Objetivo
En el instructivo sobre la Validación de direcciones de gran volumen, se te guió por diferentes situaciones en las que se puede usar la validación de direcciones de gran volumen. En este instructivo, te presentaremos diferentes patrones de diseño en Google Cloud Platform para ejecutar la Validación de direcciones de alto volumen.
Comenzaremos con una descripción general sobre cómo ejecutar la API de High Volume Address Validation en Google Cloud Platform con Cloud Run, Compute Engine o Google Kubernetes Engine para ejecuciones únicas. Luego, veremos cómo se puede incluir esta capacidad como parte de una canalización de datos.
Al final de este artículo, deberías comprender bien las diferentes opciones para ejecutar la API de Address Validation en grandes volúmenes en tu entorno de Google Cloud.
Arquitectura de referencia en Google Cloud Platform
En esta sección, se profundiza en diferentes patrones de diseño para la Validación de direcciones de alto volumen con Google Cloud Platform. Si ejecutas la plataforma de Google Cloud, puedes integrarla en tus procesos y canalizaciones de datos existentes.
Ejecuta la API de High Volume Address Validation una vez en Google Cloud Platform
A continuación, se muestra una arquitectura de referencia sobre cómo compilar una integración en Google Cloud Platform que sea más adecuada para operaciones únicas o pruebas.

En este caso, te recomendamos que subas el archivo CSV a un bucket de Cloud Storage. Luego, la secuencia de comandos de High Volume Address Validation se puede ejecutar desde un entorno de Cloud Run. Sin embargo, puedes ejecutarlo en cualquier otro entorno de ejecución, como Compute Engine o Google Kubernetes Engine. El CSV de salida también se puede subir al bucket de Cloud Storage.
Ejecución como una canalización de datos de Google Cloud
El patrón de implementación que se muestra en la sección anterior es ideal para probar rápidamente la API de High Volume Address Validation para un uso único. Sin embargo, si necesitas usarlo con regularidad como parte de una canalización de datos, puedes aprovechar mejor las capacidades nativas de Google Cloud Platform para que sea más sólido. Estos son algunos de los cambios que puedes realizar:
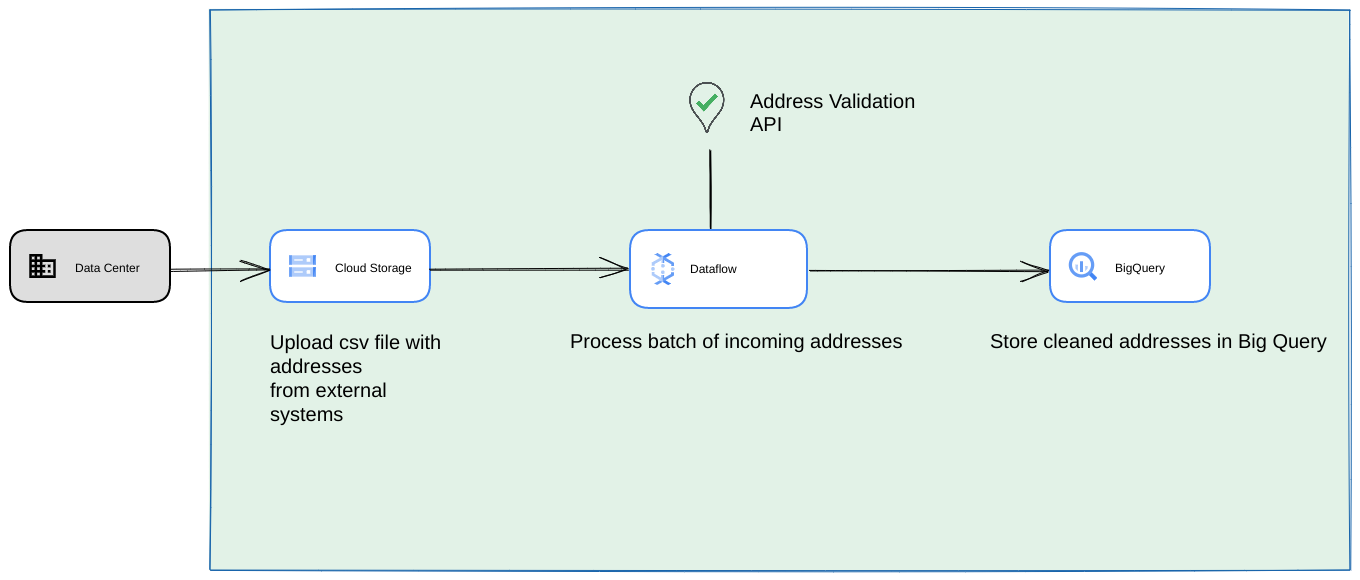
- En este caso, puedes volcar archivos CSV en buckets de Cloud Storage.
- Un trabajo de Dataflow puede recuperar las direcciones que se procesarán y, luego, almacenarlas en la caché de BigQuery.
- La biblioteca de Python de Dataflow se puede extender para incluir lógica para la Validación de direcciones de alto volumen y, así, validar las direcciones del trabajo de Dataflow.
Ejecutar la secuencia de comandos desde una canalización de datos como un proceso recurrente de larga duración
Otro enfoque común es validar un lote de direcciones como parte de una canalización de datos de transmisión como un proceso recurrente. También es posible que tengas las direcciones en un almacén de datos de BigQuery. En este enfoque, veremos cómo crear una canalización de datos recurrente (que debe activarse a diario, semanal o mensualmente).
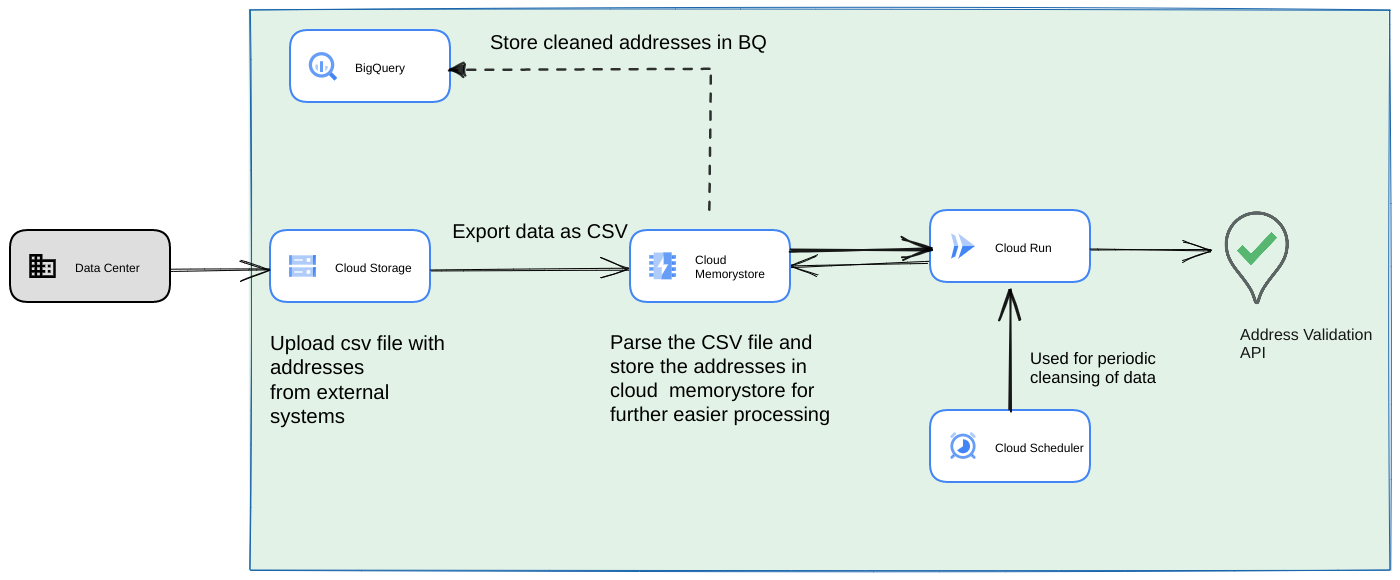
- Sube el archivo CSV inicial a un bucket de Cloud Storage.
- Usa Memorystore como un almacén de datos persistente para mantener el estado intermedio del proceso de larga duración.
- Almacena en caché las direcciones finales en un almacén de datos de BigQuery.
- Configura Cloud Scheduler para ejecutar la secuencia de comandos de forma periódica.
Esta arquitectura cuenta con las siguientes ventajas:
- Con Cloud Scheduler, la validación de direcciones se puede realizar de forma periódica. Te recomendamos que vuelvas a validar las direcciones todos los meses o que valides las direcciones nuevas cada mes o trimestre. Esta arquitectura ayuda a resolver ese caso de uso.
Si los datos del cliente se encuentran en BigQuery, las direcciones validadas o las marcas de validación se pueden almacenar en caché directamente allí. Nota: En el artículo sobre la API de High Volume Address Validation, se describe en detalle qué se puede almacenar en caché y cómo hacerlo.
El uso de Memorystore proporciona mayor capacidad de recuperación y habilidad para procesar más direcciones. Este paso agrega un estado a toda la canalización de procesamiento, lo que es necesario para controlar conjuntos de datos de direcciones muy grandes. También se pueden usar otras tecnologías de bases de datos, como Cloud SQL [https://cloud.google.com/sql] o cualquier otro tipo de base de datos que ofrece Google Cloud Platform. Sin embargo, creemos que memorystore perfectless equilibra las necesidades de escalamiento y simplicidad, por lo que debería ser la primera opción.
Conclusión
Si aplicas los patrones que se describen aquí, puedes usar la API de Address Validation para diferentes casos de uso y desde diferentes casos de uso en Google Cloud Platform.
Escribimos una biblioteca de Python de código abierto para ayudarte a comenzar con los casos de uso descritos anteriormente. Se puede invocar desde una línea de comandos en tu computadora o desde Google Cloud Platform o desde otros proveedores de servicios en la nube.
Obtén más información para usar la biblioteca en este artículo.
Próximos pasos
Descarga el Informe técnico sobre cómo optimizar la confirmación de compra, la entrega y las operaciones con direcciones confiables y mira el seminario web sobre cómo optimizar la confirmación de compra, la entrega y las operaciones con la Validación de direcciones .
Lecturas adicionales sugeridas:
- Documentación de la API de Address Validation
- Geocoding y Address Validation
- Explora la demostración de Address Validation
Colaboradores
Google mantiene este artículo. Los siguientes colaboradores escribieron el texto original.
Autores principales:
Henrik Valve | Ingeniero de soluciones
Thomas Anglaret | Ingeniero de soluciones
Sarthak Ganguly | Ingeniero de soluciones