Grundlagen von JavaScript-SEO
JavaScript ist ein wichtiger Bestandteil der Webplattform, da es viele Funktionen bietet, die das Web zu einer leistungsstarken Anwendungsplattform machen. Deshalb solltest du deine JavaScript-fähigen Webanwendungen über die Google Suche auffindbar machen. So lassen sich neue Nutzer gewinnen und vorhandene Nutzer erneut ansprechen, wenn sie nach Inhalten suchen, die in deiner Webanwendung verfügbar sind. JavaScript wird in der Google Suche mit einer Evergreen-Version von Chromium ausgeführt, du kannst aber einige Optimierungen vornehmen.
Hier erfährst du, wie JavaScript in der Google Suche verarbeitet wird. Außerdem beschreiben wir Best Practices zur Verbesserung von JavaScript-Webanwendungen für die Google Suche.
Verarbeitung von JavaScript durch Google
Die Verarbeitung von JavaScript-Webanwendungen durch Google durchläuft drei Hauptphasen:
- Crawling
- Rendering
- Indexierung
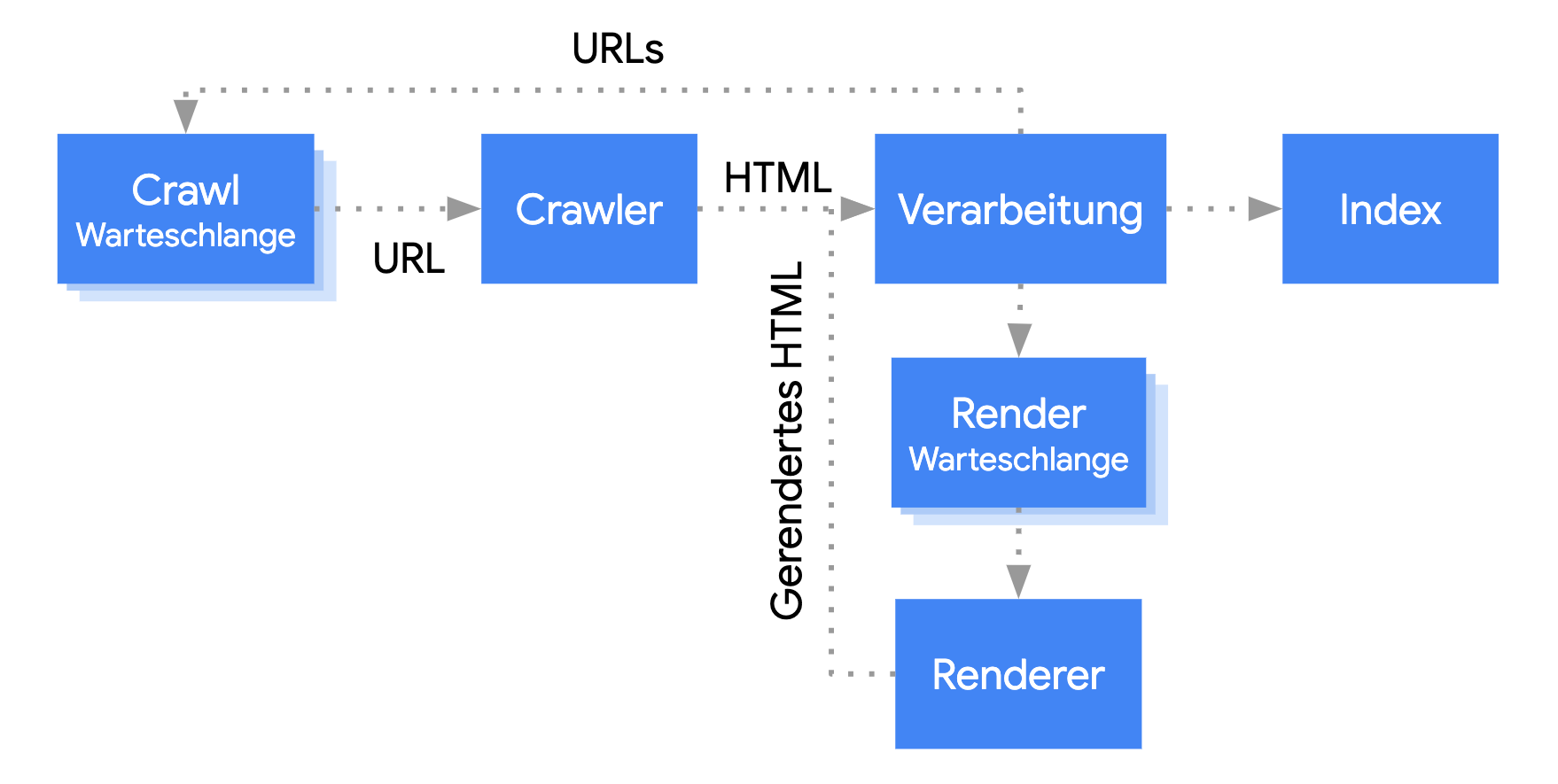
Der Googlebot stellt Seiten sowohl zum Crawlen als auch zum Rendern in die Warteschlange. Es ist nicht sofort ersichtlich, wann eine Seite auf das Crawlen und wann sie auf das Rendern wartet. Wenn der Googlebot mithilfe einer HTTP-Anfrage eine URL aus der Crawling-Warteschlange abruft, überprüft er zuerst, ob sie gecrawlt werden darf. Dazu liest er die robots.txt-Datei. Wenn du die URL dort als unzulässig gekennzeichnet hast, lässt der Googlebot die HTTP-Anfrage für diese URL aus. In der Google Suche wird JavaScript aus blockierten Dateien oder auf blockierten Seiten nicht gerendert.
Anschließend parst der Googlebot die Antwort für andere URLs im href-Attribut von HTML-Links und stellt diese URLs in die Crawling-Warteschlange. Du kannst bei bestimmten Links den nofollow-Mechanismus verwenden, wenn du möchtest, dass der Googlebot diese Links ignoriert.
Das Crawlen einer URL und das Parsen der HTML-Antwort funktioniert gut mit klassischen Websites oder serverseitig gerenderten Seiten, bei denen der HTML-Code in der HTTP-Antwort den gesamten Inhalt enthält. Für einige JavaScript-Websites wird möglicherweise das Anwendungsshell-Modell verwendet, bei dem der ursprüngliche HTML-Code nicht den tatsächlichen Inhalt enthält. Hier muss Google JavaScript ausführen, damit der tatsächliche, von JavaScript generierte Seiteninhalt angezeigt werden kann.
Der Googlebot stellt alle Seiten mit dem HTTP-Statuscode 200 zum Rendern in eine Warteschlange, es sei denn, Google wird über ein robots-meta-Tag oder einen Header angewiesen, eine Seite nicht zu indexieren.
Die Seite verbleibt möglicherweise nur einige Sekunden in dieser Warteschlange, es kann jedoch auch länger dauern. Sobald die Ressourcen von Google dies zulassen, rendert eine monitorlose Variante von Chromium die Seite und führt das JavaScript aus.
Der Googlebot parst den gerenderten HTML-Code noch einmal nach Links und stellt die gefundenen URLs zum Crawlen in die Warteschlange. Außerdem verwendet Google den gerenderten HTML-Code, um die Seite zu indexieren.
Serverseitiges oder Pre-Rendering ist trotzdem eine sehr gute Option, da deine Website dadurch für Nutzer und Crawler schneller wird und nicht alle Bots JavaScript ausführen können.
Seiten mit aussagekräftigen Titeln und Snippets beschreiben
Wenn du deiner Seite eindeutige, aussagekräftige <title>-Elemente und Meta-Beschreibungen hinzufügst, können Nutzer schnell die gewünschten Inhalte finden.
Um die Meta-Beschreibung und das <title>-Element festzulegen oder zu ändern, kannst du JavaScript verwenden.
Kanonische URL festlegen
Mit dem rel="canonical"-Link-Tag kann Google die kanonische Version einer Seite finden.
Du kannst JavaScript verwenden, um die kanonische URL festzulegen. Achte jedoch darauf, dass du die kanonische URL nicht mit JavaScript in eine andere URL als jene änderst, die du im ursprünglichen HTML-Code als kanonische URL angegeben hast.
Die kanonische URL lässt sich am besten mit HTML festlegen. Wenn du jedoch JavaScript verwenden musst, achte darauf, dass du die kanonische URL immer auf denselben Wert wie im ursprünglichen HTML-Code festlegst.
Wenn du die kanonische URL nicht im HTML-Code festlegen kannst, kannst du JavaScript verwenden, um die kanonische URL festzulegen, und sie aus dem ursprünglichen HTML-Code entfernen.
Kompatiblen Code schreiben
Browser bieten viele APIs und auch JavaScript als Sprache entwickelt und verändert sich rasch. Google unterstützt nicht alle APIs und JavaScript-Funktionen. Du solltest erst einmal sicherstellen, dass dein Code mit Google kompatibel ist. Dazu führst du am besten unsere Anleitung zur Fehlerbehebung bei JavaScript-Problemen aus.
Wir empfehlen die Verwendung von Differential Serving und Polyfills, wenn du eine fehlende Browser-API findest, die du brauchst. Einige Browserfunktionen können nicht durch Polyfills nachgerüstet werden. Daher solltest du dich in der Polyfill-Dokumentation über mögliche Einschränkungen informieren.
Aussagekräftige HTTP-Statuscodes verwenden
Mithilfe von HTTP-Statuscodes ermittelt der Googlebot, ob beim Crawlen der Seite ein Fehler aufgetreten ist.
Verwende einen aussagekräftigen Statuscode, um dem Googlebot mitzuteilen, ob eine Seite nicht gecrawlt oder indexiert werden soll, z. B. 404 für eine Seite, die nicht gefunden wurde, oder 401 für Seiten, die sich hinter einer Anmeldung befinden.
Mithilfe von HTTP-Statuscodes kannst du dem Googlebot auch mitteilen, ob sich die URL einer Seite geändert hat, sodass der Index entsprechend aktualisiert werden kann.
Hier findest du eine Liste der HTTP-Statuscodes und ihre Auswirkungen auf die Google Suche.
soft 404-Fehler in Single-Page-Apps vermeiden
Bei clientseitig gerenderten Single-Page-Apps (die nur aus einem einzigen HTML-Dokument bestehen) wird das Routing häufig als clientseitiges Routing implementiert.
In diesem Fall ist die Verwendung aussagekräftiger HTTP-Statuscodes unter Umständen nicht möglich oder unpraktisch.
Mit den folgenden Strategien vermeidest du Fehler vom Typ soft 404 beim clientseitigen Rendering und Routing:
- Verwende eine JavaScript-Weiterleitung zu einer URL, auf die der Server mit einem HTTP-Statuscode
404(z. B./not-found) antwortet. - Füge
<meta name="robots" content="noindex">mithilfe von JavaScript zu Fehlerseiten hinzu.
Beispielcode für die Weiterleitung:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. window.location.href = '/not-found'; // redirect to 404 page on the server. } })
Beispielcode für den noindex-Tag-Ansatz:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. // Note: This example assumes there is no other robots meta tag present in the HTML. const metaRobots = document.createElement('meta'); metaRobots.name = 'robots'; metaRobots.content = 'noindex'; document.head.appendChild(metaRobots); } })
History API anstelle von Fragmenten verwenden
Google kann deine Links nur finden, wenn es sich um <a>-HTML-Elemente mit einem href-Attribut handelt.
Verwende für Single-Page-Anwendungen mit clientseitigem Routing die History API, um das Routing zwischen verschiedenen Ansichten deiner Webanwendung zu implementieren. Damit der Googlebot deine URLs parsen und extrahieren kann, solltest du zum Laden von anderen Seiteninhalten keine Fragmente verwenden. Das folgende Beispiel ist nicht sinnvoll, da der Googlebot die URLs nicht zuverlässig auflösen kann:
<nav> <ul> <li><a href="#/products">Our products</a></li> <li><a href="#/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="#/products">our products</a> and <a href="#/services">our services</a></p> </div> <script> window.addEventListener('hashchange', function goToPage() { // this function loads different content based on the current URL fragment const pageToLoad = window.location.hash.slice(1); // URL fragment document.getElementById('placeholder').innerHTML = load(pageToLoad); }); </script>
Stattdessen solltest du sicherstellen, dass deine URLs für den Googlebot zugänglich sind, indem du die History API implementierst:
<nav> <ul> <li><a href="/products">Our products</a></li> <li><a href="/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="/products">our products</a> and <a href="/services">our services</a></p> </div> <script> function goToPage(event) { event.preventDefault(); // stop the browser from navigating to the destination URL. const hrefUrl = event.target.getAttribute('href'); const pageToLoad = hrefUrl.slice(1); // remove the leading slash document.getElementById('placeholder').innerHTML = load(pageToLoad); window.history.pushState({}, window.title, hrefUrl) // Update URL as well as browser history. } // Enable client-side routing for all links on the page document.querySelectorAll('a').forEach(link => link.addEventListener('click', goToPage)); </script>
rel="canonical"-Link-Tag richtig einfügen
Auch wenn wir davon abraten: Es ist möglich, JavaScript zu verwenden, um ein rel="canonical"-Link-Tag einzuschleusen.
Die Google Suche erkennt beim Rendern der Seite die eingeschleuste kanonische URL. Hier ein Beispiel für das Einschleusen eines rel="canonical"-Link-Tags mit JavaScript:
fetch('/api/cats/' + id) .then(function (response) { return response.json(); }) .then(function (cat) { // creates a canonical link tag and dynamically builds the URL // e.g. https://example.com/cats/simba const linkTag = document.createElement('link'); linkTag.setAttribute('rel', 'canonical'); linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName; document.head.appendChild(linkTag); });
robots-meta-Tags mit Bedacht verwenden
Mit dem robots-meta-Tag kannst du verhindern, dass Google eine Seite indexiert oder Links folgt.
Wenn du beispielsweise das folgende meta-Tag oben auf deiner Seite einfügst, kann Google die Seite nicht indexieren:
<!-- Google won't index this page or follow links on this page --> <meta name="robots" content="noindex, nofollow">
Du kannst JavaScript verwenden, um einer Seite ein robots-meta-Tag hinzuzufügen oder den Wert eines solchen Tags zu ändern.
Der folgende Beispielcode zeigt, wie du das robots-meta-Tag mit JavaScript so änderst, dass die Indexierung der aktuellen Seite verhindert wird, wenn ein API-Aufruf keinen Inhalt zurückgibt.
fetch('/api/products/' + productId) .then(function (response) { return response.json(); }) .then(function (apiResponse) { if (apiResponse.isError) { // get the robotsmetatag var metaRobots = document.querySelector('meta[name="robots"]'); // if there was no robotsmetatag, add one if (!metaRobots) { metaRobots = document.createElement('meta'); metaRobots.setAttribute('name', 'robots'); document.head.appendChild(metaRobots); } // tell Google to exclude this page from the index metaRobots.setAttribute('content', 'noindex'); // display an error message to the user errorMsg.textContent = 'This product is no longer available'; return; } // display product information // ... });
Langlebiges Caching verwenden
Der Googlebot speichert offensiv im Cache, um Netzwerkanfragen und Ressourcennutzung zu reduzieren. Der WRS ignoriert Caching-Header möglicherweise. Dies kann dazu führen, dass der WRS veraltete JavaScript- oder CSS-Ressourcen verwendet.
Durch Inhalts-Fingerabdrücke wird dieses Problem vermieden, da ein Fingerabdruck des Inhalts Teil des Dateinamens wird, z. B. main.2bb85551.js.
Der Fingerabdruck hängt vom Inhalt der Datei ab, sodass bei Aktualisierungen jedes Mal ein anderer Dateiname generiert wird.
Weitere Informationen findest du im web.dev-Leitfaden zu Strategien für langlebiges Caching.
Strukturierte Daten verwenden
Wenn du auf deinen Seiten strukturierte Daten nutzt, kannst du JavaScript verwenden, um das erforderliche JSON-LD zu generieren und in die Seite einzufügen. Teste deine Implementierung, um Probleme zu vermeiden.
Best Practices für Webkomponenten beachten
Google unterstützt Webkomponenten. Wenn Google eine Seite rendert, werden Shadow DOM- und Light DOM-Inhalte zusammengefasst. Das bedeutet, dass Google nur Inhalte sehen kann, die im gerenderten HTML-Code sichtbar sind. Damit du sichergehen kannst, dass Google deine Inhalte nach dem Rendering noch sehen kann, verwende den Test für Rich-Suchergebnisse oder das URL-Prüftool und sieh dir den gerenderten HTML-Code an.
Wenn der Inhalt im gerenderten HTML-Code nicht sichtbar ist, kann Google ihn nicht indexieren.
Im folgenden Beispiel wird eine Webkomponente erstellt, bei der die Light-DOM-Inhalte innerhalb des Shadow DOM angezeigt werden. Eine Möglichkeit, dafür zu sorgen, dass sowohl die Light-DOM- als auch die Shadow-DOM-Inhalte im gerenderten HTML-Code angezeigt werden, ist die Verwendung eines Slot-Elements.
<script>
class MyComponent extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
let p = document.createElement('p');
p.innerHTML = 'Hello World, this is shadow DOM content. Here comes the light DOM: <slot></slot>';
this.shadowRoot.appendChild(p);
}
}
window.customElements.define('my-component', MyComponent);
</script>
<my-component>
<p>This is light DOM content. It's projected into the shadow DOM.</p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>Nach dem Rendern kann Google diese Inhalte indexieren:
<my-component>
Hello World, this is shadow DOM content. Here comes the light DOM:
<p>This is light DOM content. It's projected into the shadow DOM<p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
Probleme mit Bildern und Lazy-Load-Inhalten beheben
Bilder können in Bezug auf Bandbreite und Leistung sehr aufwendig sein. Mit Lazy Loading werden Bilder erst dann geladen, wenn sie den Darstellungsbereich erreichen. Wenn du Lazy Loading einsetzen möchtest, empfehlen wir dir unsere Hinweise zur suchmaschinenfreundlichen Implementierung.