
גיליונות מקושרים מאפשרים לכם לנתח פטה-בייט של נתונים ישירות ב-Google Sheets. אתם יכולים לקשר את הגיליונות האלקטרוניים שלכם למחסן נתונים של BigQuery או ל-Looker ולבצע את הניתוח באמצעות כלים מוכרים של Sheets, כמו טבלאות צירים, תרשימים ונוסחאות.
ניהול מקור נתונים ב-BigQuery
בקטע הזה נשתמש במערך הנתונים הציבורי של BigQuery Shakespeare כדי להראות איך משתמשים בגיליונות אלקטרוניים מקושרים. מערך הנתונים
כולל את הפרטים הבאים:
| שדה | סוג | תיאור |
|---|---|---|
| מילים | STRING |
מילה ייחודית אחת (כאשר הרווח הלבן הוא התו שמפריד בין המילים) שחולצה ממאגר מידע. |
| word_count | INTEGER |
מספר הפעמים שהמילה הזו מופיעה במאגר הזה. |
| קורפוס | STRING |
היצירה שממנה נלקחה המילה. |
| corpus_date | INTEGER |
השנה שבה מאגר הטקסטים הזה פורסם. |
אם האפליקציה שלכם מבקשת נתונים מגיליונות מקושרים של BigQuery, היא צריכה לספק טוקן OAuth 2.0 שמעניק הרשאת גישה בהיקף bigquery.readonly, בנוסף להיקפי ההרשאות האחרים שנדרשים לבקשת Google Sheets API רגילה. מידע נוסף זמין במאמר בנושא בחירת היקפי גישה ל-Google Sheets API.
מקור נתונים מציין מיקום חיצוני שבו נמצאים הנתונים. מקור הנתונים יקושר לגיליון האלקטרוני.
הוספת מקור נתונים של BigQuery
כדי להוסיף מקור נתונים, צריך לספק AddDataSourceRequest באמצעות השיטה spreadsheets.batchUpdate. גוף הבקשה צריך לכלול את השדה dataSource מסוג
DataSource
object.
"addDataSource":{
"dataSource":{
"spec":{
"bigQuery":{
"projectId":"PROJECT_ID",
"tableSpec":{
"tableProjectId":"bigquery-public-data",
"datasetId":"samples",
"tableId":"shakespeare"
}
}
}
}
}
מחליפים את PROJECT_ID במזהה פרויקט תקין ב-Google Cloud.
אחרי שיוצרים מקור נתונים, נוצר גיליון משויך
DATA_SOURCE
כדי לספק תצוגה מקדימה של עד 500 שורות. התצוגה המקדימה לא זמינה באופן מיידי. הפעלה מופעלת באופן אסינכרוני כדי לייבא את הנתונים מ-BigQuery.
השדות הבאים מופיעים ב-AddDataSourceResponse:
dataSource: האובייקט שנוצרDataSource. dataSourceIdהוא מזהה ייחודי ברמת הגיליון האלקטרוני. הוא מאוכלס ומופנה כדי ליצור כל אובייקטDataSourceממקור הנתונים.
dataExecutionStatus: הסטטוס של הרצה שמייבאת נתונים מ-BigQuery לגיליון התצוגה המקדימה. מידע נוסף זמין בקטע סטטוס של הרצת נתונים.
עדכון או מחיקה של מקור נתונים ב-BigQuery
משתמשים בשיטה spreadsheets.batchUpdate ומספקים בקשת UpdateDataSourceRequest או DeleteDataSourceRequest בהתאם.
ניהול אובייקטים של מקורות נתונים ב-BigQuery
אחרי שמוסיפים מקור נתונים לגיליון האלקטרוני, אפשר ליצור ממנו אובייקט של מקור נתונים. אובייקט של מקור נתונים הוא כלי רגיל של Sheets, כמו טבלאות צירים, תרשימים ונוסחאות, שמשולב עם Connected Sheets כדי להפעיל את ניתוח הנתונים.
יש ארבעה סוגים של אובייקטים:
- טבלה של
DataSource DataSourcepivotTable- תרשים של
DataSource - נוסחה של
DataSource
הוספת טבלה של מקור נתונים ב-BigQuery
אובייקט הטבלה, שנקרא 'חילוץ' בעורך של Sheets, מייבא ל-Sheets נתונים סטטיים ממקור הנתונים. בדומה לטבלת צירים, הטבלה מוגדרת ומעוגנת לתא הימני העליון.
בדוגמת הקוד הבאה מוצג שימוש בשיטה spreadsheets.batchUpdate וב-UpdateCellsRequest כדי ליצור טבלה של מקור נתונים עם עד 1,000 שורות ושתי עמודות (word ו-word_count).
"updateCells":{
"rows":{
"values":[
{
"dataSourceTable":{
"dataSourceId":"DATA_SOURCE_ID",
"columns":[
{
"name":"word"
},
{
"name":"word_count"
}
],
"rowLimit":{
"value":1000
},
"columnSelectionType":"SELECTED"
}
}
]
},
"fields":"dataSourceTable"
}
מחליפים את DATA_SOURCE_ID במזהה ייחודי בהיקף הגיליון האלקטרוני שמזהה את מקור הנתונים.
אחרי שיוצרים טבלה של מקור נתונים, הנתונים לא זמינים באופן מיידי. בכלי לעריכת גיליונות אלקטרוניים של Sheets, היא מוצגת כתצוגה מקדימה. כדי לאחזר את הנתונים מ-BigQuery, צריך לרענן את הטבלה של מקור הנתונים. אפשר לציין RefreshDataSourceRequest באותו batchUpdate. חשוב לזכור שכל האובייקטים במקור הנתונים פועלים באופן דומה.
מידע נוסף זמין במאמר רענון אובייקט של מקור נתונים.
אחרי שהרענון מסתיים והנתונים מ-BigQuery נשלפים, הטבלה של מקור הנתונים מתמלאת כמו שמוצג:

הוספת טבלת ציר ממקור נתונים ב-BigQuery
בניגוד לטבלת צירים רגילה, טבלת צירים של מקור נתונים מגובה על ידי מקור נתונים, והיא מפנה לנתונים לפי שם העמודה. בדוגמת הקוד הבאה מוצג אופן השימוש בשיטה spreadsheets.batchUpdate וב-UpdateCellsRequest כדי ליצור טבלת ציר שמציגה את מספר המילים הכולל לפי מאגר.
"updateCells":{
"rows":{
"values":[
{
"pivotTable":{
"dataSourceId":"DATA_SOURCE_ID",
"rows":{
"dataSourceColumnReference":{
"name":"corpus"
},
"sortOrder":"ASCENDING"
},
"values":{
"summarizeFunction":"SUM",
"dataSourceColumnReference":{
"name":"word_count"
}
}
}
}
]
},
"fields":"pivotTable"
}
מחליפים את DATA_SOURCE_ID במזהה ייחודי בהיקף הגיליון האלקטרוני שמזהה את מקור הנתונים.
אחרי שנתוני BigQuery נשלפים, טבלת הצירים של מקור הנתונים מתמלאת כמו שמוצג כאן:
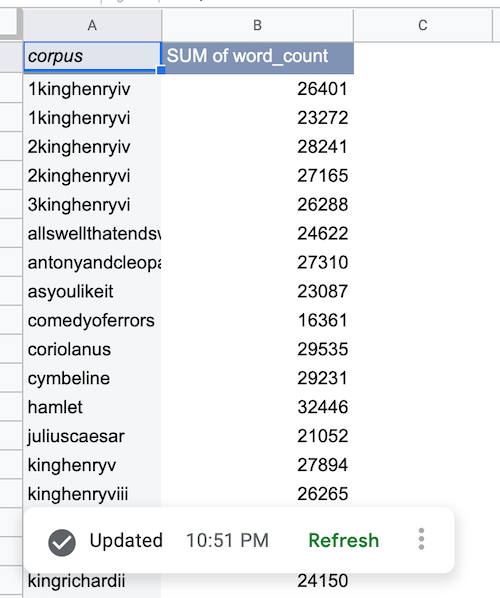
הוספת תרשים של מקור נתונים ב-BigQuery
בדוגמת הקוד הבאה מוצג שימוש בשיטה spreadsheets.batchUpdate וב-AddChartRequest כדי ליצור תרשים של מקור נתונים עם chartType של COLUMN, שבו מוצג מספר המילים הכולל לפי קורפוס.
"addChart":{
"chart":{
"spec":{
"title":"Corpus by word count",
"basicChart":{
"chartType":"COLUMN",
"domains":[
{
"domain":{
"columnReference":{
"name":"corpus"
}
}
}
],
"series":[
{
"series":{
"columnReference":{
"name":"word_count"
},
"aggregateType":"SUM"
}
}
]
}
},
"dataSourceChartProperties":{
"dataSourceId":"DATA_SOURCE_ID"
}
}
}
מחליפים את DATA_SOURCE_ID במזהה ייחודי בהיקף הגיליון האלקטרוני שמזהה את מקור הנתונים.
אחרי שנתוני BigQuery נשלפים, התרשים של מקור הנתונים מוצג כך:
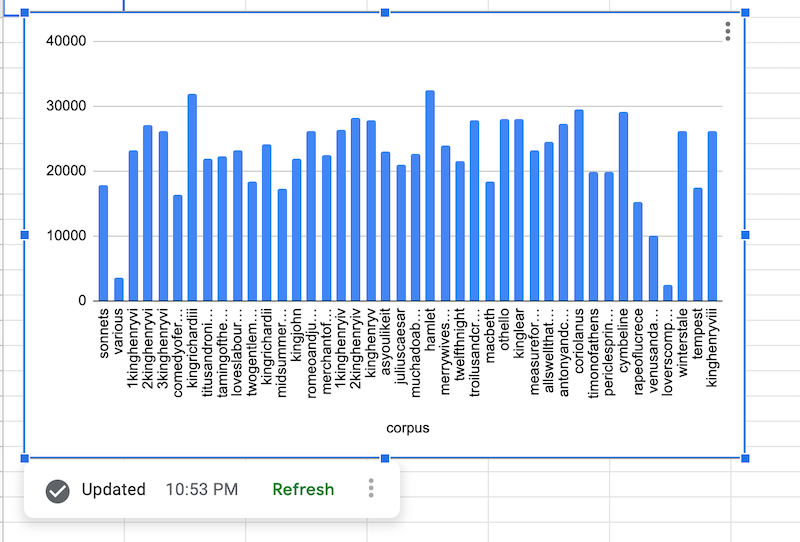
הוספת נוסחה של מקור נתונים ב-BigQuery
בדוגמת הקוד הבאה מוצג אופן השימוש בשיטה spreadsheets.batchUpdate וב-UpdateCellsRequest כדי ליצור נוסחה למקור נתונים לחישוב מספר המילים הממוצע.
"updateCells":{
"rows":[
{
"values":[
{
"userEnteredValue":{
"formulaValue":"=AVERAGE(shakespeare!word_count)"
}
}
]
}
],
"fields":"userEnteredValue"
}
אחרי ששולפים את הנתונים מ-BigQuery, הנוסחה של מקור הנתונים מתמלאת כמו שמוצג:
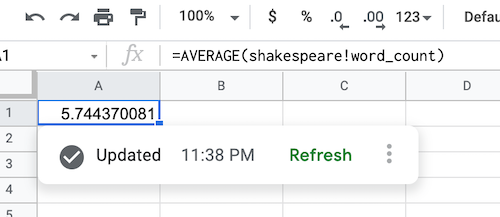
רענון אובייקט במקור נתונים של BigQuery
אתם יכולים לרענן אובייקט של מקור נתונים כדי לאחזר את הנתונים האחרונים מ-BigQuery על סמך המפרטים הנוכחיים של מקור הנתונים וההגדרות של האובייקט. אפשר להשתמש בשיטה spreadsheets.batchUpdate כדי להפעיל את RefreshDataSourceRequest.
לאחר מכן מציינים הפניה לאובייקט אחד או יותר לרענון באמצעות האובייקט DataSourceObjectReferences.
שימו לב שאפשר גם ליצור וגם לרענן אובייקטים של מקור נתונים בבקשת batchUpdate אחת.
ניהול מקור נתונים ב-Looker
במדריך הזה נסביר איך להוסיף מקור נתונים של Looker, לעדכן או למחוק אותו, ליצור בו טבלת ציר ולרענן אותו.
הבקשה שלכם לגישה לנתונים ב-Looker Connected Sheets תשתמש מחדש בקישור הקיים של חשבון Google ל-Looker.
הוספת מקור נתונים של Looker
כדי להוסיף מקור נתונים, צריך לספק AddDataSourceRequest באמצעות השיטה spreadsheets.batchUpdate. גוף הבקשה צריך לכלול שדה dataSource מסוג
DataSource
object.
"addDataSource":{
"dataSource":{
"spec":{
"looker":{
"instance_uri":"INSTANCE_URI",
"model":"MODEL",
"explore":"EXPLORE"
}
}
}
}
מחליפים את INSTANCE_URI, MODEL ו-EXPLORE במזהה משאבים אחיד (URI) תקין של מופע Looker, בשם המודל ובשם הניתוח בהתאמה.
אחרי שיוצרים מקור נתונים, נוצר גיליון DATA_SOURCE משויך כדי לספק תצוגה מקדימה של המבנה של הניתוח שנבחר, כולל תצוגות, מאפיינים, מדדים ותיאורים של שדות.
האובייקט
AddDataSourceResponse
כולל את השדות הבאים:
dataSource: האובייקט שנוצרDataSource. dataSourceIdהוא מזהה ייחודי שמוגבל לגיליון האלקטרוני. הוא מאוכלס ומשמש כהפניה ליצירת כל אובייקטDataSourceממקור הנתונים.
dataExecutionStatus: הסטטוס של הרצה שמייבאת נתונים מ-BigQuery לגיליון התצוגה המקדימה. מידע נוסף זמין בקטע סטטוס של הרצת נתונים.
עדכון או מחיקה של מקור נתונים ב-Looker
משתמשים בשיטה
spreadsheets.batchUpdate
ומספקים בקשת
UpdateDataSourceRequest
או
DeleteDataSourceRequest
בהתאם.
ניהול אובייקטים במקור נתונים ב-Looker
אחרי שמוסיפים גיליון אלקטרוני כמקור נתונים, אפשר ליצור ממנו אובייקט של מקור נתונים. במקורות נתונים של Looker, אפשר ליצור רק אובייקט DataSource
pivotTable.
אי אפשר ליצור DataSource נוסחאות, תמציות ותרשימים ממקורות נתונים של Looker.
רענון אובייקט במקור נתונים של Looker
אתם יכולים לרענן אובייקט של מקור נתונים כדי לאחזר את הנתונים העדכניים מ-Looker על סמך המפרטים הנוכחיים של מקור הנתונים וההגדרות של האובייקט. אתם יכולים להשתמש בשיטה spreadsheets.batchUpdate כדי להפעיל את RefreshDataSourceRequest.
לאחר מכן מציינים הפניה לאובייקט אחד או יותר לרענון באמצעות האובייקט DataSourceObjectReferences.
שימו לב שאפשר גם ליצור וגם לרענן אובייקטים של מקור נתונים בבקשת batchUpdate אחת.
סטטוס הביצוע של הנתונים
כשיוצרים מקורות נתונים או מרעננים אובייקטים של מקורות נתונים, נוצרת הרצה ברקע כדי לאחזר את הנתונים מ-BigQuery או מ-Looker ולהחזיר תגובה שמכילה את DataExecutionStatus.
אם הביצוע מתחיל בהצלחה, בדרך כלל DataExecutionState נמצא במצב RUNNING.
התהליך הוא אסינכרוני, ולכן האפליקציה צריכה להטמיע מודל של שליחת בקשות חוזרות כדי לאחזר מעת לעת את הסטטוס של אובייקטים של מקורות נתונים. משתמשים בשיטה spreadsheets.get עד שהסטטוס מחזיר את המצב SUCCEEDED או FAILED.
ברוב המקרים, הביצוע מסתיים במהירות, אבל הוא תלוי במורכבות של מקור הנתונים. בדרך כלל, משך ההפעלה לא עולה על 10 דקות.
נושאים קשורים
- בחירת היקפי הרשאות של Google Sheets API
- איך מתחילים לעבוד עם נתוני BigQuery ב-Google Sheets
- מסמכי BigQuery
- BigQuery: שימוש בגיליונות מקושרים
- סרטון הדרכה על גיליונות מקושרים
- שימוש בגיליונות מקושרים ל-Looker
- מבוא ל-Looker