पिछले ट्यूटोरियल (परिचय) में, हमने देखा कि सैटलाइट एम्बेडिंग, सैटलाइट से मिले डेटा और जलवायु के वैरिएबल की सालाना ट्रैजेक्ट्री को कैसे कैप्चर करती हैं. इससे फ़सल की फ़िनॉलॉजी को मॉडल करने की ज़रूरत नहीं पड़ती. साथ ही, डेटासेट का इस्तेमाल फ़सलों की मैपिंग के लिए आसानी से किया जा सकता है. फ़सल के टाइप को मैप करना एक मुश्किल काम है. इसके लिए, आम तौर पर फ़सल की फ़िनॉलॉजी को मॉडल करना और इलाके में उगाई जाने वाली सभी फ़सलों के लिए फ़ील्ड सैंपल इकट्ठा करना ज़रूरी होता है.
इस ट्यूटोरियल में, हम फ़सल की मैपिंग के लिए बिना निगरानी वाले क्लासिफ़िकेशन का तरीका अपनाएंगे. इससे हमें फ़ील्ड के लेबल पर भरोसा किए बिना, इस मुश्किल काम को पूरा करने में मदद मिलेगी. इस तरीके में, फ़सल के कुल आंकड़ों के साथ-साथ इलाके की स्थानीय जानकारी का इस्तेमाल किया जाता है. ये आंकड़े, दुनिया के कई हिस्सों के लिए आसानी से उपलब्ध होते हैं.
देश या इलाका चुनें
इस ट्यूटोरियल के लिए, हम आयोवा के सेरो गोर्डो काउंटी के लिए फ़सल के टाइप का मैप बनाएंगे. यह काउंटी, अमेरिका के कॉर्न बेल्ट में है. यहां मुख्य रूप से दो फ़सलें उगाई जाती हैं: मक्का और सोयाबीन. स्थानीय जानकारी ज़रूरी है. इससे हमें अपने मॉडल के लिए मुख्य पैरामीटर तय करने में मदद मिलेगी.
आइए, चुनी गई काउंटी की सीमा की जानकारी से शुरुआत करते हैं.
// Select the region
// Cerro Gordo County, Iowa
var counties = ee.FeatureCollection('TIGER/2018/Counties');
var selected = counties
.filter(ee.Filter.eq('GEOID', '19033'));
var geometry = selected.geometry();
Map.centerObject(geometry, 12);
Map.addLayer(geometry, {color: 'red'}, 'Selected Region', false);

आंकड़ा: चुना गया क्षेत्र
सैटलाइट एम्बेडिंग डेटासेट तैयार करना
इसके बाद, हम सैटलाइट एम्बेडिंग डेटासेट लोड करते हैं. साथ ही, चुने गए साल की इमेज के लिए फ़िल्टर करते हैं और एक मोज़ेक बनाते हैं.
var embeddings = ee.ImageCollection('GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL');
var year = 2022;
var startDate = ee.Date.fromYMD(year, 1, 1);
var endDate = startDate.advance(1, 'year');
var filteredembeddings = embeddings
.filter(ee.Filter.date(startDate, endDate))
.filter(ee.Filter.bounds(geometry));
var embeddingsImage = filteredembeddings.mosaic();
फ़सल वाली ज़मीन का मास्क बनाना
मॉडलिंग के लिए, हमें फ़सल वाली ज़मीन के अलावा अन्य इलाकों को शामिल नहीं करना है. फ़सल का मास्क बनाने के लिए, कई ग्लोबल और रीजनल डेटासेट का इस्तेमाल किया जा सकता है. ESA WorldCover या GFSAD Global Cropland Extent Product, दुनिया भर के फ़सल वाले खेतों के डेटासेट के लिए अच्छे विकल्प हैं. हाल ही में, ESA WorldCereal Active Cropland प्रॉडक्ट को जोड़ा गया है. इसमें, फ़सल उगाने के लिए इस्तेमाल की जा रही ज़मीन की सीज़नल मैपिंग की जाती है. हमारा क्षेत्र अमेरिका में है. इसलिए, फ़सल का मास्क पाने के लिए, हम USDA NASS Cropland Data Layers (CDL) का इस्तेमाल कर सकते हैं. यह एक ज़्यादा सटीक रीजनल डेटासेट है.
// Use Cropland Data Layers (CDL) to obtain cultivated cropland
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var croplandMask = cdl.select('cultivated').eq(2).rename('cropmask');
// Visualize the crop mask
var croplandMaskVis = {min: 0, max: 1, palette: ['white', 'green']};
Map.addLayer(croplandMask.clip(geometry), croplandMaskVis, 'Crop Mask');
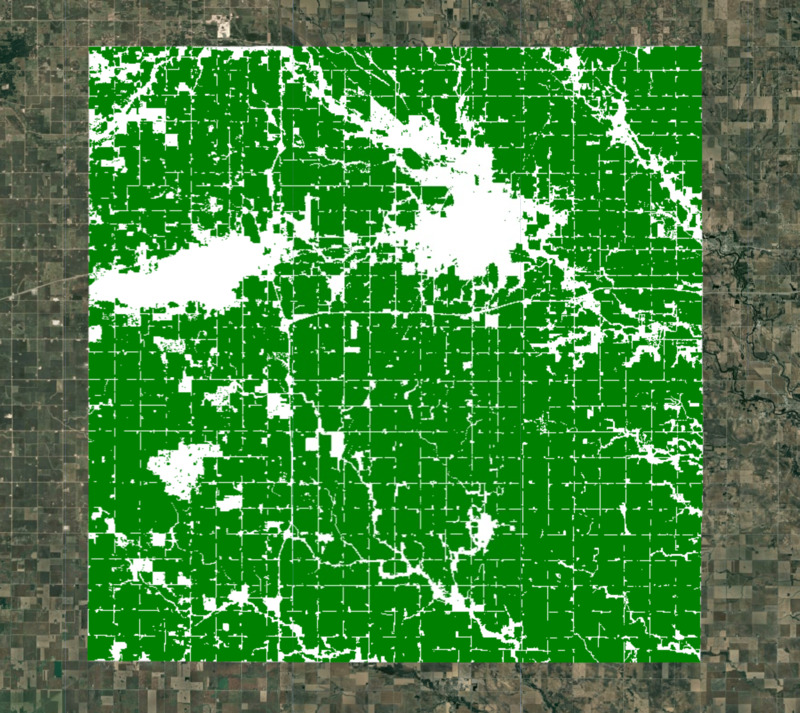
आंकड़ा: फ़सल वाली ज़मीन के मास्क के साथ चुना गया क्षेत्र
ट्रेनिंग के लिए सैंपल निकालना
हम एम्बेडिंग मोज़ेक पर फ़सल वाली ज़मीन का मास्क लागू करते हैं. अब हमारे पास काउंटी में खेती की गई ज़मीन को दिखाने वाले सभी पिक्सल हैं.
// Mask all non-cropland pixels
var clusterImage = embeddingsImage.updateMask(croplandMask);
हमें सैटलाइट एम्बेडिंग इमेज लेनी होगी. साथ ही, क्लस्टरिंग मॉडल को ट्रेन करने के लिए, रैंडम सैंपल पाने होंगे. हमारे दिलचस्पी वाले इलाके में कई मास्क किए गए पिक्सल मौजूद हैं. इसलिए, सामान्य रैंडम सैंपलिंग से ऐसे सैंपल मिल सकते हैं जिनमें कोई वैल्यू नहीं है. यह पक्का करने के लिए कि हम गैर-शून्य सैंपल की ज़रूरी संख्या निकाल सकें, हम स्ट्रैटिफ़ाइड सैंपलिंग का इस्तेमाल करते हैं. इससे, हम बिना मास्क किए गए इलाकों में ज़रूरी संख्या में सैंपल पा सकते हैं.
// Stratified random sampling
var training = clusterImage.addBands(croplandMask).stratifiedSample({
numPoints: 1000,
classBand: 'cropmask',
region: geometry,
scale: 10,
tileScale: 16,
seed: 100,
dropNulls: true,
geometries: true
});
सैंपल को किसी ऐसेट में एक्सपोर्ट करना (ज़रूरी नहीं)
सैंपल निकालना एक मुश्किल प्रोसेस है. इसलिए, यह सबसे सही तरीका है कि निकाले गए ट्रेनिंग सैंपल को ऐसेट के तौर पर एक्सपोर्ट किया जाए. साथ ही, अगले चरणों में एक्सपोर्ट की गई ऐसेट का इस्तेमाल किया जाए. इससे बड़े क्षेत्रों के साथ काम करते समय, कंप्यूटेशन का समय खत्म हो गया या उपयोगकर्ता की मेमोरी से जुड़ी गड़बड़ियों को ठीक करने में मदद मिलेगी.
एक्सपोर्ट करने की प्रोसेस शुरू करें और आगे बढ़ने से पहले, इसके पूरा होने का इंतज़ार करें.
// Replace this with your asset folder
// The folder must exist before exporting
var exportFolder = 'projects/spatialthoughts/assets/satellite_embedding/';
var samplesExportFc = 'cluster_training_samples';
var samplesExportFcPath = exportFolder + samplesExportFc;
Export.table.toAsset({
collection: training,
description: 'Cluster_Training_Samples',
assetId: samplesExportFcPath
});
एक्सपोर्ट करने का टास्क पूरा होने के बाद, हम निकाले गए सैंपल को अपने कोड में, फ़ीचर कलेक्शन के तौर पर फिर से पढ़ सकते हैं.
// Use the exported asset
var training = ee.FeatureCollection(samplesExportFcPath);
सैंपल को विज़ुअलाइज़ करना
आपने सैंपल को इंटरैक्टिव तरीके से चलाया हो या उसे सुविधा संग्रह में एक्सपोर्ट किया हो, अब आपके पास सैंपल पॉइंट के साथ ट्रेनिंग वैरिएबल होगा. आइए, पहले सैंपल को प्रिंट करके देखते हैं. इससे हमें Map में ट्रेनिंग पॉइंट जोड़ने में मदद मिलेगी.
print('Extracted sample', training.first());
Map.addLayer(training, {color: 'blue'}, 'Extracted Samples', false);

आंकड़ा: क्लस्टरिंग के लिए निकाले गए रैंडम सैंपल
बिना निगरानी वाली क्लस्टरिंग करना
अब हम क्लस्टरर को ट्रेन कर सकते हैं और 64 डाइमेंशन वाले एम्बेडिंग वेक्टर को, चुने गए अलग-अलग क्लस्टर में ग्रुप कर सकते हैं. हमारे पास स्थानीय जानकारी के आधार पर, दो मुख्य तरह की फ़सलें हैं. ये फ़सलें, ज़्यादातर इलाके में उगाई जाती हैं. इसके अलावा, कुछ अन्य फ़सलें भी उगाई जाती हैं. हम सैटलाइट एम्बेडिंग पर बिना निगरानी वाली क्लस्टरिंग कर सकते हैं. इससे हमें ऐसे पिक्सल के क्लस्टर मिलते हैं जिनकी टेंपोरल ट्रैजेक्ट्री और पैटर्न एक जैसे होते हैं. एक जैसी स्पेक्ट्रल और स्पेशल विशेषताओं के साथ-साथ एक जैसी फ़िनॉलॉजी वाले पिक्सल को एक ही क्लस्टर में ग्रुप किया जाएगा.
ee.Clusterer.wekaCascadeKMeans() की मदद से, क्लस्टर की कम से कम और ज़्यादा से ज़्यादा संख्या तय की जा सकती है. साथ ही, ट्रेनिंग के डेटा के आधार पर क्लस्टर की सबसे सही संख्या का पता लगाया जा सकता है. यहां क्लस्टर की कम से कम और ज़्यादा से ज़्यादा संख्या तय करने के लिए, स्थानीय जानकारी काम आती है. हमें अलग-अलग तरह के कुछ क्लस्टर मिलने की उम्मीद है. जैसे, मक्का, सोयाबीन, और कई अन्य फ़सलें. इसलिए, हम क्लस्टर की कम से कम संख्या के तौर पर 4 और ज़्यादा से ज़्यादा संख्या के तौर पर 5 का इस्तेमाल कर सकते हैं. आपको इन नंबरों के साथ एक्सपेरिमेंट करना पड़ सकता है, ताकि यह पता लगाया जा सके कि आपके इलाके के लिए कौनसा नंबर सबसे अच्छा काम करता है.
// Cluster the Satellite Embedding Image
var minClusters = 4;
var maxClusters = 5;
var clusterer = ee.Clusterer.wekaCascadeKMeans({
minClusters: minClusters, maxClusters: maxClusters}).train({
features: training,
inputProperties: clusterImage.bandNames()
});
var clustered = clusterImage.cluster(clusterer);
Map.addLayer(clustered.randomVisualizer().clip(geometry), {}, 'Clusters');
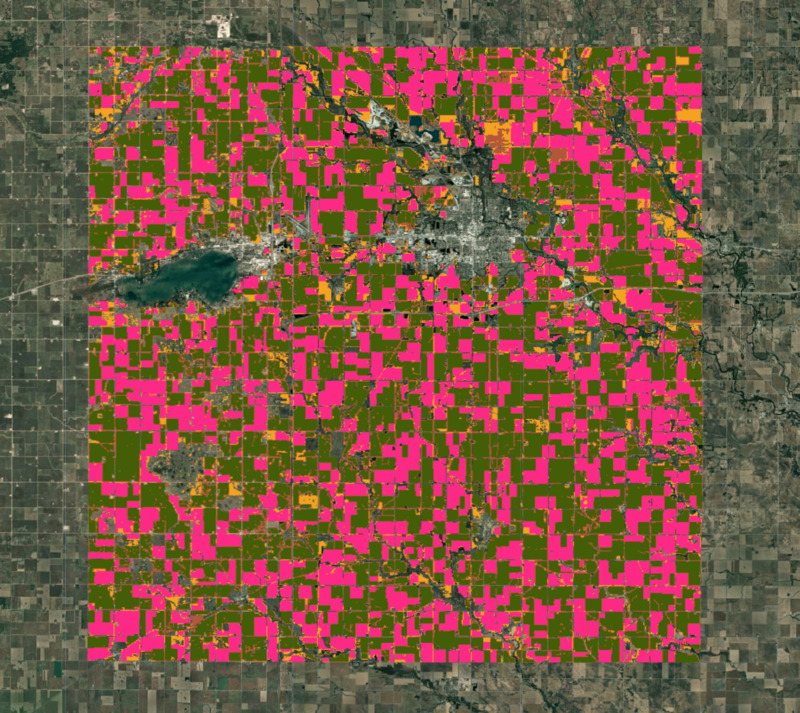
आंकड़ा: बिना निगरानी वाले क्लासिफ़िकेशन से मिले क्लस्टर
क्लस्टर को लेबल असाइन करना
विज़ुअल जांच करने पर, पिछले चरणों में मिले क्लस्टर, हाई रिज़ॉल्यूशन वाली इमेज में दिख रही फ़ार्म की सीमाओं से काफ़ी हद तक मेल खाते हैं. हमें स्थानीय जानकारी से पता है कि दो सबसे बड़े क्लस्टर, मक्का और सोयाबीन के होंगे. आइए, अपनी इमेज में मौजूद हर क्लस्टर के क्षेत्र का हिसाब लगाएं.
// Calculate Cluster Areas
// 1 Acre = 4046.86 Sq. Meters
var areaImage = ee.Image.pixelArea().divide(4046.86).addBands(clustered);
var areas = areaImage.reduceRegion({
reducer: ee.Reducer.sum().group({
groupField: 1,
groupName: 'cluster',
}),
geometry: geometry,
scale: 10,
maxPixels: 1e10
});
var clusterAreas = ee.List(areas.get('groups'));
// Process results to extract the areas and create a FeatureCollection
var clusterAreas = clusterAreas.map(function(item) {
var areaDict = ee.Dictionary(item);
var clusterNumber = areaDict.getNumber('cluster').format();
var area = areaDict.getNumber('sum');
return ee.Feature(null, {cluster: clusterNumber, area: area});
});
var clusterAreaFc = ee.FeatureCollection(clusterAreas);
print('Cluster Areas', clusterAreaFc);
हम सबसे ज़्यादा एरिया वाले दो क्लस्टर चुनते हैं.
var selectedFc = clusterAreaFc.sort('area', false).limit(2);
print('Top 2 Clusters by Area', selectedFc);
हालांकि, हमें अब भी यह नहीं पता है कि कौनसे क्लस्टर में कौनसी फ़सल है. अगर आपके पास मक्का या सोयाबीन के कुछ फ़ील्ड सैंपल हैं, तो उन्हें क्लस्टर पर ओवरले करके उनके लेबल का पता लगाया जा सकता है. फ़ील्ड के सैंपल न होने पर, हम फ़सल के कुल आंकड़ों का इस्तेमाल कर सकते हैं. दुनिया के कई हिस्सों में, फ़सलों के कुल आंकड़ों को इकट्ठा किया जाता है और उन्हें नियमित तौर पर पब्लिश किया जाता है. अमेरिका के लिए, नैशनल ऐग्रीकल्चरल स्टैटिस्टिक्स सर्विस (एनएएसएस) के पास हर काउंटी और हर मुख्य फ़सल के बारे में आंकड़ों की पूरी जानकारी होती है. साल 2022 में, सेरो गोर्डो काउंटी, आयोवा में 1,61,500 एकड़ में मक्का और 1,10,500 एकड़ में सोयाबीन की खेती की गई.
इस जानकारी का इस्तेमाल करके, अब हमें पता है कि सबसे बड़े दो क्लस्टर में से एक में मक्का और दूसरे में सोयाबीन होगा. आइए, इन लेबल को असाइन करें और कैलकुलेट किए गए क्षेत्रों की तुलना पब्लिश किए गए आंकड़ों से करें.
var cornFeature = selectedFc.sort('area', false).first();
var soybeanFeature = selectedFc.sort('area').first();
var cornCluster = cornFeature.get('cluster');
var soybeanCluster = soybeanFeature.get('cluster');
print('Corn Area (Detected)', cornFeature.getNumber('area').round());
print('Corn Area (From Crop Statistics)', 163500);
print('Soybean Area (Detected)', soybeanFeature.getNumber('area').round());
print('Soybean Area (From Crop Statistics)', 110500);
फ़सल का मैप बनाना
अब हमें हर क्लस्टर के लिए लेबल पता हैं. इसलिए, हम हर फ़सल के टाइप के लिए पिक्सल निकाल सकते हैं और उन्हें मर्ज करके, फ़सल का फ़ाइनल मैप बना सकते हैं.
// Select the clusters to create the crop map
var corn = clustered.eq(ee.Number.parse(cornCluster));
var soybean = clustered.eq(ee.Number.parse(soybeanCluster));
var merged = corn.add(soybean.multiply(2));
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(merged.clip(geometry), cropVis, 'Crop Map (Detected)');
नतीजों को समझने में मदद पाने के लिए, यूज़र इंटरफ़ेस (यूआई) एलिमेंट का इस्तेमाल करके, मैप में लेजेंड बनाया और जोड़ा जा सकता है.
// Add a Legend
var legend = ui.Panel({
layout: ui.Panel.Layout.Flow('horizontal'),
style: {position: 'bottom-center', padding: '8px 15px'}});
var addItem = function(color, name) {
var colorBox = ui.Label({
style: {color: '#ffffff',
backgroundColor: color,
padding: '10px',
margin: '0 4px 4px 0',
}
});
var description = ui.Label({
value: name,
style: {
margin: '0px 10px 0px 2px',
}
});
return ui.Panel({
widgets: [colorBox, description],
layout: ui.Panel.Layout.Flow('horizontal')
});
};
var title = ui.Label({
value: 'Legend',
style: {
fontWeight: 'bold',
fontSize: '16px',
margin: '0px 10px 0px 4px'
}
});
legend.add(title);
legend.add(addItem('#ffd400', 'Corn'));
legend.add(addItem('#267300', 'Soybean'));
legend.add(addItem('#bdbdbd', 'Other Crops'));
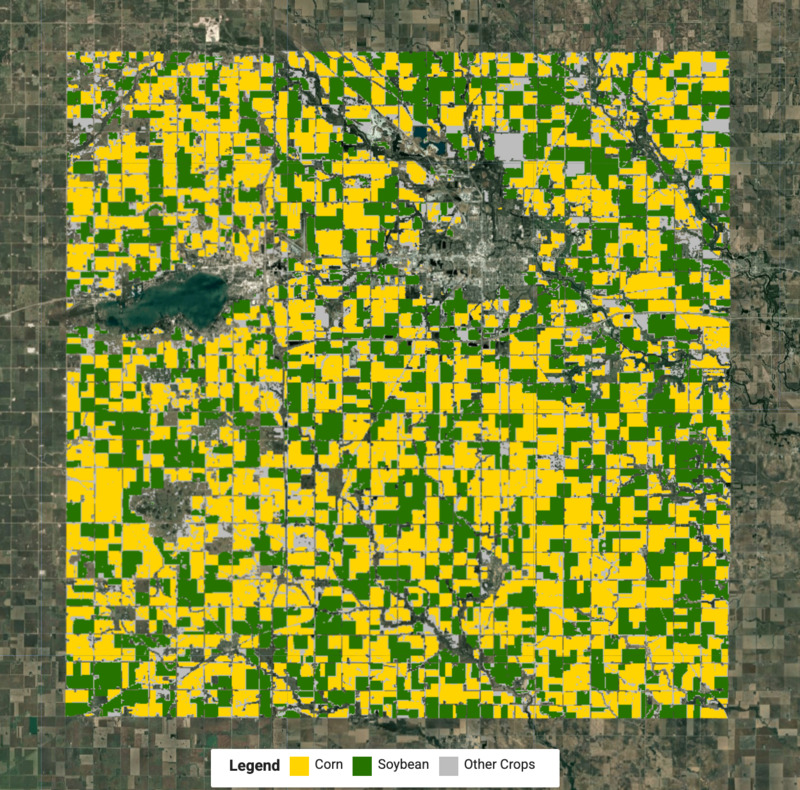
आंकड़ा: मक्का और सोयाबीन की फ़सलों के साथ, फ़सल का पता लगाया गया मैप
नतीजों की पुष्टि करना
हमने सिर्फ़ एग्रीगेट किए गए आंकड़ों और इलाके की जानकारी का इस्तेमाल करके, फ़ील्ड के लेबल के बिना सैटलाइट एम्बेडिंग डेटासेट से फ़सल के टाइप का मैप बनाया. आइए, अपने नतीजों की तुलना USDA NASS के फ़सल वाले खेत के डेटा लेयर (सीडीएल) के आधिकारिक फ़सल टाइप मैप से करें.
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var cropMap = cropLandcover.updateMask(croplandMask).rename('crops');
// Original data has unique values for each crop ranging from 0 to 254
var cropClasses = ee.List.sequence(0, 254);
// We remap all values as following
// Crop | Source Value | Target Value
// Corn | 1 | 1
// Soybean | 5 | 2
// All other| 0-255 | 0
var targetClasses = ee.List.repeat(0, 255).set(1, 1).set(5, 2);
var cropMapReclass = cropMap.remap(cropClasses, targetClasses).rename('crops');
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(cropMapReclass.clip(geometry), cropVis, 'Crop Landcover (CDL)');

आंकड़ा: (बाएं) सैटेलाइट एम्बेडिंग से मैप को काटा गया है (दाएं) सीडीएल से मैप को काटा गया है
हमारे नतीजों और आधिकारिक मैप के बीच अंतर होने के बावजूद, आपको पता चलेगा कि हमने कम मेहनत में काफ़ी अच्छे नतीजे हासिल किए हैं. नतीजों पर पोस्ट-प्रोसेसिंग के चरण लागू करके, हम कुछ गड़बड़ियां दूर कर सकते हैं और आउटपुट में मौजूद कमियों को पूरा कर सकते हैं.
Earth Engine Code Editor में, इस ट्यूटोरियल के लिए पूरी स्क्रिप्ट आज़माएं.