
目標
大量地址驗證教學課程說明瞭可使用大量地址驗證的不同情境。在本教學課程中,我們將介紹 Google Cloud Platform 中執行大量地址驗證的不同設計模式。
首先,我們會概略說明如何在 Google Cloud Platform 中,使用 Cloud Run、Compute Engine 或 Google Kubernetes Engine 執行大量地址驗證。接著,我們會瞭解如何將這項功能納入資料管道。
讀完本文後,您應該會充分瞭解在 Google Cloud 環境中,以高用量執行地址驗證的不同選項。
Google Cloud Platform 參考架構
本節將深入探討使用 Google Cloud Platform 進行大量地址驗證的不同設計模式。在 Google Cloud Platform 上執行時,您可以與現有的程序和資料管道整合。
在 Google Cloud Platform 上執行大量地址驗證一次
下圖為參考架構,說明如何在 Google Cloud Platform 上建構整合功能,更適合用於一次性作業或測試。

在這種情況下,建議將 CSV 檔案上傳至 Cloud Storage bucket。接著,您可以在 Cloud Run 環境中執行大量地址驗證指令碼。 不過,您可以在任何其他執行階段環境中執行,例如 Compute Engine 或 Google Kubernetes Engine。 輸出 CSV 檔案也可以上傳至 Cloud Storage bucket。
以 Google Cloud Platform 資料管道的形式執行
上一節顯示的部署模式非常適合快速測試大量地址驗證,以供一次性使用。不過,如果您需要經常使用這項功能做為資料管道的一部分,則可善用 Google Cloud Platform 原生功能,讓這項功能更加強大。您可以進行的變更包括:
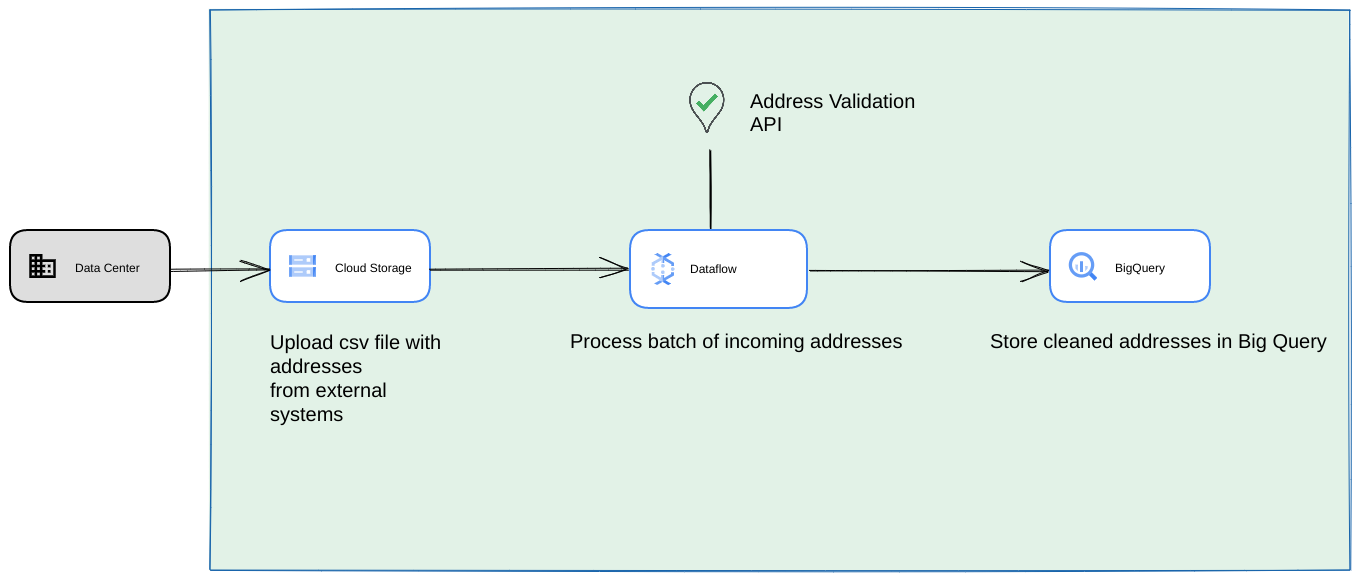
- 在這種情況下,您可以將 CSV 檔案傾印至 Cloud Storage bucket。
- Dataflow 工作可以擷取要處理的地址,然後快取到 BigQuery。
- 您可以擴充 Dataflow Python 程式庫,加入大量地址驗證的邏輯,藉此驗證 Dataflow 工作中的地址。
從資料管道執行指令碼,做為長期執行的週期性程序
另一個常見做法是將一批地址做為串流資料管道的一部分,以定期程序的形式驗證。您也可以將地址儲存在 BigQuery 資料存放區。在這個方法中,我們會瞭解如何建構週期性資料管道 (需要每天/每週/每月觸發)
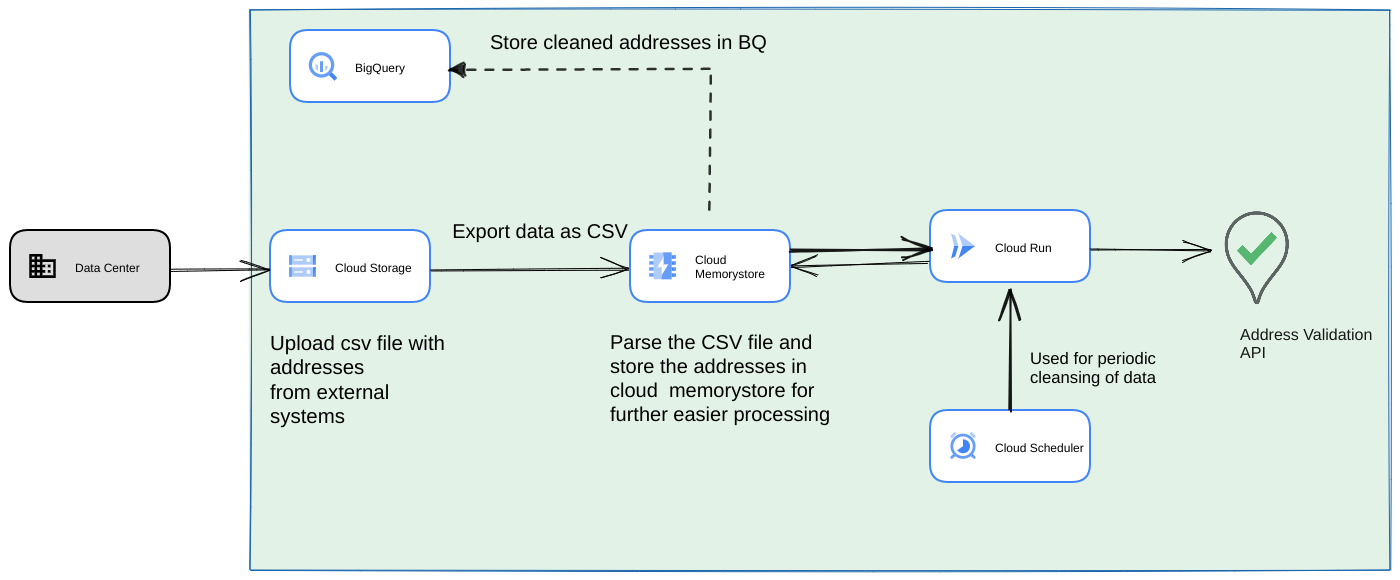
- 將初始 CSV 檔案上傳至 Cloud Storage bucket。
- 使用 Memorystore 做為持續性資料儲存空間,維護長時間執行的程序的中間狀態。
- 將最終地址快取至 BigQuery 資料存放區。
- 設定 Cloud Scheduler,定期執行指令碼。
這個架構有以下優點:
- 使用 Cloud Scheduler,即可定期驗證地址。建議您每月重新驗證地址,或每月/每季驗證新地址。這個架構有助於解決該使用情境的問題。
如果顧客資料位於 BigQuery,則驗證過的地址或驗證標記可直接快取至該處。 注意:如要瞭解可快取的內容和方式,請參閱大量地址驗證文章。
使用 Memorystore 可提高復原能力,並處理更多地址。這個步驟會為整個處理管道新增狀態,處理非常龐大的地址資料集時需要用到。您也可以使用其他資料庫技術,例如 Cloud SQL[https://cloud.google.com/sql] 或 Google Cloud Platform 提供的任何其他資料庫類型。不過,我們認為 Memorystore 完美平衡了擴充性和簡便性需求,因此應該是首選。
結論
套用本文所述模式後,您就能在 Google Cloud Platform 上,針對不同用途使用 Address Validation API。
我們編寫了開放原始碼 Python 程式庫,協助您開始使用上述用途。您可以從電腦的指令列叫用,也可以從 Google Cloud Platform 或其他雲端服務供應商叫用。
如要進一步瞭解如何使用程式庫,請參閱這篇文章。
後續步驟
下載這份白皮書 ,並觀看這場網路研討會 ,瞭解如何運用可靠的地址資料,改善結帳、送貨和營運流程。
建議閱讀:
貢獻者
本文由 Google 維護。以下是這篇文章的原始撰寫者。
主要作者:
Henrik Valve | 解決方案工程師
Thomas Anglaret | 解決方案工程師
Sarthak Ganguly | 解決方案工程師