瞭解 JavaScript 搜尋引擎最佳化 (SEO) 基礎知識
JavaScript 是構成網路平台的關鍵要素,因為這類指令碼語言提供了多種功能,可將網路轉變成功能強大的應用程式平台。只要讓他人能夠透過 Google 搜尋找到您的 JavaScript 網路應用程式,您就可以在人們搜尋該應用程式提供的內容時發掘新的使用者,並再次吸引現有使用者。雖然 Google 搜尋是透過持續更新的 Chromium 版本執行 JavaScript,您仍可藉由最佳化作業修正部分問題。
本指南將說明 Google 搜尋如何處理 JavaScript,以及針對 Google 搜尋改善 JavaScript 網路應用程式的最佳做法。
Google 如何處理 JavaScript
Google 的 JavaScript 網頁應用程式處理作業分成三個主要階段:
- 檢索
- 轉譯
- 建立索引
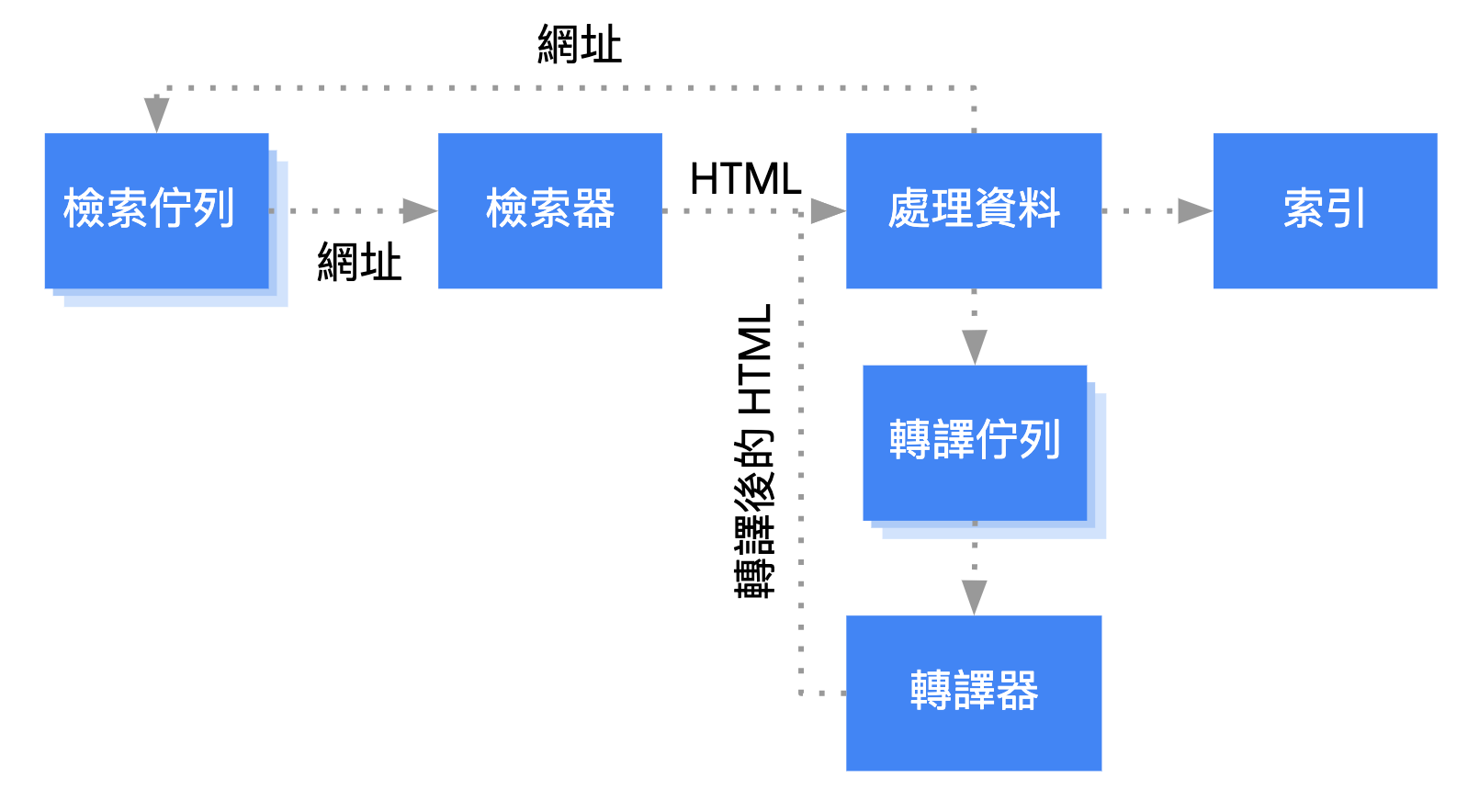
Googlebot 會將網頁排入檢索佇列和轉譯佇列。網頁正在等待檢索及轉譯時,您無法透過任何明確跡象立即得知當下情況。在發出 HTTP 要求來擷取檢索佇列中的網址前,Googlebot 會先確認您是否允許檢索,做法是讀取 robots.txt 檔案。如果 robots.txt 將網址標為不允許檢索,Googlebot 就不會對這個網址發出 HTTP 要求,也不會檢索此網址。Google 搜尋不會從封鎖的檔案或封鎖的網頁中轉譯 JavaScript。
接著,Googlebot 會剖析 HTML 連結 href 屬性中其他網址的回應,並將網址新增至檢索佇列。如要防止 Googlebot 找到特定連結,請採用 nofollow 機制。
在傳統網站或伺服器端轉譯的網頁上,HTTP 回應中的 HTML 會包含所有內容,因此這類網站或網頁相當適合 Googlebot 檢索網址及剖析 HTML 回應。不過,部分 JavaScript 網站可能會採用應用程式命令介面模型,其中的初始 HTML 並未包含實際內容,這時 Google 就必須執行 JavaScript 才能查看這類指令碼語言產生的確切網頁內容。
除非 robots meta 標記或標頭告知 Google 不要建立網頁索引,否則 Googlebot 會將所有提供 200 HTTP 狀態碼的網頁排入轉譯佇列。網頁可能會在這個佇列中停留數秒,但也可能需要更長的時間。在 Google 資源允許的情況下,無頭 Chromium 會轉譯網頁並執行 JavaScript。Googlebot 會再次剖析連結中經過轉譯的 HTML,然後將藉此找到的網址排入檢索佇列。此外,Google 也會利用經過轉譯的 HTML 來建立網頁索引。
請注意,我們依然建議採取伺服器端轉譯或預先轉譯,方便使用者和檢索器更快速地瀏覽網站,況且也不是所有漫遊器都能執行 JavaScript。
使用獨特的標題和摘要來描述網頁
只要提供獨特的描述性 <title> 元素和中繼說明,即可協助使用者迅速找出最符合個人需求的搜尋結果。您可以透過 JavaScript 設定或變更中繼說明和 <title> 元素。
設定標準網址
rel="canonical" 連結標記可協助 Google 找出網頁的標準版本。
您可以使用 JavaScript 設定標準網址,但請注意,您不應使用 JavaScript 將標準網址變更為原始 HTML 中指定的標準網址以外的網址。設定標準網址的最佳方式是使用 HTML,但如果必須使用 JavaScript,請務必將標準網址設為與原始 HTML 相同的值。
如果無法在 HTML 中設定標準網址,可以使用 JavaScript 設定標準網址,並在原始 HTML 中忽略該網址。
編寫相容的程式碼
由於瀏覽器提供的 API 種類繁多,而 JavaScript 又是發展相當快速的語言,因此 Google 對於 API 和 JavaScript 功能的支援會有些限制。為了確保您的程式碼能與 Google 相容,請遵循 JavaScript 問題的疑難排解指南。
如果您透過功能檢測找到自己缺少的所需瀏覽器 API,建議您採用差異化服務和 polyfill。由於部分瀏覽器功能無法支援 pollyfill,我們也建議您參閱 polyfill 說明文件,進一步瞭解可能的相關限制。
使用有意義的 HTTP 狀態碼
Googlebot 會透過 HTTP 狀態碼確認網頁檢索過程中是否發生錯誤。
如要告知 Googlebot 是否該對某個網頁進行檢索或建立索引,請利用有意義的狀態碼;例如透過 404 說明找不到網頁,或藉由 401 提醒 Googlebot 必須登入才能存取網頁。此外,您也可以使用 HTTP 狀態碼告知 Googlebot 網頁是否已移至新網址,以便視情況更新索引。
請參閱這篇文章,查看 HTTP 狀態碼清單以及這些代碼對 Google 搜尋的影響。
避免單頁應用程式出現 soft 404 錯誤
在由用戶端轉譯的單頁應用程式中,轉送通常會以用戶端轉送的形式執行。
在這種情況下,您可能無法使用有意義的 HTTP 狀態碼,或者即使用了也無法運作。
如要避免在使用用戶端轉譯及轉送時發生 soft 404 錯誤,請採取下列其中一項策略:
- 使用 JavaScript 重新導向至伺服器傳回
404HTTP 狀態碼 (例如/not-found) 的網址。 - 使用 JavaScript 將
<meta name="robots" content="noindex">新增至發生錯誤的網頁。
以下是採用重新導向做法的程式碼範例:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. window.location.href = '/not-found'; // redirect to 404 page on the server. } })
以下是採用 noindex 標記做法的程式碼範例:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. // Note: This example assumes there is no other robots meta tag present in the HTML. const metaRobots = document.createElement('meta'); metaRobots.name = 'robots'; metaRobots.content = 'noindex'; document.head.appendChild(metaRobots); } })
使用 History API 而非片段
Google 只能找到 <a> HTML 元素中含有 href 屬性的連結。
對於採行用戶端轉送的單頁應用程式,請使用 History API 在網頁應用程式的不同檢視之間進行轉送。為了確保 Googlebot 能夠剖析並擷取網址,請避免使用片段功能載入不同的網頁內容。 以下為不當做法示例,因為 Googlebot 無法準確解析這些網址:
<nav> <ul> <li><a href="#/products">Our products</a></li> <li><a href="#/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="#/products">our products</a> and <a href="#/services">our services</a></p> </div> <script> window.addEventListener('hashchange', function goToPage() { // this function loads different content based on the current URL fragment const pageToLoad = window.location.hash.slice(1); // URL fragment document.getElementById('placeholder').innerHTML = load(pageToLoad); }); </script>
您可以改為執行 History API,確保 Googlebot 能夠存取連結網址:
<nav> <ul> <li><a href="/products">Our products</a></li> <li><a href="/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="/products">our products</a> and <a href="/services">our services</a></p> </div> <script> function goToPage(event) { event.preventDefault(); // stop the browser from navigating to the destination URL. const hrefUrl = event.target.getAttribute('href'); const pageToLoad = hrefUrl.slice(1); // remove the leading slash document.getElementById('placeholder').innerHTML = load(pageToLoad); window.history.pushState({}, window.title, hrefUrl) // Update URL as well as browser history. } // Enable client-side routing for all links on the page document.querySelectorAll('a').forEach(link => link.addEventListener('click', goToPage)); </script>
正確插入 rel="canonical" 連結標記
雖然我們不建議為此使用 JavaScript,但透過 JavaScript 插入 rel="canonical" 連結標記是可行的。轉譯網頁時,Google 搜尋會挑選所插入的標準網址。以下範例說明如何透過 JavaScript 插入 rel="canonical" 連結標記:
fetch('/api/cats/' + id) .then(function (response) { return response.json(); }) .then(function (cat) { // creates a canonical link tag and dynamically builds the URL // e.g. https://example.com/cats/simba const linkTag = document.createElement('link'); linkTag.setAttribute('rel', 'canonical'); linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName; document.head.appendChild(linkTag); });
請謹慎使用 robots meta 標記
您可以透過 robots meta 標記禁止 Google 為網頁建立索引或追蹤連結。舉例來說,如果您在網頁頂端新增下列 meta 標記,即可禁止 Google 建立網頁索引:
<!-- Google won't index this page or follow links on this page --> <meta name="robots" content="noindex, nofollow">
您可以使用 JavaScript 在網頁上新增 robots meta 標記,或變更標記內容。請參考下列範例程式碼,瞭解如何透過 JavaScript 變更 robots meta 標記,進而在 API 呼叫無法傳回內容的情況下,禁止系統為目前的網頁建立索引。
fetch('/api/products/' + productId) .then(function (response) { return response.json(); }) .then(function (apiResponse) { if (apiResponse.isError) { // get the robotsmetatag var metaRobots = document.querySelector('meta[name="robots"]'); // if there was no robotsmetatag, add one if (!metaRobots) { metaRobots = document.createElement('meta'); metaRobots.setAttribute('name', 'robots'); document.head.appendChild(metaRobots); } // tell Google to exclude this page from the index metaRobots.setAttribute('content', 'noindex'); // display an error message to the user errorMsg.textContent = 'This product is no longer available'; return; } // display product information // ... });
採用長效快取
為了減少網路要求與資源使用,Googlebot 會主動進行快取。在此情況下,WRS 可能會因為忽略快取標頭而使用過時的 JavaScript 或 CSS 資源。如要避免這個問題,您可以建立內容指紋,使其成為檔案名稱的一部分 (例如 main.2bb85551.js)。由於指紋會反映檔案內容,因此只要檔案內容有所更新,系統就會產生一個新檔名。如要瞭解詳情,請參閱 web.dev 長效快取策略指南。
使用結構化資料
在網頁中使用結構化資料時,可以使用 JavaScript 產生所需的 JSON-LD 並將其插入網頁。請務必測試導入作業,以免發生問題。
遵循網頁元件最佳做法
Google 支援網頁元件。 Google 在轉譯網頁時,會壓平 shadow DOM 和 light DOM 的內容。 這表示 Google 只能看到轉譯後的 HTML 可顯示的內容。為確保 Google 在轉譯內容後仍能看到您的內容,請使用複合式搜尋結果測試或網址檢查工具並查看轉譯後的 HTML。
如果內容無法在轉譯後的 HTML 中顯示,則 Google 將無法對其進行索引。
以下範例會建立一個網頁元件,並在元件的 shadow DOM 中顯示它的 light DOM 內容。 如要確保 light DOM 和 shadow DOM 內容都能在轉譯後的 HTML 中顯示,其中一種方法就是使用 Slot 元素。
<script>
class MyComponent extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
let p = document.createElement('p');
p.innerHTML = 'Hello World, this is shadow DOM content. Here comes the light DOM: <slot></slot>';
this.shadowRoot.appendChild(p);
}
}
window.customElements.define('my-component', MyComponent);
</script>
<my-component>
<p>This is light DOM content. It's projected into the shadow DOM.</p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>轉譯完成後,Google 會將這個內容編入索引:
<my-component>
Hello World, this is shadow DOM content. Here comes the light DOM:
<p>This is light DOM content. It's projected into the shadow DOM<p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
修正圖片和延遲載入的內容
載入圖片可能需要占用大量的頻寬,並拖慢執行效能。建議您採用延遲載入的機制,等到使用者快要看到圖片時再載入檔案。為了確保您能以適合搜尋服務的方式導入延遲載入機制,請遵循延遲載入指南。
採用無障礙設計
網頁製作的重心應放在滿足使用者,不要只著眼在搜尋引擎。設計網站時,請考慮使用者的需求,並留意有些使用者可能會使用不支援 JavaScript 的瀏覽器,例如螢幕閱讀器或舊型行動裝置。測試網站無障礙程度最簡單的方法之一,是在預覽前先關閉瀏覽器的 JavaScript 功能,或使用 Lynx 這類純文字瀏覽器來檢視。以純文字來檢視網站也有助於找出 Google 可能難以辨識的其他內容,例如內嵌在圖片中的文字。