Google의 AlphaEarth Foundations는 다양한 지구 관측 (EO) 데이터 세트로 학습된 지리 공간 임베딩 모델입니다. 이 모델은 연간 이미지 시계열에서 실행되었으며 결과 임베딩은 Earth Engine에서 분석 준비 데이터 세트로 사용할 수 있습니다. 이 데이터 세트를 사용하면 사용자가 컴퓨팅 비용이 많이 드는 딥 러닝 모델을 실행하지 않고도 원하는 수의 미세 조정 애플리케이션이나 기타 작업을 빌드할 수 있습니다. 그 결과는 다음과 같은 다양한 다운스트림 작업에 사용할 수 있는 범용 데이터 세트입니다.
- 분류
- 회귀
- 변경 감지
- 유사성 검색
이 튜토리얼에서는 임베딩의 작동 방식을 이해하고 위성 임베딩 데이터 세트에 액세스하고 이를 시각화하는 방법을 알아봅니다.
임베딩 이해
임베딩은 많은 양의 정보를 의미 있는 시맨틱을 나타내는 더 작은 특성 세트로 압축하는 방법입니다. AlphaEarth Foundations 모델은 Sentinel-2, Sentinel-1, Landsat을 비롯한 센서의 이미지 시계열을 가져와 64개의 숫자만으로 소스와 타겟 간의 상호 정보를 고유하게 표현하는 방법을 학습합니다 (자세한 내용은 여기에서 확인하세요). 입력 데이터 스트림에는 여러 센서의 이미지 밴드가 수천 개 포함되어 있으며 모델은 이 고차원 입력을 가져와 저차원 표현으로 변환합니다.
AlphaEarth Foundations의 작동 방식을 이해하는 데 도움이 되는 좋은 사고 모델은 주성분 분석 (PCA)이라는 기법입니다. PCA는 머신러닝 애플리케이션의 데이터 차원을 줄이는 데도 도움이 됩니다. PCA는 통계 기법으로 수십 개의 입력 밴드를 몇 개의 주성분으로 압축할 수 있지만, AlphaEarth Foundations는 다중 센서 시계열 데이터 세트의 수천 개의 입력 차원을 가져와 해당 픽셀의 공간적 및 시간적 가변성을 고유하게 포착하는 64밴드 표현을 만드는 방법을 학습할 수 있는 딥 러닝 모델입니다.
학습된 삽입의 연속 배열 또는 '필드'입니다. 임베딩 필드 컬렉션의 이미지는 1년 전체를 포함하는 시공간 궤적을 나타내며 64개의 밴드 (각 임베딩 차원에 하나씩)가 있습니다.
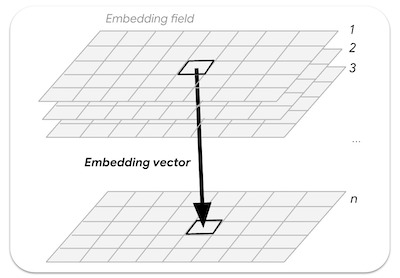
그림: 임베딩 필드에서 샘플링된 n차원 임베딩 벡터
위성 임베딩 데이터 세트에 액세스
위성 삽입 데이터 세트는 2017년 이후의 연간 이미지를 포함하는 이미지 컬렉션입니다 (예: 2017, 2018, 2019…). 각 이미지에는 64개의 밴드가 있으며 각 픽셀은 지정된 연도의 다중 센서 시계열을 나타내는 삽입 벡터입니다.
var embeddings = ee.ImageCollection('GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL');
지역 선택
관심 영역을 정의하는 것부터 시작해 보겠습니다. 이 튜토리얼에서는 인도 크리슈나 라자 사가라 (KRS) 저수지 주변의 지역을 선택하고 다각형을 geometry 변수로 정의합니다. 또는 코드 편집기의 그리기 도구를 사용하여 관심 영역 주위에 다각형을 그릴 수 있습니다. 이 다각형은 가져오기에서 geometry 변수로 저장됩니다.
// Use the satellite basemap
Map.setOptions('SATELLITE');
var geometry = ee.Geometry.Polygon([[
[76.3978, 12.5521],
[76.3978, 12.3550],
[76.6519, 12.3550],
[76.6519, 12.5521]
]]);
Map.centerObject(geometry, 12);
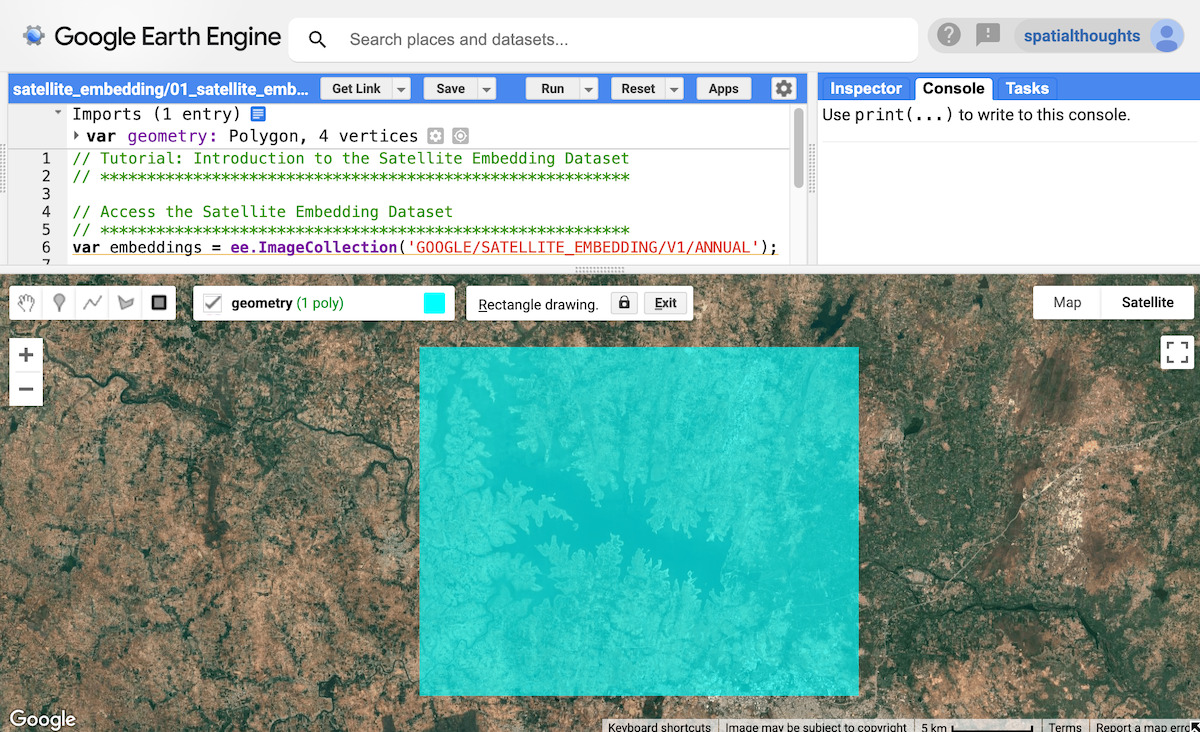
그림: 관심 영역 선택
위성 임베딩 데이터 세트 준비
각 연도의 이미지는 쉽게 액세스할 수 있도록 타일로 분할됩니다. Google에서는 필터를 적용하여 선택한 연도와 지역의 이미지를 찾습니다.
var year = 2024;
var startDate = ee.Date.fromYMD(year, 1, 1);
var endDate = startDate.advance(1, 'year');
var filteredEmbeddings = embeddings
.filter(ee.Filter.date(startDate, endDate))
.filter(ee.Filter.bounds(geometry));
위성 삽입 이미지는 각각 최대 163,840m x 163,840m 크기의 타일로 그리드화되어 타일의 UTM 구역 투영으로 제공됩니다. 그 결과 관심 지역을 포함하는 여러 위성 삽입 타일이 표시됩니다. mosaic() 함수를 사용하여 여러 타일을 단일 이미지로 결합할 수 있습니다. 결과 이미지를 인쇄하여 밴드를 확인해 보겠습니다.
var embeddingsImage = filteredEmbeddings.mosaic();
print('Satellite Embedding Image', embeddingsImage);
이미지에 A00, A01, ..., A63이라는 이름의 64개 밴드가 표시됩니다. 각 밴드에는 해당 측정기준 또는 축의 지정된 연도에 대한 삽입 벡터 값이 포함됩니다. 스펙트럼 밴드나 지수와 달리 개별 밴드는 독립적인 의미가 없습니다. 각 밴드는 삽입 공간의 한 축을 나타냅니다. 64개 밴드를 모두 다운스트림 애플리케이션의 입력으로 사용합니다.

그림: 위성 삽입 이미지의 64개 밴드
위성 임베딩 데이터 세트 시각화
방금 확인한 것처럼 이미지에는 64개의 밴드가 포함되어 있습니다. 한 번에 세 개의 밴드 조합만 볼 수 있으므로 모든 밴드에 포함된 모든 정보를 시각화하는 쉬운 방법은 없습니다.
세 개의 밴드를 선택하여 삽입 공간의 세 축을 RGB 이미지로 시각화할 수 있습니다.
var visParams = {min: -0.3, max: 0.3, bands: ['A01', 'A16', 'A09']};
Map.addLayer(embeddingsImage.clip(geometry), visParams, 'Embeddings Image');

그림: 임베딩 공간의 3개 축의 RGB 시각화
이 정보를 시각화하는 또 다른 방법은 이를 사용하여 임베딩이 유사한 픽셀을 그룹화하고 이러한 그룹화를 사용하여 모델이 풍경의 공간적, 시간적 가변성을 학습한 방식을 이해하는 것입니다.
비지도 클러스터링 기법을 사용하여 64차원 공간의 픽셀을 유사한 값의 그룹 또는 '클러스터'로 그룹화할 수 있습니다. 이를 위해 먼저 일부 픽셀 값을 샘플링하고 ee.Clusterer를 학습시킵니다.
var nSamples = 1000;
var training = embeddingsImage.sample({
region: geometry,
scale: 10,
numPixels: nSamples,
seed: 100
});
print(training.first());
첫 번째 샘플의 값을 출력하면 해당 픽셀의 임베딩 벡터를 정의하는 64개의 밴드 값이 표시됩니다. 임베딩 벡터는 단위 길이를 갖도록 설계되었습니다. 즉, 원점(0,0,....0)에서 벡터 값까지의 벡터 길이가 1입니다.

그림: 추출된 임베딩 벡터
이제 비지도 모델을 학습시켜 원하는 수의 클러스터로 샘플을 그룹화할 수 있습니다. 각 클러스터는 유사한 삽입의 픽셀을 나타냅니다.
// Function to train a model for desired number of clusters
var getClusters = function(nClusters) {
var clusterer = ee.Clusterer.wekaKMeans({nClusters: nClusters})
.train(training);
// Cluster the image
var clustered = embeddingsImage.cluster(clusterer);
return clustered;
};
이제 더 큰 삽입 이미지를 클러스터링하여 삽입이 유사한 픽셀 그룹을 확인할 수 있습니다. 그 전에 모델이 한 해 동안 각 픽셀의 전체 시간적 궤적을 포착했다는 점을 이해하는 것이 중요합니다. 즉, 두 픽셀의 스펙트럼 값이 모든 이미지에서 유사하지만 시간이 다른 경우 분리할 수 있습니다.
아래는 2024년 클라우드 마스크 처리된 Sentinel-2 이미지로 포착한 관심 영역을 시각화한 것입니다. 모든 이미지 (Sentinel-2, Landsat 8/9 및 기타 여러 센서의 이미지 포함)는 최종 임베딩을 학습하는 데 사용되었습니다.

그림: 해당 지역의 Sentinel-2 연간 시계열
지형을 3개의 클러스터로 분할하여 위성 임베딩 이미지를 시각화해 보겠습니다.
var cluster3 = getClusters(3);
Map.addLayer(cluster3.randomVisualizer().clip(geometry), {}, '3 clusters');

그림: 클러스터 3개가 있는 위성 임베딩 이미지
결과 클러스터의 경계가 매우 깔끔한 것을 확인할 수 있습니다. 이는 임베딩에 공간 컨텍스트가 내재되어 있기 때문입니다. 동일한 객체 내의 픽셀은 임베딩 벡터가 비교적 유사할 것으로 예상됩니다. 또한 클러스터 중 하나에는 주요 저수지 주변에 계절성 물이 있는 지역이 포함됩니다. 이는 유사한 시간적 패턴으로 이러한 픽셀을 감지할 수 있는 임베딩 벡터에 포착된 시간적 컨텍스트 때문입니다.
픽셀을 5개의 클러스터로 그룹화하여 클러스터를 더 세분화할 수 있는지 확인해 보겠습니다.
var cluster5 = getClusters(5);
Map.addLayer(cluster5.randomVisualizer().clip(geometry), {}, '5 clusters');

그림: 클러스터 5개가 있는 위성 임베딩 이미지
클러스터 수를 늘려 이미지를 더 전문적인 그룹으로 세분화할 수 있습니다. 클러스터가 10개인 이미지는 다음과 같습니다.
var cluster10 = getClusters(10);
Map.addLayer(cluster10.randomVisualizer().clip(geometry), {}, '10 clusters');

그림: 클러스터 10개가 있는 위성 임베딩 이미지
많은 세부정보가 표시되고 다양한 유형의 작물이 여러 클러스터로 그룹화되는 것을 확인할 수 있습니다. 위성 임베딩은 기후 변수와 함께 작물 생태를 포착하므로 작물 유형 매핑에 적합합니다. 다음 튜토리얼 (비지도 분류)에서는 필드 수준 라벨이 거의 또는 전혀 없는 위성 삽입 데이터로 작물 유형 지도를 만드는 방법을 알아봅니다.