ทำความเข้าใจหลักการพื้นฐานของ JavaScript SEO
JavaScript เป็นส่วนสำคัญของแพลตฟอร์มบนเว็บ เนื่องจาก JavaScript มีฟีเจอร์มากมายที่เปลี่ยนเว็บให้เป็นแพลตฟอร์มแอปพลิเคชันที่มีประสิทธิภาพ การทำให้เว็บแอปพลิเคชันที่ทำงานด้วย JavaScript ค้นพบได้ผ่าน Google Search จะช่วยให้คุณพบกับผู้ใช้รายใหม่ และดึงดูดผู้ใช้ที่มีอยู่ให้กลับมาอีกครั้งในขณะที่ผู้ใช้ค้นหาเนื้อหาที่มีอยู่บนเว็บแอปของคุณ แม้ว่า Google Search จะเรียกใช้ JavaScript กับ Chromium เวอร์ชันที่อัปเดตอยู่เสมอ แต่ก็มีบางอย่างที่คุณเพิ่มประสิทธิภาพได้
คู่มือนี้อธิบายวิธีที่ Google Search ประมวลผล JavaScript และแนวทางปฏิบัติแนะนำในการปรับปรุงเว็บแอป JavaScript สำหรับใช้กับ Google Search
วิธีที่ Google ประมวลผล JavaScript
Google ประมวลผลเว็บแอป JavaScript ใน 3 ช่วงหลักๆ ได้แก่
- การรวบรวมข้อมูล
- การแสดงผล
- การจัดทำดัชนี
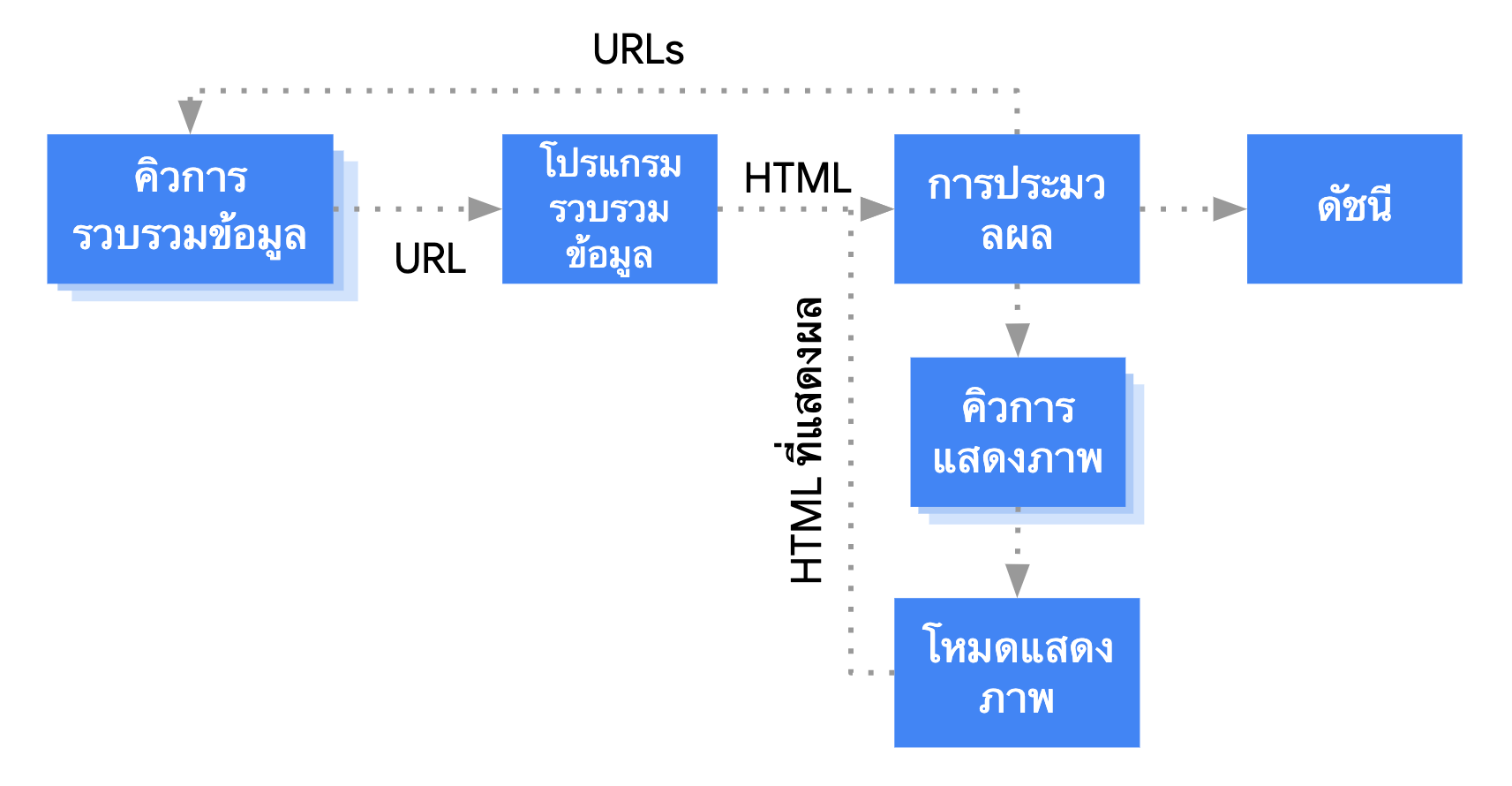
Googlebot จัดคิวหน้าเว็บสำหรับทั้งการรวบรวมข้อมูลและการแสดงผล แต่ยังไม่ทราบชัดเจนทันทีว่าหน้าเว็บจะรอให้มีการ Crawl และการแสดงผลเมื่อใด เมื่อ Googlebot ดึง URL จากคิวการ Crawl ด้วยการสร้างคำขอ HTTP ก็จะตรวจสอบก่อนว่าคุณอนุญาตให้ทำการ Crawl ไหม Googlebot จะอ่านไฟล์ robots.txt หากไฟล์ทำเครื่องหมายว่าไม่อนุญาต URL ใด Googlebot จะข้ามการสร้างคำขอ HTTP ไปยัง URL นั้นและข้าม URL นั้นไป Google Search จะไม่แสดงผล JavaScript จากไฟล์ที่ถูกบล็อกหรือในหน้าที่ถูกบล็อก
จากนั้น Googlebot จะแยกวิเคราะห์การตอบกลับของ URL อื่นๆ ในแอตทริบิวต์ href ของลิงก์ HTML และเพิ่ม URL ในคิวการ Crawl หากไม่ต้องการให้ค้นพบลิงก์ ให้ใช้กลไก nofollow
การ Crawl URL และการแยกวิเคราะห์การตอบกลับ HTML ทำงานได้ดีกับเว็บไซต์แบบดั้งเดิมหรือหน้าเว็บที่แสดงผลฝั่งเซิร์ฟเวอร์ซึ่ง HTML ในการตอบกลับ HTTP มีเนื้อหาทั้งหมด เว็บไซต์ JavaScript บางเว็บอาจใช้รูปแบบ App Shell ซึ่ง HTML เริ่มต้นไม่มีเนื้อหาจริงและ Google ต้องเรียกใช้ JavaScript ก่อนจึงจะดูเนื้อหาจริงของหน้าเว็บที่ JavaScript สร้างได้
Googlebot จัดคิวหน้าเว็บทั้งหมดสำหรับการแสดงผล เว้นแต่ว่าแท็ก meta ของ robots หรือส่วนหัวจะบอกให้ Google ไม่ต้องจัดทำดัชนีหน้าเว็บหนึ่งๆ
หน้าเว็บดังกล่าวจะอยู่ในคิว 2-3 วินาทีหรืออาจนานกว่านั้น เมื่อ Google มีทรัพยากรพร้อม Chromium แบบไม่มีส่วนหัวจะแสดงผลหน้าเว็บและเรียกใช้ JavaScript
จากนั้นจึงแยกวิเคราะห์ HTML ที่แสดงผลสำหรับลิงก์อีกครั้งและจัดคิว URL ที่พบเพื่อ Crawl นอกจากนี้ Google ยังใช้ HTML ที่แสดงผลเพื่อจัดทำดัชนีหน้าเว็บด้วย
โปรดทราบว่าคุณยังควรใช้ฝั่งเซิร์ฟเวอร์หรือการแสดงผลล่วงหน้าอยู่เนื่องจากจะทำให้เว็บไซต์เร็วขึ้นสำหรับผู้ใช้และ Crawler ซึ่งบ็อตบางตัวเรียกใช้ JavaScript ไม่ได้
อธิบายหน้าเว็บโดยใช้ชื่อและตัวอย่างข้อมูลที่ไม่ซ้ำกัน
องค์ประกอบ <title> และคำอธิบายเมตาที่สื่อความหมายและไม่ซ้ำกันช่วยให้ผู้ใช้ทราบผลการค้นหาที่ตรงกับเป้าหมายที่สุดได้อย่างรวดเร็ว
คุณใช้ JavaScript เพื่อตั้งค่าหรือเปลี่ยนคำอธิบายเมตาและองค์ประกอบ <title> ได้
เขียนโค้ดที่เข้ากันได้
เบราว์เซอร์มี API และ JavaScript จำนวนมากที่เป็นภาษาที่พัฒนาขึ้นใหม่อยู่ตลอด Google มีข้อจำกัดบางอย่างเกี่ยวกับฟีเจอร์ของ API และ JavaScript ที่รองรับ โปรดทำตามหลักเกณฑ์การแก้ปัญหา JavaScript เพื่อให้โค้ดของคุณใช้ร่วมกับ Google ได้
เราขอแนะนำให้ใช้ Differential Serving และ Polyfill หากคุณตรวจพบเมื่อใช้ฟีเจอร์ว่าไม่มี API เบราว์เซอร์ที่จำเป็นต้องใช้ และเนื่องจากฟีเจอร์บางอย่างของเบราว์เซอร์ทำ Polyfill ไม่ได้ จึงขอแนะนำให้อ่านเอกสารประกอบเกี่ยวกับ Polyfill เพื่อให้ทราบข้อจำกัดที่อาจมี
ใช้รหัสสถานะ HTTP ที่มีความหมาย
Googlebot ใช้รหัสสถานะ HTTP เพื่อให้ทราบว่าเกิดข้อผิดพลาดเมื่อทำการ Crawl หน้าเว็บหรือไม่
หากต้องการบอก Googlebot หน้าหนึ่งๆ ไม่สามารถทำการ Crawl หรือจัดทําดัชนีหน้าเว็บได้ ให้ใช้รหัสสถานะที่มีความหมาย เช่น 404 กับหน้าเว็บที่ไม่พบ หรือรหัส 401 กับหน้าเว็บที่อยู่หลังการเข้าสู่ระบบ
คุณใช้รหัสสถานะ HTTP เพื่อแจ้ง Googlebot ในกรณีที่หน้าเว็บย้ายไปยัง URL ใหม่ได้ เพื่อให้มีการอัปเดตดัชนีตามนั้น
รายการรหัสสถานะ HTTP และผลต่อ Google Search มีดังนี้
หลีกเลี่ยงข้อผิดพลาด soft 404 ในแอปหน้าเว็บเดียว
ในแอปหน้าเว็บเดียวที่แสดงผลฝั่งไคลเอ็นต์ การกำหนดเส้นทางมักใช้เป็นการกำหนดเส้นทางฝั่งไคลเอ็นต์
ในกรณีนี้ การใช้รหัสสถานะ HTTP ที่มีความหมายอาจไม่เหมาะหรือเป็นไปไม่ได้
เพื่อหลีกเลี่ยงข้อผิดพลาด soft 404 เมื่อใช้การแสดงผลและการกําหนดเส้นทางฝั่งไคลเอ็นต์ ให้ใช้กลยุทธ์ข้อใดข้อหนึ่งต่อไปนี้
- ใช้การเปลี่ยนเส้นทาง JavaScript ไปยัง URL ที่เซิร์ฟเวอร์ตอบสนองด้วยรหัสสถานะ HTTP
404(ตัวอย่างเช่น/not-found) - เพิ่ม
<meta name="robots" content="noindex">ลงในหน้าข้อผิดพลาดโดยใช้ JavaScript
โค้ดตัวอย่างสำหรับการเปลี่ยนเส้นทางมีดังนี้
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. window.location.href = '/not-found'; // redirect to 404 page on the server. } })
โค้ดตัวอย่างสำหรับการใช้แท็ก noindex มีดังนี้
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. // Note: This example assumes there is no other robots meta tag present in the HTML. const metaRobots = document.createElement('meta'); metaRobots.name = 'robots'; metaRobots.content = 'noindex'; document.head.appendChild(metaRobots); } })
ใช้ History API แทน Fragment
Google จะค้นพบลิงก์ได้ก็ต่อเมื่อเป็นองค์ประกอบ HTML <a> ที่มีแอตทริบิวต์ href
สำหรับแอปพลิเคชันหน้าเว็บเดียวที่มีการกำหนดเส้นทางฝั่งไคลเอ็นต์ ให้ใช้ History API เพื่อใช้การกำหนดเส้นทางระหว่างมุมมองต่างๆ ของเว็บแอป และอย่าใช้ Fragment ในการโหลดเนื้อหาต่างๆ ในหน้าเพื่อให้ Googlebot สามารถแยกวิเคราะห์และดึงข้อมูล URL ของคุณได้ ตัวอย่างต่อไปนี้เป็นแนวทางปฏิบัติที่ไม่แนะนำ เนื่องจาก Googlebot จะไม่สามารถจับคู่ข้อมูล URL ได้อย่างถูกต้อง
<nav> <ul> <li><a href="#/products">Our products</a></li> <li><a href="#/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="#/products">our products</a> and <a href="#/services">our services</a></p> </div> <script> window.addEventListener('hashchange', function goToPage() { // this function loads different content based on the current URL fragment const pageToLoad = window.location.hash.slice(1); // URL fragment document.getElementById('placeholder').innerHTML = load(pageToLoad); }); </script>
แต่คุณทำให้ Googlebot เข้าถึง URL ของลิงก์ได้โดยใช้ History API
<nav> <ul> <li><a href="/products">Our products</a></li> <li><a href="/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="/products">our products</a> and <a href="/services">our services</a></p> </div> <script> function goToPage(event) { event.preventDefault(); // stop the browser from navigating to the destination URL. const hrefUrl = event.target.getAttribute('href'); const pageToLoad = hrefUrl.slice(1); // remove the leading slash document.getElementById('placeholder').innerHTML = load(pageToLoad); window.history.pushState({}, window.title, hrefUrl) // Update URL as well as browser history. } // Enable client-side routing for all links on the page document.querySelectorAll('a').forEach(link => link.addEventListener('click', goToPage)); </script>
แทรกแท็กลิงก์ rel="canonical" อย่างเหมาะสม
แม้ว่าเราจะไม่แนะนำให้ใช้ JavaScript ในการนี้ แต่ถ้าจะแทรกแท็กลิงก์ rel="canonical" ด้วย JavaScript ก็สามารถทำได้
Google Search จะเลือก Canonical URL ที่แทรกเข้ามาเมื่อแสดงผลหน้าเว็บ ตัวอย่างการแทรกแท็กลิงก์ rel="canonical" ด้วย JavaScript
fetch('/api/cats/' + id) .then(function (response) { return response.json(); }) .then(function (cat) { // creates a canonical link tag and dynamically builds the URL // e.g. https://example.com/cats/simba const linkTag = document.createElement('link'); linkTag.setAttribute('rel', 'canonical'); linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName; document.head.appendChild(linkTag); });
ใช้แท็ก meta ของ robots อย่างระมัดระวัง
คุณสามารถป้องกันไม่ให้ Google จัดทําดัชนีหน้าเว็บหรือติดตามลิงก์ผ่านแท็ก meta ของ robots
ตัวอย่างเช่น การเพิ่มแท็ก meta ต่อไปนี้ไว้ที่ด้านบนของหน้าจะบล็อก Google ไม่ให้จัดทำดัชนีหน้า
<!-- Google won't index this page or follow links on this page --> <meta name="robots" content="noindex, nofollow">
คุณสามารถใช้ JavaScript เพื่อเพิ่มแท็ก meta ของ robots ลงในหน้าเว็บหรือเปลี่ยนเนื้อหาได้
โค้ดตัวอย่างต่อไปนี้แสดงวิธีเปลี่ยนแท็ก meta ของ robots ด้วย JavaScript เพื่อป้องกันการจัดทำดัชนีของหน้าปัจจุบันหากการเรียก API ไม่แสดงเนื้อหา
fetch('/api/products/' + productId) .then(function (response) { return response.json(); }) .then(function (apiResponse) { if (apiResponse.isError) { // get the robotsmetatag var metaRobots = document.querySelector('meta[name="robots"]'); // if there was no robotsmetatag, add one if (!metaRobots) { metaRobots = document.createElement('meta'); metaRobots.setAttribute('name', 'robots'); document.head.appendChild(metaRobots); } // tell Google to exclude this page from the index metaRobots.setAttribute('content', 'noindex'); // display an error message to the user errorMsg.textContent = 'This product is no longer available'; return; } // display product information // ... });
เมื่อ Google พบ noindex ในแท็ก meta ของ robots ก่อนเรียกใช้ JavaScript ก็จะไม่มีการแสดงผลหรือจัดทำดัชนีหน้าเว็บ
ใช้การแคชเป็นระยะเวลานาน
Googlebot จะแคชทุกอย่างเพื่อลดคำขอของเครือข่ายและการใช้ทรัพยากร WRS อาจไม่สนใจส่วนหัวของแคช จึงอาจทำให้ใช้ทรัพยากร JavaScript หรือ CSS ที่ล้าสมัย
การทำฟิงเกอร์ปรินต์ของเนื้อหาจะหลีกเลี่ยงปัญหานี้โดยสร้างฟิงเกอร์ปรินต์จากส่วนเนื้อหาของชื่อไฟล์ เช่น main.2bb85551.js
เนื่องจากฟิงเกอร์ปรินต์ขึ้นอยู่กับเนื้อหาของไฟล์ การอัปเดตแต่ละครั้งจึงสร้างชื่อไฟล์ที่แตกต่างกัน
ดูข้อมูลเพิ่มเติมได้ที่คำแนะนำจาก web.dev เกี่ยวกับกลยุทธ์การแคชเป็นระยะเวลานาน
ใช้ Structured Data
เมื่อใช้ Structured Data ในหน้า คุณจะใช้ JavaScript เพื่อสร้าง JSON-LD ที่จำเป็นและแทรกลงในหน้านั้นได้ อย่าลืมทดสอบการใช้งานเพื่อหลีกเลี่ยงปัญหา
ทำตามแนวทางปฏิบัติแนะนำสำหรับคอมโพเนนต์เว็บ
Google รองรับคอมโพเนนต์เว็บ เมื่อแสดงผลหน้าเว็บ Google จะรวมเนื้อหา Shadow DOM และ Light DOM เข้าด้วยกัน ซึ่งหมายความว่า Google จะมองเห็นเฉพาะเนื้อหาที่แสดงใน HTML ที่แสดงผล เพื่อให้แน่ใจว่า Google จะยังคงมองเห็นเนื้อหาของคุณหลังจากที่แสดงผลแล้ว โปรดใช้การทดสอบผลการค้นหาที่เป็นริชมีเดียหรือเครื่องมือตรวจสอบ URL และดู HTML ที่แสดงผล
หากเนื้อหาไม่แสดงใน HTML ที่แสดงผล Google จะจัดทำดัชนีเนื้อหาไม่ได้
ตัวอย่างต่อไปนี้สร้างคอมโพเนนต์เว็บที่แสดงเนื้อหา Light DOM ภายใน Shadow DOM วิธีหนึ่งที่จะทำให้ทั้งเนื้อหา Light DOM และ Shadow DOM แสดงใน HTML ที่แสดงผลคือการใช้เอลิเมนต์สล็อต
<script>
class MyComponent extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
let p = document.createElement('p');
p.innerHTML = 'Hello World, this is shadow DOM content. Here comes the light DOM: <slot></slot>';
this.shadowRoot.appendChild(p);
}
}
window.customElements.define('my-component', MyComponent);
</script>
<my-component>
<p>This is light DOM content. It's projected into the shadow DOM.</p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>หลังจากแสดงผลแล้ว Google จะจัดทําดัชนีเนื้อหานี้ได้
<my-component>
Hello World, this is shadow DOM content. Here comes the light DOM:
<p>This is light DOM content. It's projected into the shadow DOM<p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
แก้ไขรูปภาพและเนื้อหาที่โหลดแบบ Lazy Loading
รูปภาพอาจทำให้ต้องเสียค่าใช้จ่ายค่อนข้างสูงจากการใช้แบนด์วิดท์และเพิ่มประสิทธิภาพ กลยุทธ์ที่ดีคือใช้การโหลดแบบ Lazy Loading เพื่อโหลดรูปภาพเฉพาะเมื่อผู้ใช้กำลังจะได้เห็น โปรดทำตามหลักเกณฑ์ในการโหลดแบบ Lazy Loading เพื่อให้แน่ใจว่าคุณใช้การโหลดแบบนี้โดยไม่ส่งผลต่อการค้นหา
ออกแบบเพื่อความสามารถเข้าถึงได้ง่าย
สร้างหน้าเว็บสำหรับผู้ใช้ ไม่ใช่สำหรับเครื่องมือค้นหาเท่านั้น เมื่อคุณออกแบบเว็บไซต์ ให้นึกถึงความต้องการของผู้ใช้ รวมถึงผู้ที่อาจไม่ได้ใช้เบราว์เซอร์ที่ใช้ JavaScript ได้ (เช่น ผู้ที่ใช้โปรแกรมอ่านหน้าจอหรืออุปกรณ์เคลื่อนที่ขั้นพื้นฐาน) วิธีที่ง่ายที่สุดวิธีหนึ่งในการทดสอบการเข้าถึงพิเศษของเว็บไซต์คือ การแสดงตัวอย่างในเบราว์เซอร์โดยปิดใช้ JavaScript หรือดูในเบราว์เซอร์แบบข้อความอย่างเดียว เช่น Lynx การดูเว็บไซต์แบบข้อความเท่านั้นยังช่วยระบุเนื้อหาอื่นๆ ที่ Google อาจมองเห็นได้ยาก เช่น ข้อความที่ฝังอยู่ในรูปภาพ