이전 튜토리얼 (소개)에서는 위성 임베딩이 위성 관측 및 기후 변수의 연간 궤적을 포착하는 방법을 살펴봤습니다. 따라서 작물 생육기를 모델링하지 않고도 작물을 매핑하는 데 데이터 세트를 바로 사용할 수 있습니다. 작물 유형 매핑은 일반적으로 작물 생육 단계를 모델링하고 해당 지역에서 재배되는 모든 작물의 현장 샘플을 수집해야 하는 어려운 작업입니다.
이 튜토리얼에서는 필드 라벨에 의존하지 않고 이 복잡한 작업을 실행할 수 있는 비지도 분류 접근 방식을 사용하여 작물 매핑을 진행합니다. 이 방법은 전 세계 여러 지역에서 쉽게 구할 수 있는 집계된 작물 통계와 함께 해당 지역의 현지 지식을 활용합니다.
지역 선택
이 가이드에서는 아이오와주 세로 고르도 카운티의 농작물 유형 지도를 만듭니다. 이 카운티는 옥수수와 콩이라는 두 가지 주요 작물이 있는 미국 옥수수 지대에 있습니다. 이러한 현지 지식은 중요하며 모델의 주요 매개변수를 결정하는 데 도움이 됩니다.
먼저 선택한 카운티의 경계를 가져옵니다.
// Select the region
// Cerro Gordo County, Iowa
var counties = ee.FeatureCollection('TIGER/2018/Counties');
var selected = counties
.filter(ee.Filter.eq('GEOID', '19033'));
var geometry = selected.geometry();
Map.centerObject(geometry, 12);
Map.addLayer(geometry, {color: 'red'}, 'Selected Region', false);

그림: 선택한 지역
위성 임베딩 데이터 세트 준비
다음으로 위성 임베딩 데이터 세트를 로드하고 선택한 연도의 이미지를 필터링하여 모자이크를 만듭니다.
var embeddings = ee.ImageCollection('GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL');
var year = 2022;
var startDate = ee.Date.fromYMD(year, 1, 1);
var endDate = startDate.advance(1, 'year');
var filteredembeddings = embeddings
.filter(ee.Filter.date(startDate, endDate))
.filter(ee.Filter.bounds(geometry));
var embeddingsImage = filteredembeddings.mosaic();
농지 마스크 만들기
모델링을 위해서는 농경지가 아닌 지역을 제외해야 합니다. 작물 마스크를 만드는 데 사용할 수 있는 전역 및 지역 데이터 세트가 많이 있습니다. ESA WorldCover 또는 GFSAD Global Cropland Extent Product는 전 세계 농지 데이터 세트에 적합합니다. 최근에 추가된 제품은 활성 농경지의 계절별 매핑이 포함된 ESA WorldCereal Active Cropland 제품입니다. 리전이 미국이므로 더 정확한 지역 데이터 세트인 USDA NASS Cropland Data Layers (CDL)를 사용하여 작물 마스크를 얻을 수 있습니다.
// Use Cropland Data Layers (CDL) to obtain cultivated cropland
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var croplandMask = cdl.select('cultivated').eq(2).rename('cropmask');
// Visualize the crop mask
var croplandMaskVis = {min: 0, max: 1, palette: ['white', 'green']};
Map.addLayer(croplandMask.clip(geometry), croplandMaskVis, 'Crop Mask');
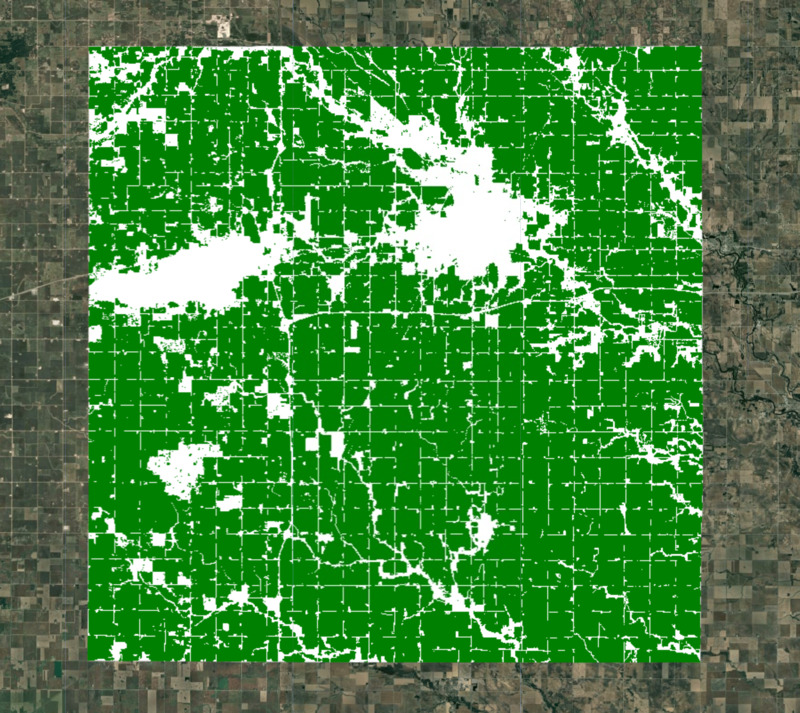
그림: 농지 마스크가 있는 선택된 지역
학습 샘플 추출
농지 마스크를 삽입 모자이크에 적용합니다. 이제 군의 경작지를 나타내는 모든 픽셀이 남았습니다.
// Mask all non-cropland pixels
var clusterImage = embeddingsImage.updateMask(croplandMask);
위성 삽입 이미지를 가져와 클러스터링 모델을 학습시키기 위한 무작위 샘플을 얻어야 합니다. 관심 영역에 마스크 처리된 픽셀이 많이 포함되어 있으므로 간단한 무작위 샘플링을 하면 값이 null인 샘플이 생성될 수 있습니다. 원하는 수의 null이 아닌 샘플을 추출할 수 있도록 계층화된 샘플링을 사용하여 마스킹되지 않은 영역에서 원하는 수의 샘플을 얻습니다.
// Stratified random sampling
var training = clusterImage.addBands(croplandMask).stratifiedSample({
numPoints: 1000,
classBand: 'cropmask',
region: geometry,
scale: 10,
tileScale: 16,
seed: 100,
dropNulls: true,
geometries: true
});
샘플을 애셋으로 내보내기 (선택사항)
샘플 추출은 계산 비용이 많이 드는 작업이므로 추출된 학습 샘플을 애셋으로 내보내고 후속 단계에서 내보낸 애셋을 사용하는 것이 좋습니다. 이렇게 하면 대규모 지역을 사용할 때 계산 시간 초과 또는 사용자 메모리 초과 오류를 해결하는 데 도움이 됩니다.
내보내기 작업을 시작하고 완료될 때까지 기다린 후 계속 진행합니다.
// Replace this with your asset folder
// The folder must exist before exporting
var exportFolder = 'projects/spatialthoughts/assets/satellite_embedding/';
var samplesExportFc = 'cluster_training_samples';
var samplesExportFcPath = exportFolder + samplesExportFc;
Export.table.toAsset({
collection: training,
description: 'Cluster_Training_Samples',
assetId: samplesExportFcPath
});
내보내기 작업이 완료되면 추출된 샘플을 특성 컬렉션으로 코드에 다시 읽어올 수 있습니다.
// Use the exported asset
var training = ee.FeatureCollection(samplesExportFcPath);
샘플 시각화
샘플을 대화형으로 실행했든 피처 컬렉션으로 내보냈든 이제 샘플 포인트가 포함된 학습 변수가 있습니다. 첫 번째 샘플을 출력하여 검사하고 Map에 학습 포인트를 추가해 보겠습니다.
print('Extracted sample', training.first());
Map.addLayer(training, {color: 'blue'}, 'Extracted Samples', false);

그림: 클러스터링을 위해 추출된 무작위 샘플
비지도 클러스터링 실행
이제 클러스터러를 학습시키고 64D 임베딩 벡터를 선택한 수의 개별 클러스터로 그룹화할 수 있습니다. Google의 지역 지식에 따르면 대부분의 지역을 대표하는 두 가지 주요 작물이 있으며 나머지 부분을 차지하는 여러 작물이 있습니다. 위성 삽입에 비지도 클러스터링을 실행하여 시간적 궤적과 패턴이 유사한 픽셀 클러스터를 얻을 수 있습니다. 스펙트럼 및 공간 특성이 유사하고 페놀로지가 유사한 픽셀은 동일한 클러스터로 그룹화됩니다.
ee.Clusterer.wekaCascadeKMeans()를 사용하면 최소 및 최대 클러스터 수를 지정하고 학습 데이터를 기반으로 최적의 클러스터 수를 찾을 수 있습니다. 여기서 최소 및 최대 클러스터 수를 결정하는 데 현지 지식이 유용합니다. 옥수수, 콩, 기타 여러 작물 등 몇 가지 뚜렷한 유형의 클러스터가 있을 것으로 예상되므로 클러스터의 최소 개수를 4로, 최대 개수를 5로 사용할 수 있습니다. 이러한 수치를 실험하여 지역에 가장 적합한 수치를 찾아야 할 수도 있습니다.
// Cluster the Satellite Embedding Image
var minClusters = 4;
var maxClusters = 5;
var clusterer = ee.Clusterer.wekaCascadeKMeans({
minClusters: minClusters, maxClusters: maxClusters}).train({
features: training,
inputProperties: clusterImage.bandNames()
});
var clustered = clusterImage.cluster(clusterer);
Map.addLayer(clustered.randomVisualizer().clip(geometry), {}, 'Clusters');
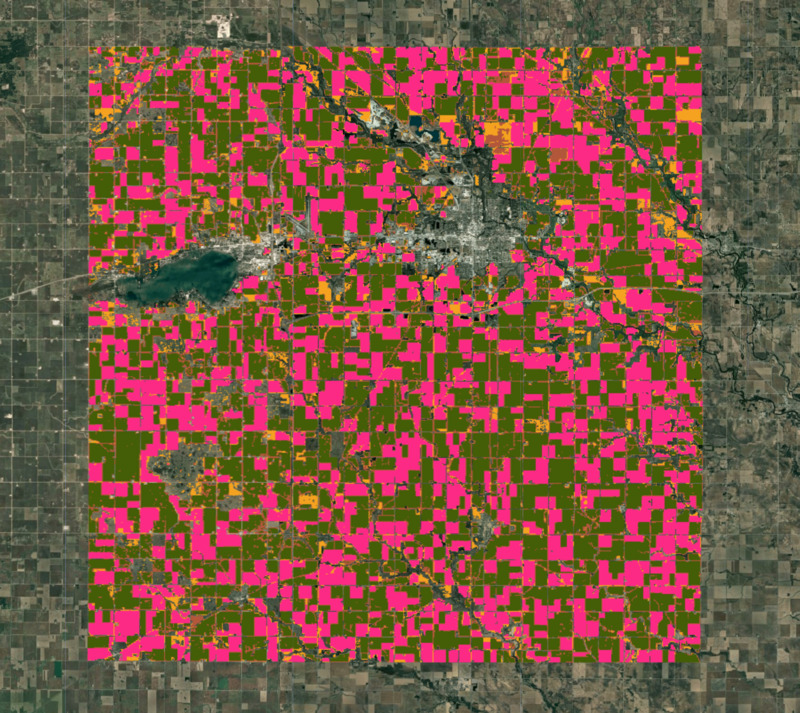
그림: 비지도 분류에서 얻은 클러스터
클러스터에 라벨 할당
시각적으로 검사한 결과 이전 단계에서 획득한 클러스터가 고해상도 이미지에 표시된 농장 경계와 거의 일치합니다. 현지 지식을 바탕으로 가장 큰 두 클러스터가 옥수수와 콩이라는 것을 알 수 있습니다. 이미지에서 각 클러스터의 영역을 계산해 보겠습니다.
// Calculate Cluster Areas
// 1 Acre = 4046.86 Sq. Meters
var areaImage = ee.Image.pixelArea().divide(4046.86).addBands(clustered);
var areas = areaImage.reduceRegion({
reducer: ee.Reducer.sum().group({
groupField: 1,
groupName: 'cluster',
}),
geometry: geometry,
scale: 10,
maxPixels: 1e10
});
var clusterAreas = ee.List(areas.get('groups'));
// Process results to extract the areas and create a FeatureCollection
var clusterAreas = clusterAreas.map(function(item) {
var areaDict = ee.Dictionary(item);
var clusterNumber = areaDict.getNumber('cluster').format();
var area = areaDict.getNumber('sum');
return ee.Feature(null, {cluster: clusterNumber, area: area});
});
var clusterAreaFc = ee.FeatureCollection(clusterAreas);
print('Cluster Areas', clusterAreaFc);
영역이 가장 큰 클러스터 2개를 선택합니다.
var selectedFc = clusterAreaFc.sort('area', false).limit(2);
print('Top 2 Clusters by Area', selectedFc);
하지만 어떤 클러스터가 어떤 작물인지 아직 알 수 없습니다. 옥수수나 콩의 필드 샘플이 몇 개 있다면 클러스터에 오버레이하여 각 라벨을 파악할 수 있습니다. 필드 샘플이 없는 경우 집계된 작물 통계를 활용할 수 있습니다. 전 세계 여러 지역에서 집계된 작물 통계가 정기적으로 수집되고 게시됩니다. 미국의 경우 농무부 산하의 국가농업통계국 (NASS)에서 각 카운티와 주요 작물에 대한 자세한 작물 통계를 제공합니다. 2022년 아이오와주 세로 고르도 카운티의 옥수수 재배 면적은 161,500에이커, 콩 재배 면적은 110,500에이커였습니다.
이 정보를 사용하면 상위 2개 클러스터 중 면적이 가장 큰 클러스터가 옥수수이고 다른 클러스터는 콩일 가능성이 높다는 것을 알 수 있습니다. 이러한 라벨을 할당하고 계산된 영역을 게시된 통계와 비교해 보겠습니다.
var cornFeature = selectedFc.sort('area', false).first();
var soybeanFeature = selectedFc.sort('area').first();
var cornCluster = cornFeature.get('cluster');
var soybeanCluster = soybeanFeature.get('cluster');
print('Corn Area (Detected)', cornFeature.getNumber('area').round());
print('Corn Area (From Crop Statistics)', 163500);
print('Soybean Area (Detected)', soybeanFeature.getNumber('area').round());
print('Soybean Area (From Crop Statistics)', 110500);
작물 지도 만들기
이제 각 클러스터의 라벨을 알 수 있으므로 각 자르기 유형의 픽셀을 추출하고 병합하여 최종 자르기 지도를 만들 수 있습니다.
// Select the clusters to create the crop map
var corn = clustered.eq(ee.Number.parse(cornCluster));
var soybean = clustered.eq(ee.Number.parse(soybeanCluster));
var merged = corn.add(soybean.multiply(2));
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(merged.clip(geometry), cropVis, 'Crop Map (Detected)');
결과를 해석하는 데 도움이 되도록 UI 요소를 사용하여 지도에 범례를 만들고 추가할 수도 있습니다.
// Add a Legend
var legend = ui.Panel({
layout: ui.Panel.Layout.Flow('horizontal'),
style: {position: 'bottom-center', padding: '8px 15px'}});
var addItem = function(color, name) {
var colorBox = ui.Label({
style: {color: '#ffffff',
backgroundColor: color,
padding: '10px',
margin: '0 4px 4px 0',
}
});
var description = ui.Label({
value: name,
style: {
margin: '0px 10px 0px 2px',
}
});
return ui.Panel({
widgets: [colorBox, description],
layout: ui.Panel.Layout.Flow('horizontal')
});
};
var title = ui.Label({
value: 'Legend',
style: {
fontWeight: 'bold',
fontSize: '16px',
margin: '0px 10px 0px 4px'
}
});
legend.add(title);
legend.add(addItem('#ffd400', 'Corn'));
legend.add(addItem('#267300', 'Soybean'));
legend.add(addItem('#bdbdbd', 'Other Crops'));
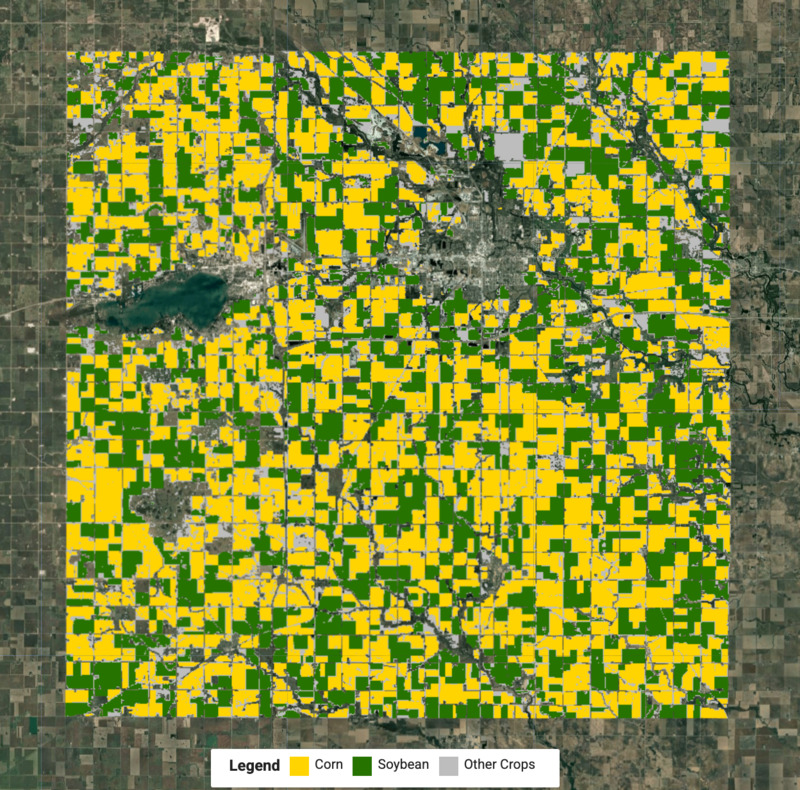
그림: 옥수수와 콩 작물이 있는 감지된 작물 지도
결과 검증
집계 통계와 지역의 현지 지식만 사용하여 필드 라벨 없이 위성 삽입 데이터 세트로 작물 유형 지도를 얻을 수 있었습니다. 결과를 USDA NASS Cropland Data Layers (CDL)의 공식 작물 유형 지도와 비교해 보겠습니다.
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var cropMap = cropLandcover.updateMask(croplandMask).rename('crops');
// Original data has unique values for each crop ranging from 0 to 254
var cropClasses = ee.List.sequence(0, 254);
// We remap all values as following
// Crop | Source Value | Target Value
// Corn | 1 | 1
// Soybean | 5 | 2
// All other| 0-255 | 0
var targetClasses = ee.List.repeat(0, 255).set(1, 1).set(5, 2);
var cropMapReclass = cropMap.remap(cropClasses, targetClasses).rename('crops');
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(cropMapReclass.clip(geometry), cropVis, 'Crop Landcover (CDL)');

그림: (왼쪽) 위성 삽입에서 지도 자르기 (오른쪽) CDL에서 지도 자르기
Google의 결과와 공식 지도 간에 불일치가 있지만 최소한의 노력으로 꽤 좋은 결과를 얻을 수 있었습니다. 결과에 후처리 단계를 적용하면 일부 노이즈를 제거하고 출력의 격차를 메울 수 있습니다.