JavaScript SEO temel kavramlarını anlama
JavaScript, web'i güçlü bir uygulama platformuna dönüştüren birçok özellik sağlamasından dolayı web platformunun önemli bir parçasıdır. JavaScript destekli web uygulamalarınızı Google Arama aracılığıyla bulunabilir hale getirmek, yeni kullanıcılar bulmanıza ve web uygulamanızın sağladığı içeriği ararlarken mevcut kullanıcılarla yeniden etkileşime geçmenize yardımcı olabilir. Google Arama, JavaScript’i Chromium’un evergreen sürümüyle çalıştırırken birkaç şeyi optimize edebilirsiniz.
Bu kılavuzda, Google Arama'nın JavaScript'i nasıl işlediği ve Google Arama için JavaScript web uygulamalarını iyileştirmeye yönelik en iyi uygulamalar açıklanmaktadır.
Google, JavaScript'i nasıl işler?
Google, JavaScript web uygulamalarını üç ana aşamada işler:
- Tarama
- Oluşturma
- Dizine ekleme
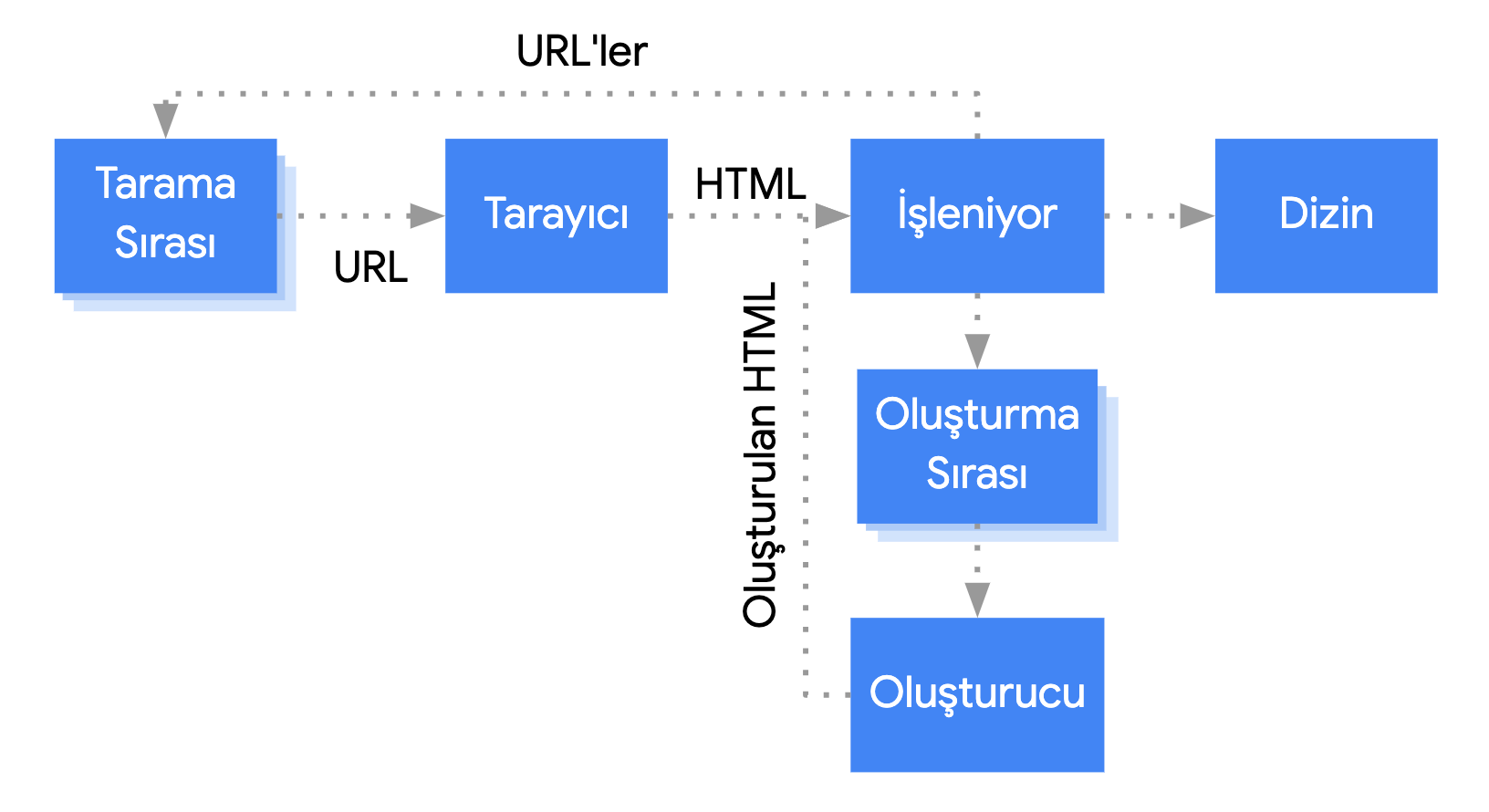
Googlebot, hem tarama hem de oluşturma için sayfaları sıraya alır. Bir sayfanın taranmayı mı yoksa oluşturulmayı mı beklediği hemen anlaşılmaz.
Googlebot, bir HTTP isteğinde bulunarak tarama sırasından bir URL getirdiğinde öncelikle taramaya izin verip vermediğinizi kontrol eder. Googlebot, robots.txt dosyasını okur. URL'yi izin verilmiyor olarak işaretlerse Googlebot, bu URL için bir HTTP isteği oluşturmayı ve URL'yi atlar.
Googlebot, daha sonra HTML bağlantılarının hrefözelliğindeki diğer URL’lerin yanıtlarını ayrıştırır ve URL’leri tarama sırasına ekler. Bağlantının keşfedilmesini engellemek için nofollow mekanizmasını kullanın.
Bir URL'nin taranması ve HTML yanıtının ayrıştırılması, klasik web sitelerinde veya HTTP yanıtındaki HTML'nin tüm içeriği barındırdığı sunucu tarafında oluşturulmuş sayfalarda iyi sonuç verir. Bazı JavaScript siteleri, ilk HTML'nin asıl içeriği barındırmadığı uygulama kabuğu modelini kullanabilir ve Google'ın, JavaScript'in oluşturduğu asıl sayfa içeriğini görebilmesi için önce JavaScript'i yürütmesi gerekir.
Bir robots meta etiketi veya başlığı Google'ın sayfayı dizine eklememesi gerektiğini bildirmedikçe, Googlebot tüm sayfaları oluşturmak üzere sıraya alır. Sayfanın sırada kalma süresi birkaç saniye olabilir ancak bundan daha uzun da sürebilir. Google’ın kaynakları izin verdiğinde, bir gözetimsiz Chromium sayfayı oluşturur ve JavaScript’i yürütür. Googlebot, oluşturulan HTML’yi bağlantılar için tekrar ayrıştırır ve bulduğu URL’leri taramak üzere sıraya alır. Google, oluşturulan HTML'yi sayfanın dizine eklenmesi için de kullanır.
Sunucu tarafı veya ön oluşturma işleminin hâlâ iyi bir fikir olduğunu unutmayın. Böylece web siteniz kullanıcılar ve tarayıcılar için daha hızlı hale gelir ve tüm botlar JavaScript'i çalıştıramaz.
Sayfanızı benzersiz başlıklar ve snippet'ler ile açıklayın
Benzersiz, açıklayıcı <title> öğeleri ve faydalı meta tanımlar, kullanıcıların yaptıkları aramayla ilgili en iyi sonucu hızlı bir şekilde belirlemelerine yardımcı olur. İyi <title> öğesinin ve meta açıklamaların nasıl olacağı yönergelerimizde açıklanmaktadır.
JavaScript'i, <title> öğesinin yanı sıra meta tanımı ayarlamak veya değiştirmek için de kullanabilirsiniz.
Google Arama, kullanıcının sorgusuna göre farklı bir başlık bağlantısı gösterebilir.
Bu durum, başlık veya açıklamanın sayfa içeriği ile alaka düzeyi düşük olduğunda veya sayfada, arama sorgusuyla daha iyi eşleşen alternatifler bulduğumuzda ortaya çıkar. Arama sonucu başlığının sayfadaki <title> öğesinden neden farklı olduğu ile ilgili daha fazla bilgi edinin.
Uyumlu kod yazın
Tarayıcılar birçok API sunar ve JavaScript hızlı gelişen bir dildir. Google’ın desteklediği API’ler ve JavaScript özellikleri konusunda bazı sınırlamalar vardır. Kodunuzun Google ile uyumlu olduğundan emin olmak için JavaScript sorunlarını gidermeye yönelik yönergelerimizi uygulayın.
Özellik algılama ile ihtiyacınız olan eksik bir tarayıcı API'sini belirlerseniz farklı sunum ve çoklu dolguları kullanmanızı öneririz. Bazı tarayıcı özellikleri çoklu doldurulamadığından, potansiyel sınırlamalar için çoklu doldurma belgelerine göz atmanızı tavsiye ederiz.
Anlamlı HTTP durum kodları kullanın
Googlebot, sayfayı tararken bir şeylerin ters gidip gitmediğini öğrenmek için HTTP durum kodlarını kullanır.
Googlebot’a bir sayfanın taranamayacağını veya dizine eklenemeyeceğini bildirmek için anlamlı bir durum kodu kullanın. Örneğin, bulunamayan bir sayfa için 404 veya kullanıcının giriş yapmasını gerektiren sayfalar için 401 belirtebilirsiniz. Googlebot’a bir sayfanın yeni bir URL’ye taşındığını bildirmek için HTTP durum kodlarını kullanabilir ve böylece, dizinin uygun şekilde güncellenmesini sağlayabilirsiniz.
HTTP durum kodlarının listesini ve Google Arama'yı nasıl etkilediklerini buradan öğrenebilirsiniz.
Tek sayfalık uygulamalarda soft 404 hatalarından kaçınma
İstemci taraflı oluşturulan tek sayfalık uygulamalarda yönlendirme, genellikle istemci taraflı yönlendirme olarak uygulanır.
Bu durumda, anlamlı HTTP durum kodları kullanmak mümkün ya da pratik olmayabilir.
İstemci taraflı oluşturma ve yönlendirme kullanırken soft 404 hatalarından kaçınmak için aşağıdaki stratejilerden birini uygulayın:
- Sunucunun
404HTTP durum koduyla (örneğin,/not-found) yanıt verdiği URL'ye JavaScript yönlendirmesi kullanın. - JavaScript kullanarak hata sayfalarına
<meta name="robots" content="noindex">ekleyin.
Aşağıda, yönlendirme yaklaşımı için örnek kod verilmiştir:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. window.location.href = '/not-found'; // redirect to 404 page on the server. } })
Aşağıda, noindex yaklaşımı için örnek kod verilmiştir:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. // Note: This example assumes there is no other robots meta tag present in the HTML. const metaRobots = document.createElement('meta'); metaRobots.name = 'robots'; metaRobots.content = 'noindex'; document.head.appendChild(metaRobots); } })
Parçalar yerine History API'yi kullanma
Google, bağlantınızı yalnızca href özelliğine sahip bir <a> HTML öğesi ise tarayabilir.
İstemci taraflı yönlendirmesi olan tek sayfalık uygulamalarda, web uygulamanızın farklı görünümleri arasında yönlendirme yapmak için History API'yi kullanın. Googlebot’un URL’lerinizi ayrıştırıp alabilmesi için, farklı sayfa içeriği yüklemek üzere parçalar kullanmaktan kaçının. Aşağıda, Googlebot URL'leri güvenilir bir şekilde çözemediği kötü bir kullanım örneği verilmiştir:
<nav> <ul> <li><a href="#/products">Our products</a></li> <li><a href="#/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="#/products">our products</a> and <a href="#/services">our services</p> </div> <script> window.addEventListener('hashchange', function goToPage() { // this function loads different content based on the current URL fragment const pageToLoad = window.location.hash.slice(1); // URL fragment document.getElementById('placeholder').innerHTML = load(pageToLoad); }); </script>
Bunun yerine, History API'yi uygulayarak Googlebot'un bağlantı URL'lerine eriştiğinden emin olabilirsiniz:
<nav> <ul> <li><a href="/products">Our products</a></li> <li><a href="/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="/products">our products</a> and <a href="/services">our services</p> </div> <script> function goToPage(event) { event.preventDefault(); // stop the browser from navigating to the destination URL. const hrefUrl = event.target.getAttribute('href'); const pageToLoad = hrefUrl.slice(1); // remove the leading slash document.getElementById('placeholder').innerHTML = load(pageToLoad); window.history.pushState({}, window.title, hrefUrl) // Update URL as well as browser history. } // Enable client-side routing for all links on the page document.querySelectorAll('a').forEach(link => link.addEventListener('click', goToPage)); </script>
rel="canonical" bağlantı etiketini düzgün bir şekilde yerleştirme
Bu işlem için JavaScript kullanılmasını önermesek de JavaScript ile rel="canonical" bağlantı etiketi yerleştirmek mümkündür.
Google Arama, yerleştirilen standart URL'yi sayfayı oluştururken alır.
JavaScript kullanarak rel="canonical" bağlantı etiketi yerleştirmeyle ilgili bir örneği aşağıda bulabilirsiniz:
fetch('/api/cats/' + id) .then(function (response) { return response.json(); }) .then(function (cat) { // creates a canonical link tag and dynamically builds the URL // e.g. https://example.com/cats/simba const linkTag = document.createElement('link'); linkTag.setAttribute('rel', 'canonical'); linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName; document.head.appendChild(linkTag); });
robots meta etiketlerini dikkatli kullanma
Google’ın bir sayfayı dizine eklemesini veya bağlantıları izlemesini robots meta etiketi aracılığıyla engelleyebilirsiniz.
Örneğin sayfanızın en üst kısmına aşağıdaki meta etiketi eklediğinizde, Google'ın sayfayı dizine eklemesi engellenir:
<!-- Google won't index this page or follow links on this page --> <meta name="robots" content="noindex, nofollow">
Bir sayfaya robots meta etiketi eklemek veya içeriğini değiştirmek için JavaScript'i kullanabilirsiniz. Aşağıdaki örnek kod, bir API çağrısının içerik döndürmemesi durumunda, geçerli sayfanın dizine eklenmesini önlemek için robots meta etiketinin JavaScript ile nasıl değiştirileceğini göstermektedir.
fetch('/api/products/' + productId) .then(function (response) { return response.json(); }) .then(function (apiResponse) { if (apiResponse.isError) { // get the robotsmetatag var metaRobots = document.querySelector('meta[name="robots"]'); // if there was no robotsmetatag, add one if (!metaRobots) { metaRobots = document.createElement('meta'); metaRobots.setAttribute('name', 'robots'); document.head.appendChild(metaRobots); } // tell Google to exclude this page from the index metaRobots.setAttribute('content', 'noindex'); // display an error message to the user errorMsg.textContent = 'This product is no longer available'; return; } // display product information // ... });
Google, JavaScript'i çalıştırmadan önce robots meta etiketinde noindex ile karşılaştığında, sayfayı oluşturmaz veya dizine eklemez.
Uzun ömürlü önbelleğe almayı kullanma
Googlebot, ağ isteklerini ve kaynak kullanımını azaltmak için yüksek düzeyde önbellek kullanır. WRS, önbelleğe alma üst bilgilerini yok sayabilir. Bu, WRS'nin güncel olmayan JavaScript veya CSS kaynaklarını kullanmasına neden olabilir. İçerik parmak izi, dosya adının bir bölümünü içeriğin parmak izi yaparak (main.2bb85551.js gibi) bu sorunu önler.
Parmak izi, dosyanın içeriğine bağlı olduğundan güncellemelerde her seferinde farklı bir dosya adı oluşturulur. Daha fazla bilgi edinmek için uzun süreli önbelleğe alma stratejilerinde web.dev kılavuzuna bakın.
Yapılandırılmış veri kullanma
Sayfalarınızda yapılandırılmış veri kullanırken gerekli JSON-LD'yi oluşturup sayfaya yerleştirmek için JavaScript'i kullanabilirsiniz. Sorunları önlemek için uygulamanızı test ettiğinizden emin olun.
Web bileşenleri için en iyi uygulamaları takip edin
Google, web bileşenlerini destekler. Google bir sayfa oluşturduğunda gölge DOM ve ışık DOM içeriğini birleştirir. Bu, Google'ın yalnızca oluşturulan HTML'de görülebilen içeriği görebileceği anlamına gelir. Google'ın içeriğinizi oluşturulduktan sonra da görebilmesini sağlamak için Mobil Uyumluluk Testi veya URL Denetleme Aracı'nı kullanın ve oluşturulan HTML'ye bakın.
Google oluşturulan HTML'de görünmeyen içeriği dizine ekleyemez.
Aşağıdaki örnekte, ışık DOM'u içeriğini gölge DOM'u içinde gösteren bir web bileşeni oluşturulmaktadır. Hem ışık DOM'u hem gölge DOM'u içeriğinin oluşturulan HTML'de gösterilmesini sağlamanın bir yolu, Slot öğesini kullanmaktır.
<script> class MyComponent extends HTMLElement { constructor() { super(); this.attachShadow({ mode: 'open' }); } connectedCallback() { let p = document.createElement('p'); p.innerHTML = 'Hello World, this is shadow DOM content. Here comes the light DOM: <slot></slot>'; this.shadowRoot.appendChild(p); } } window.customElements.define('my-component', MyComponent); </script> <my-component> <p>This is light DOM content. It's projected into the shadow DOM.</p> <p>WRS renders this content as well as the shadow DOM content.</p> </my-component>
Oluşturulduktan sonra, Google şu içeriği dizine ekleyebilir:
<my-component> Hello World, this is shadow DOM content. Here comes the light DOM: <p>This is light DOM content. It's projected into the shadow DOM<p> <p>WRS renders this content as well as the shadow DOM content.</p> </my-component>
Resimleri ve geç yüklenen içeriği düzeltin
Resimler, bant genişliği ve performans açısından oldukça maliyetli olabilir. Resimleri yalnızca kullanıcı görmek üzereyken yüklemek için geç yükleme özelliğini kullanmak iyi bir stratejidir. Geç yüklemeyi aramaya uygun bir şekilde uyguladığınızdan emin olmak için geç yükleme yönergelerimizi uygulayın.
Erişilebilirliğe göz önünde bulundurarak tasarım yapın
Yalnızca arama motorları için değil, kullanıcılar için sayfalar oluşturun. Sitenizi tasarlarken, JavaScript uyumlu tarayıcıları kullanamayan kullanıcılar da (örneğin, ekran okuyucuları veya mobil cihazlar kullanan kişiler) dahil olmak üzere, kullanıcılarınızın ihtiyaçlarını düşünün. Sitenizin erişilebilirliğini test etmenin en kolay yollarından birisi, JavaScript devre dışıyken sitenin önizlemesini gerçekleştirmek veya Lynx gibi bir salt metin tarayıcısında siteyi görüntülemektir. Bir siteyi salt metin olarak görüntülemek, resimlere yerleştirilmiş metin gibi Google'ın görmekte zorluk çektiği diğer içeriği tanımlamanıza da yardımcı olur.