Memahami dasar-dasar SEO JavaScript
JavaScript adalah bagian penting dari platform web dengan berbagai fiturnya yang mengubah web menjadi platform aplikasi yang canggih. Jadikan aplikasi web Anda, yang dikembangkan dengan teknologi JavaScript, dapat ditemukan melalui Google Penelusuran, agar Anda dapat menemukan pengguna baru dan berinteraksi kembali dengan pengguna yang sudah ada saat mereka menelusuri konten yang disediakan oleh aplikasi web Anda. Meskipun Google Penelusuran menjalankan JavaScript dengan versi Chromium yang selalu baru, ada beberapa hal yang dapat Anda optimalkan.
Panduan ini menjelaskan cara Google Penelusuran memproses JavaScript dan praktik terbaik guna meningkatkan kualitas aplikasi web JavaScript untuk Google Penelusuran.
Cara Google memproses JavaScript
Google memproses aplikasi web JavaScript melalui tiga fase utama:
- Crawling
- Rendering
- Pengindeksan
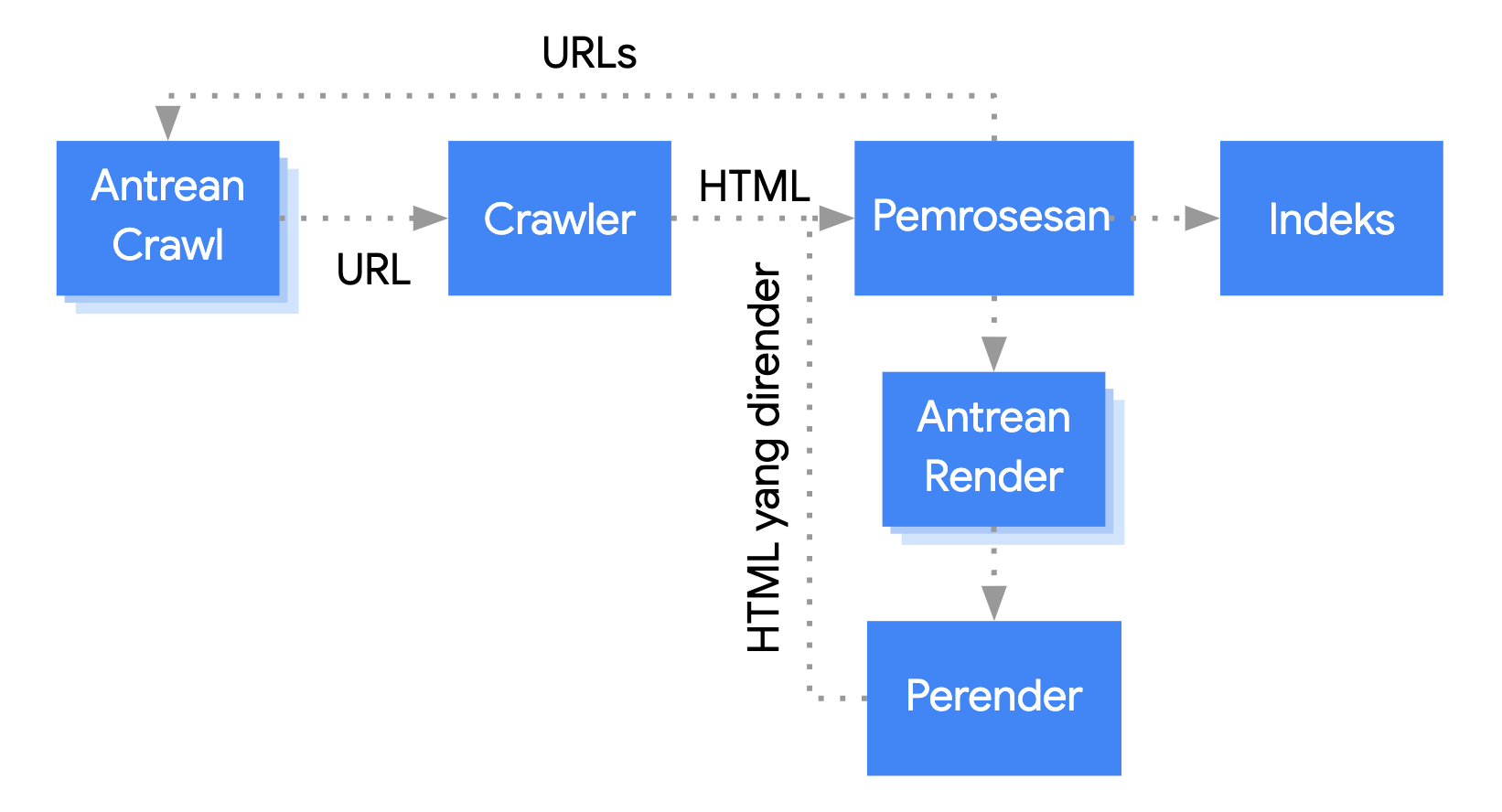
Googlebot mengantrekan halaman untuk di-crawl dan dirender. Anda tidak bisa langsung mengetahui kapan sebuah halaman sedang menunggu untuk di-crawl dan sedang menunggu untuk dirender. Saat Googlebot mengambil URL dari antrean crawling dengan membuat permintaan HTTP, pertama-tama Googlebot akan memeriksa apakah Anda mengizinkan crawling. Googlebot akan membaca file robots.txt. Jika file tersebut menandai URL Anda sebagai tidak boleh di-crawl, Googlebot tidak akan membuat permintaan HTTP ke URL ini dan akan melewatinya. Google Penelusuran tidak akan merender JavaScript dari file yang diblokir atau di halaman yang diblokir.
Selanjutnya, Googlebot akan mengurai respons untuk URL lain dalam atribut href link HTML dan menambahkan URL tersebut ke antrean crawl. Jika Anda tidak ingin link ditemukan, gunakan mekanisme nofollow.
Crawling URL dan penguraian respons HTML sangat efektif untuk situs klasik atau halaman yang dirender di sisi server saat HTML dalam respons HTTP memuat semua konten. Beberapa situs JavaScript mungkin menggunakan model app shell yang HTML awalnya tidak berisi konten sebenarnya sehingga Google harus menjalankan JavaScript agar dapat melihat konten halaman sebenarnya yang dihasilkan JavaScript.
Googlebot mengantrekan semua halaman untuk dirender, kecuali jika header atau tag meta robots melarang Google mengindeks halaman tersebut.
Halaman mungkin berada dalam antrean ini selama beberapa detik, tetapi bisa juga lebih lama. Begitu resource Google mengizinkan, Chromium headless akan merender halaman tersebut dan menjalankan JavaScript.
Googlebot kembali mengurai HTML yang telah dirender untuk menemukan link, dan mengantrekan URL yang ditemukannya untuk di-crawl. Google juga menggunakan HTML yang telah dirender untuk mengindeks halaman.
Perlu diingat bahwa sisi server atau pra-rendering masih merupakan ide bagus karena menjadikan situs Anda lebih cepat bagi pengguna dan crawler. Selain itu, tidak semua bot dapat menjalankan JavaScript.
Mendeskripsikan halaman dengan cuplikan dan judul unik
Elemen <title> dan deskripsi meta yang unik dan deskriptif membantu pengguna mengidentifikasi hasil terbaik untuk tujuan mereka dengan cepat.
Anda dapat menggunakan JavaScript untuk menetapkan atau mengubah deskripsi meta serta elemen <title>.
Menulis kode yang kompatibel
Browser menawarkan banyak API, dan JavaScript adalah bahasa yang berkembang cepat. Google memiliki beberapa batasan terkait fitur API dan JavaScript yang didukungnya. Untuk memastikan kode Anda kompatibel dengan Google, ikuti panduan memecahkan masalah JavaScript.
Sebaiknya gunakan polyfill dan penayangan diferensial jika pendeteksian fitur yang Anda lakukan menyatakan bahwa API browser yang diperlukan tidak disertakan. Karena beberapa fitur browser tidak dapat di-polyfill, sebaiknya Anda memeriksa dokumentasi polyfill untuk menemukan potensi keterbatasan.
Menggunakan kode status HTTP yang bermakna
Googlebot menggunakan kode status HTTP untuk mengetahui apakah terjadi error saat meng-crawl halaman.
Untuk memberi tahu Googlebot jika halaman tidak dapat di-crawl atau diindeks, gunakan kode status yang bermakna, seperti 404 untuk halaman yang tidak dapat ditemukan, atau kode 401 untuk halaman yang memerlukan login.
Anda dapat menggunakan kode status HTTP untuk memberi tahu Googlebot jika sebuah halaman telah dipindahkan ke URL baru, sehingga indeks dapat diperbarui berdasarkan kondisi tersebut.
Berikut ini daftar kode status HTTP dan pengaruhnya terhadap Google Penelusuran.
Menghindari error soft 404 di aplikasi web satu halaman
Dalam aplikasi web satu halaman yang dirender di sisi klien, pemilihan rute sering diimplementasikan sebagai pemilihan rute sisi klien.
Dalam hal ini, menggunakan kode status HTTP yang bermakna bisa jadi tidak mungkin untuk dilakukan atau tidak praktis.
Untuk menghindari error soft 404 saat menggunakan rendering dan pemilihan rute sisi klien, gunakan salah satu strategi berikut:
- Gunakan pengalihan JavaScript ke URL yang akan direspons server dengan kode status HTTP
404(misalnya/not-found). - Tambahkan
<meta name="robots" content="noindex">ke halaman error menggunakan JavaScript.
Berikut adalah kode contoh untuk pendekatan pengalihan:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. window.location.href = '/not-found'; // redirect to 404 page on the server. } })
Berikut adalah kode contoh untuk pendekatan tag noindex:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. // Note: This example assumes there is no other robots meta tag present in the HTML. const metaRobots = document.createElement('meta'); metaRobots.name = 'robots'; metaRobots.content = 'noindex'; document.head.appendChild(metaRobots); } })
Menggunakan History API, bukan fragmen
Google hanya dapat menemukan link Anda jika link tersebut merupakan elemen HTML <a> dengan atribut href.
Untuk aplikasi web satu halaman dengan pemilihan rute sisi klien, gunakan History API untuk mengimplementasikan pemilihan rute antara tampilan yang berbeda di aplikasi web Anda. Untuk memastikan bahwa Googlebot dapat mengurai dan mengekstrak URL Anda, hindari penggunaan fragmen untuk memuat konten halaman yang berbeda. Contoh berikut adalah praktik yang buruk, karena Googlebot tidak dapat me-resolve URL dengan andal:
<nav> <ul> <li><a href="#/products">Our products</a></li> <li><a href="#/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="#/products">our products</a> and <a href="#/services">our services</a></p> </div> <script> window.addEventListener('hashchange', function goToPage() { // this function loads different content based on the current URL fragment const pageToLoad = window.location.hash.slice(1); // URL fragment document.getElementById('placeholder').innerHTML = load(pageToLoad); }); </script>
Sebaliknya, Anda dapat memastikan URL dapat diakses oleh Googlebot dengan mengimplementasikan History API:
<nav> <ul> <li><a href="/products">Our products</a></li> <li><a href="/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="/products">our products</a> and <a href="/services">our services</a></p> </div> <script> function goToPage(event) { event.preventDefault(); // stop the browser from navigating to the destination URL. const hrefUrl = event.target.getAttribute('href'); const pageToLoad = hrefUrl.slice(1); // remove the leading slash document.getElementById('placeholder').innerHTML = load(pageToLoad); window.history.pushState({}, window.title, hrefUrl) // Update URL as well as browser history. } // Enable client-side routing for all links on the page document.querySelectorAll('a').forEach(link => link.addEventListener('click', goToPage)); </script>
Memasukkan tag link rel="canonical" dengan benar
Meskipun kami tidak merekomendasikan hal ini, Anda dapat memasukkan tag link rel="canonical" menggunakan JavaScript.
Google Penelusuran akan mengambil URL kanonis yang dimasukkan saat merender halaman. Berikut contoh cara memasukkan tag link rel="canonical" menggunakan JavaScript:
fetch('/api/cats/' + id) .then(function (response) { return response.json(); }) .then(function (cat) { // creates a canonical link tag and dynamically builds the URL // e.g. https://example.com/cats/simba const linkTag = document.createElement('link'); linkTag.setAttribute('rel', 'canonical'); linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName; document.head.appendChild(linkTag); });
Menggunakan tag meta robots dengan cermat
Dengan tag meta robots, Anda dapat mencegah Google mengindeks halaman atau mengikuti link.
Misalnya, Anda dapat menambahkan tag meta berikut ke bagian atas halaman untuk mencegah Google mengindeks halaman tersebut:
<!-- Google won't index this page or follow links on this page --> <meta name="robots" content="noindex, nofollow">
Anda dapat menggunakan JavaScript untuk menambahkan tag meta robots ke suatu halaman atau untuk mengubah kontennya.
Kode contoh berikut menunjukkan cara mengubah tag meta robots dengan JavaScript untuk mencegah pengindeksan halaman saat ini jika panggilan API tidak menampilkan konten.
fetch('/api/products/' + productId) .then(function (response) { return response.json(); }) .then(function (apiResponse) { if (apiResponse.isError) { // get the robotsmetatag var metaRobots = document.querySelector('meta[name="robots"]'); // if there was no robotsmetatag, add one if (!metaRobots) { metaRobots = document.createElement('meta'); metaRobots.setAttribute('name', 'robots'); document.head.appendChild(metaRobots); } // tell Google to exclude this page from the index metaRobots.setAttribute('content', 'noindex'); // display an error message to the user errorMsg.textContent = 'This product is no longer available'; return; } // display product information // ... });
Jika noindex ditemukan dalam tag meta robots sebelum menjalankan JavaScript, Google tidak akan merender atau mengindeks halaman tersebut.
Menggunakan cache yang tahan lama
Googlebot melakukan cache secara terus-menerus untuk mengurangi permintaan jaringan dan penggunaan resource. WRS dapat mengabaikan header cache. Hal ini dapat menyebabkan WRS menggunakan resource JavaScript atau CSS yang sudah tidak berlaku.
Pelacakan sidik jari konten mencegah masalah ini dengan membuat sidik jari dari bagian konten nama file, seperti main.2bb85551.js.
Sidik jari bergantung pada konten file, sehingga pembaruan akan menghasilkan nama file yang berbeda setiap kalinya.
Lihat panduan web.dev tentang strategi cache yang tahan lama untuk mempelajari lebih lanjut.
Menggunakan data terstruktur
Saat menggunakan data terstruktur di halaman, Anda dapat menggunakan JavaScript untuk menghasilkan JSON-LD yang diperlukan dan memasukkannya ke dalam halaman tersebut. Pastikan untuk menguji implementasi Anda guna menghindari masalah.
Mengikuti praktik terbaik untuk komponen web
Google mendukung komponen web. Konten shadow DOM dan light DOM akan di-flatten oleh Google saat merender halaman. Artinya, Google hanya dapat melihat konten yang terlihat di HTML yang telah dirender. Untuk memastikan Googlebot tetap dapat melihat konten Anda setelah dirender, gunakan Pengujian Hasil Multimedia atau Alat Inspeksi URL dan lihat HTML yang dirender tersebut.
Jika konten tidak terlihat di HTML yang telah dirender, Google tidak akan dapat mengindeksnya.
Contoh berikut membuat komponen web yang menampilkan konten light DOM-nya di dalam shadow DOM-nya. Salah satu cara untuk memastikan konten light DOM dan shadow DOM ditampilkan dalam HTML yang telah dirender adalah menggunakan elemen Slot.
<script>
class MyComponent extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
let p = document.createElement('p');
p.innerHTML = 'Hello World, this is shadow DOM content. Here comes the light DOM: <slot></slot>';
this.shadowRoot.appendChild(p);
}
}
window.customElements.define('my-component', MyComponent);
</script>
<my-component>
<p>This is light DOM content. It's projected into the shadow DOM.</p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>Setelah proses rendering, Google dapat mengindeks konten ini:
<my-component>
Hello World, this is shadow DOM content. Here comes the light DOM:
<p>This is light DOM content. It's projected into the shadow DOM<p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
Memperbaiki gambar dan konten yang lambat dimuat
Gambar dapat menguras bandwidth dan menurunkan performa. Salah satu strategi yang dianjurkan adalah menggunakan pemuatan lambat untuk memuat gambar hanya saat pengguna akan melihatnya. Untuk memastikan implementasi pemuatan lambat Anda cocok untuk penelusuran, baca panduan pemuatan lambat kami.
Mendesain untuk aksesibilitas
Buatlah halaman untuk pengguna, bukan hanya mesin telusur. Saat Anda mendesain situs, pertimbangkan tentang kebutuhan pengguna, termasuk mereka yang mungkin tidak menggunakan browser yang dilengkapi JavaScript (misalnya mereka yang menggunakan pembaca layar atau perangkat seluler yang kurang canggih). Salah satu cara termudah untuk menguji aksesibilitas situs Anda adalah dengan mempratinjaunya di browser Anda dengan JavaScript yang dinonaktifkan, atau dengan melihatnya di browser khusus teks seperti Lynx. Menampilkan situs hanya sebagai teks juga dapat membantu Anda mengidentifikasi konten lain yang mungkin sulit dilihat Google, seperti teks yang disematkan dalam gambar.