّت الطويل الأجل.
استخدام البيانات المنظَّمة
عند استخدام البيانات المنظَّمة على صفحاتك، يمكنك استخدام JavaScript لإنشاء محتوى JSON-LD المطلوب وإدخاله في الصفحة. احرص على اختبار نجاح العملية لتجنُّب حدوث المشاكل.
اتّباع أفضل الممارسات الخاصة بمكوّنات الويب
يتيح محرّك بحث Google إمكانية استخدام عناصر الويب. عندما يعرض محرّك بحث Google صفحة، يعمل على تنظيم المحتوى في shadow DOM وlight DOM. يعني ذلك أنّ بإمكان Google رؤية المحتوى المرئي فقط في رمز HTML المعروض. للتأكَّد من أنّ بإمكان محرّك بحث Google رؤية المحتوى بعد عرضه، استخدِم اختبار النتائج الغنية بصريًا أو أداة فحص عنوان URL وتحقَّق من محتوى HTML المعروض.
إذا لم يكُن المحتوى مرئيًا في رمز HTML المعروض، لن يتمكّن محرك بحث Google من فهرسته.
في المثال التالي، يتم إنشاء مكوّن ويب يعرض محتوى light DOM داخل shadow DOM. يمكنك استخدام العنصر خانة للتأكد من عرض محتوى light DOM وshadow DOM في رمز HTML المعروض.
<script>
class MyComponent extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
let p = document.createElement('p');
p.innerHTML = 'Hello World, this is shadow DOM content. Here comes the light DOM: <slot></slot>';
this.shadowRoot.appendChild(p);
}
}
window.customElements.define('my-component', MyComponent);
</script>
<my-component>
<p>This is light DOM content. It's projected into the shadow DOM.</p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>بعد العرض، سيعمل محرّك بحث Google على فهرسة هذا المحتوى:
<my-component>
Hello World, this is shadow DOM content. Here comes the light DOM:
<p>This is light DOM content. It's projected into the shadow DOM<p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
حلّ مشاكل الصور باستخدام التحميل الكسول للمحتوى
يمكن أن تكون متطلبات تحميل الصور عالية جدًا في ما يتعلّق بمعدل نقل البيانات والتنفيذ. ومن الاستراتيجيات المفيدة استخدام التحميل الكسول ليتم تحميل الصور مباشرةً قبل عرضها للمستخدم. لضمان تنفيذ التحميل الكسول للمحتوى بطريقة تسهّل عملية البحث، اتّبِع إرشاداتنا الخاصة بالتحميل الكسول.
مراعاة تسهيل الاستخدام عند تصميم الموقع الإلكتروني
إنشاء صفحات للمستخدمين، وليس لمحركات البحث فقط عند تصميم موقعك الإلكتروني، فكِّر في احتياجات المستخدمين، بمن فيهم أولئك الذين لا يستخدمون متصفحًا متوافقًا مع JavaScript (على سبيل المثال، الأشخاص الذين يستخدمون برامج قراءة الشاشة أو الأجهزة الجوّالة). وكوسيلة سهلة لاختبار مدى سهولة الوصول إلى موقعك الإلكتروني، يمكنك معاينته في متصفحك مع إيقاف JavaScript، أو عرضه في متصفح نصي فقط، مثل Lynx. وقد يساعد عرض موقع إلكتروني كنصّ فقط في تحديد المحتوى الآخر الذي قد يصعب على محرّك بحث Google رؤيته، مثل النص المضمّن في الصور.