Comme le clustering n'est pas supervisé, aucune "vérité" n'est disponible pour vérifier les résultats. L'absence de vérité complique l'évaluation de la qualité. De plus, les ensembles de données concrets ne correspondent généralement pas à des clusters d'exemples évidents, comme celui illustré dans la Figure 1.
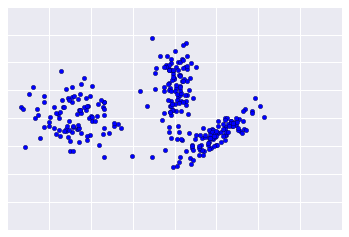
Malheureusement, les données réelles ressemblent davantage à la figure 2, ce qui complique la tâche d'évaluation visuelle de la qualité du clustering.
L'organigramme ci-dessous résume comment vérifier la qualité de votre cluster. Nous développerons le récapitulatif dans les sections suivantes.

Étape 1: Qualité du clustering
Vérifier la qualité du clustering n'est pas un processus rigoureux, car il manque de "vérité". Voici quelques consignes que vous pouvez appliquer de manière itérative pour améliorer la qualité de votre clustering.
Commencez par vérifier visuellement que les clusters se présentent comme prévu et que les exemples que vous considérez comme similaires apparaissent dans le même cluster. Vérifiez ensuite ces métriques couramment utilisées comme décrit dans les sections suivantes:
- Cardinalité du cluster
- Magnitude des clusters
- Performances du système en aval
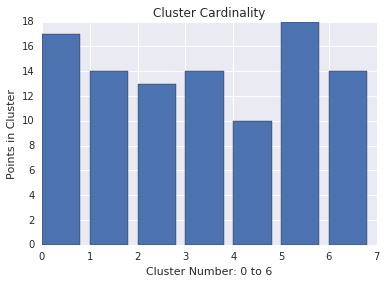
Cardinalité du cluster
La cardinalité du cluster correspond au nombre d'exemples par cluster. Tracez la cardinalité du cluster pour tous les clusters et examinez les clusters qui constituent des anomalies majeures. Par exemple, dans la Figure 2, examinez le cluster numéro 5.
magnitude du cluster
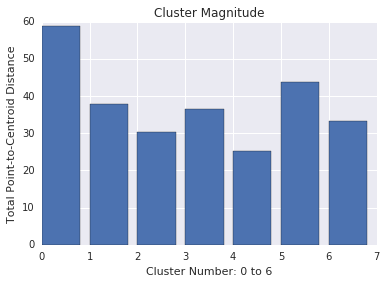
La magnitude du cluster correspond à la somme des distances de tous les exemples par rapport au centroïde du cluster. Comme pour la cardinalité, vérifiez les variations de la magnitude entre les clusters et examinez les anomalies. Par exemple, dans la Figure 3, examinez le cluster numéro 0.
Magnitude et cardinalité
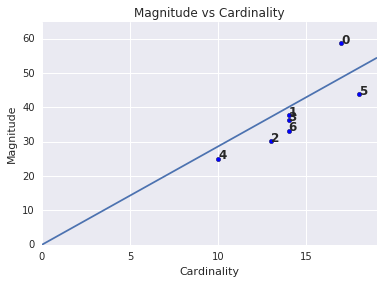
Notez qu'une cardinalité plus élevée entraîne une magnitude de cluster plus élevée, ce qui est logique. Les clusters sont anormaux lorsque la cardinalité n'est pas corrélée à la magnitude par rapport aux autres clusters. Identifiez les clusters anormaux en représentant la magnitude par rapport à la cardinalité. Par exemple, dans la figure 4, l'ajustement d'une ligne aux métriques du cluster indique que le nombre de clusters 0 est anormal.
Performances du système en aval
Étant donné que la sortie de clustering est souvent utilisée dans les systèmes de ML en aval, vérifiez si les performances du système en aval s'améliorent lorsque votre processus de clustering change. L'impact sur vos performances en aval fournit un test réel pour la qualité de votre clustering. L'inconvénient est que cette vérification est complexe.
Questions à examiner en cas de problème
Si vous rencontrez des problèmes, vérifiez votre préparation de données et votre mesure de similarité en vous posant les questions suivantes:
- Vos données sont-elles mises à l'échelle ?
- Votre mesure de similarité est-elle correcte ?
- Votre algorithme effectue-t-il des opérations sémantiquement pertinentes sur les données ?
- Les hypothèses de votre algorithme correspondent-elles aux données ?
Étape 2: Mesure de la similarité
Votre algorithme de clustering est aussi efficace que votre mesure de similarité. Assurez-vous que votre mesure de similarité renvoie des résultats pertinents. La vérification la plus simple consiste à identifier des paires d'exemples connus pour être plus ou moins similaires aux autres paires. Calculez ensuite la mesure de similarité pour chaque paire d'exemples. Assurez-vous que la mesure de similarité pour des exemples plus similaires est plus élevée que pour des exemples moins similaires.
Les exemples que vous utilisez pour vérifier ponctuellement votre mesure de similarité doivent être représentatifs de l'ensemble de données. Assurez-vous que votre mesure de similarité s'applique à tous vos exemples. Une vérification minutieuse garantit que votre mesure de similarité, qu'elle soit manuelle ou supervisée, est cohérente dans votre ensemble de données. Si votre mesure de similarité n'est pas cohérente pour certains exemples, ceux-ci ne seront pas regroupés avec des exemples similaires.
Si vous trouvez des exemples avec des similitudes inexactes, votre mesure de similarité ne capture probablement pas les données de caractéristiques qui les distinguent. Testez votre mesure de similarité et déterminez si vous obtenez des similitudes plus précises.
Étape 3: Nombre optimal de clusters
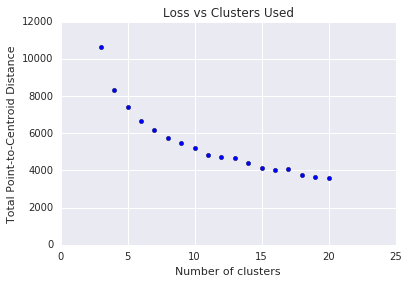
Pour l'algorithme k-moyennes, vous devez déterminer le nombre de clusters \(k\) au préalable. Comment déterminez-vous la valeur optimale de \(k\)? Essayez d'exécuter l'algorithme pour augmenter \(k\) et notez la somme des magnitudes des clusters. À mesure que le \(k\)augmente, les clusters deviennent plus petits et la distance totale diminue. Tracez cette distance par rapport au nombre de clusters.
Comme le montre la figure 4, à un certain \(k\), la réduction de la perte devient marginale avec l'augmentation de \(k\). Mathématiquement, il s'agit à peu près \(k\) de l'endroit où la pente dépasse -1 (\(\theta > 135^{\circ}\)). Cette consigne ne précise pas la valeur exacte optimale, \(k\) mais une valeur approximative. Pour le graphique affiché, la valeur optimale \(k\) est d'environ 11. Si vous préférez des clusters plus précis, vous pouvez choisir un \(k\) plus élevé en vous appuyant sur ce graphique.