Introducción
En este documento, se describe cómo compilar una solución de selección de sitios combinando el conjunto de datos de Places Insights, los datos geoespaciales públicos en BigQuery y la API de Place Details.
Se basa en una demostración que se realizó en Google Cloud Next 2025 y que está disponible en YouTube. También está disponible un notebook de Colab de ejemplo, que contiene el código del proceso descrito en el documento, en un formato listo para ejecutarse.
El desafío empresarial
Imagina que tienes una cadena exitosa de cafeterías y quieres expandirte a un nuevo estado, como Nevada, donde no tienes presencia. Abrir una nueva ubicación es una inversión importante, y tomar una decisión basada en datos es fundamental para el éxito. ¿Cómo se puede comenzar?
En esta guía, se explica un análisis de varias capas para identificar la ubicación óptima de una nueva cafetería. Comenzaremos con una vista a nivel estatal, reduciremos progresivamente nuestra búsqueda a un condado y una zona comercial específicos y, por último, realizaremos un análisis hiperlocal para calificar áreas individuales y detectar brechas en el mercado a través del mapeo de la competencia.
Flujo de trabajo de la solución
Este proceso sigue un embudo lógico, que comienza con una búsqueda amplia y se vuelve cada vez más detallado para definir el área de búsqueda y aumentar la confianza en la selección final del sitio.
Requisitos previos y configuración del entorno
Antes de comenzar con el análisis, necesitas un entorno con algunas capacidades clave. Si bien esta guía te guiará por una implementación con SQL y Python, los principios generales se pueden aplicar a otras pilas de tecnología.
Como requisito previo, asegúrate de que tu entorno pueda hacer lo siguiente:
- Ejecutar consultas en BigQuery
- Accede a Places Insights. Para obtener más información, consulta Cómo configurar Places Insights.
- Suscríbete a los conjuntos de datos públicos de
bigquery-public-datay los totales de población por condado de la Oficina del Censo de EE.UU.
También debes poder visualizar datos geoespaciales en un mapa, lo que es fundamental para interpretar los resultados de cada paso analítico. Hay muchas formas de lograrlo. Puedes usar herramientas de BI, como Looker Studio, que se conectan directamente a BigQuery, o lenguajes de ciencia de datos, como Python.
Análisis a nivel estatal: Encuentra el mejor condado
Nuestro primer paso es realizar un análisis amplio para identificar el condado más prometedor de Nevada. Definiremos prometedor como una combinación de población alta y una alta densidad de restaurantes existentes, lo que indica una sólida cultura de alimentos y bebidas.
Nuestra consulta de BigQuery logra esto aprovechando los componentes de dirección integrados disponibles en el conjunto de datos de Places Insights. La consulta cuenta los restaurantes. Para ello, primero filtra los datos para incluir solo los lugares dentro del estado de Nevada, con el campo administrative_area_level_1_name. Luego, refina aún más este conjunto para incluir solo los lugares en los que el array de tipos contiene "restaurant". Por último, agrupa estos resultados por nombre del condado (administrative_area_level_2_name) para generar un recuento para cada condado. Este enfoque utiliza la estructura de direcciones integrada y preindexada del conjunto de datos.
En este fragmento, se muestra cómo unimos las geometrías de los condados con Estadísticas de Lugares y filtramos por un tipo de lugar específico, restaurant:
SELECT WITH AGGREGATION_THRESHOLD
administrative_area_level_2_name,
COUNT(*) AS restaurant_count
FROM
`places_insights___us.places`
WHERE
-- Filter for the state of Nevada
administrative_area_level_1_name = 'Nevada'
-- Filter for places that are restaurants
AND 'restaurant' IN UNNEST(types)
-- Filter for operational places only
AND business_status = 'OPERATIONAL'
-- Exclude rows where the county name is null
AND administrative_area_level_2_name IS NOT NULL
GROUP BY
administrative_area_level_2_name
ORDER BY
restaurant_count DESC
Un recuento sin procesar de los restaurantes no es suficiente; necesitamos equilibrarlo con los datos de población para tener una idea real de la saturación y las oportunidades del mercado. Usaremos datos de población de los totales de población por condado de la Oficina del Censo de EE.UU..
Para comparar estas dos métricas muy diferentes (un recuento de lugares y una gran cantidad de población), usamos la normalización min-max. Esta técnica ajusta ambas métricas a un rango común (de 0 a 1). Luego, las combinamos en un solo normalized_score, lo que le da a cada métrica un peso del 50% para una comparación equilibrada.
En este fragmento, se muestra la lógica principal para calcular la puntuación. Combina los recuentos normalizados de la población y los restaurantes:
(
-- Normalize restaurant count (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(restaurant_count - min_restaurants, max_restaurants - min_restaurants) * 0.5
+
-- Normalize population (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(population_2023 - min_pop, max_pop - min_pop) * 0.5
) AS normalized_score
Después de ejecutar la consulta completa, se muestra una lista de los condados, la cantidad de restaurantes, la población y la puntuación normalizada. Si se ordena por normalized_score
DESC, se revela que el condado de Clark es el ganador indiscutible para una mayor investigación como el principal contendiente.
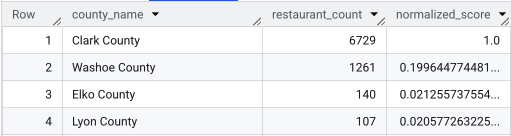
En esta captura de pantalla, se muestran los 4 condados principales según la puntuación normalizada. En este ejemplo, se omitió intencionalmente el recuento de población sin procesar.
Análisis a nivel del condado: Encuentra las zonas comerciales más concurridas
Ahora que identificamos el condado de Clark, el siguiente paso es acercar el mapa para encontrar los códigos postales con la mayor actividad comercial. Según los datos de nuestras cafeterías existentes, sabemos que el rendimiento es mejor cuando se encuentran cerca de una alta densidad de marcas importantes, por lo que usaremos esto como un indicador de alto tráfico de peatones.
Esta consulta usa la tabla brands de Estadísticas de Lugares, que contiene información sobre marcas específicas. Se puede consultar esta tabla para descubrir la lista de marcas admitidas. Primero, definimos una lista de nuestras marcas objetivo y, luego, la unimos al conjunto de datos principal de Places Insights para contar cuántas de estas tiendas específicas se encuentran dentro de cada código postal del condado de Clark.
La forma más eficiente de lograrlo es con un enfoque de dos pasos:
- Primero, realizaremos una agregación rápida no geoespacial para contar las marcas dentro de cada código postal.
- En segundo lugar, uniremos esos resultados a un conjunto de datos públicos para obtener los límites del mapa para la visualización.
Cómo contar marcas con el campo postal_code_names
Esta primera consulta realiza la lógica de recuento principal. Filtra los lugares en el condado de Clark y, luego, anula el anidamiento del array postal_code_names para agrupar los recuentos de marcas por código postal.
WITH brand_names AS (
-- First, select the chains we are interested in by name
SELECT
id,
name
FROM
`places_insights___us.brands`
WHERE
name IN ('7-Eleven', 'CVS', 'Walgreens', 'Subway Restaurants', "McDonald's")
)
SELECT WITH AGGREGATION_THRESHOLD
postal_code,
COUNT(*) AS total_brand_count
FROM
`places_insights___us.places` AS places_table,
-- Unnest the built-in postal code and brand ID arrays
UNNEST(places_table.postal_code_names) AS postal_code,
UNNEST(places_table.brand_ids) AS brand_id
JOIN
brand_names
ON brand_names.id = brand_id
WHERE
-- Filter directly on the administrative area fields in the places table
places_table.administrative_area_level_2_name = 'Clark County'
AND places_table.administrative_area_level_1_name = 'Nevada'
GROUP BY
postal_code
ORDER BY
total_brand_count DESC
El resultado es una tabla de códigos postales y sus recuentos de marcas correspondientes.

Adjunta geometrías de códigos postales para la asignación
Ahora que tenemos los recuentos, podemos obtener las formas de polígonos necesarias para la visualización. Esta segunda consulta toma nuestra primera consulta, la incluye en una expresión de tabla común (CTE) llamada brand_counts_by_zip y une sus resultados a la tabla pública geo_us_boundaries.zip_codes table. Esto adjunta de manera eficiente la geometría a nuestros recuentos precalculados.
WITH brand_counts_by_zip AS (
-- This will be the entire query from the previous step, without the final ORDER BY (excluded for brevity).
. . .
)
-- Now, join the aggregated results to the boundaries table
SELECT
counts.postal_code,
counts.total_brand_count,
-- Simplify the geometry for faster rendering in maps
ST_SIMPLIFY(zip_boundaries.zip_code_geom, 100) AS geography
FROM
brand_counts_by_zip AS counts
JOIN
`bigquery-public-data.geo_us_boundaries.zip_codes` AS zip_boundaries
ON counts.postal_code = zip_boundaries.zip_code
ORDER BY
counts.total_brand_count DESC
El resultado es una tabla de códigos postales, sus respectivos recuentos de marcas y la geometría del código postal.

Podemos visualizar estos datos como un mapa de calor. Las áreas de color rojo más oscuro indican una mayor concentración de nuestras marcas objetivo, lo que nos orienta hacia las zonas con mayor densidad comercial dentro de Las Vegas.

Análisis hiperlocal: Cómo calificar áreas de cuadrícula individuales
Una vez que identificamos el área general de Las Vegas, es hora de realizar un análisis detallado. Aquí es donde incorporamos nuestro conocimiento específico del negocio. Sabemos que una buena cafetería prospera cerca de otros negocios que están ocupados durante nuestras horas pico, como la mañana y el horario del almuerzo.
Nuestra próxima búsqueda es muy específica. Para comenzar, se crea una cuadrícula hexagonal detallada sobre el área metropolitana de Las Vegas con el índice geoespacial H3 estándar (con una resolución de 8) para analizar el área a nivel micro. Primero, la búsqueda identifica todos los negocios complementarios que están abiertos durante nuestro horario pico (lunes, de 10 a.m. a 2 p.m.).
Luego, aplicamos una puntuación ponderada a cada tipo de lugar. Un restaurante cercano es más valioso para nosotros que una tienda de conveniencia, por lo que recibe un multiplicador más alto. Esto nos proporciona un suitability_score personalizado para cada área pequeña.
En este fragmento, se destaca la lógica de puntuación ponderada, que hace referencia a una marca precalculada (is_open_monday_window) para la verificación del horario de atención:
. . .
(
COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 +
COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 +
COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 +
COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 +
COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7
) AS suitability_score
. . .
Expandir para ver la consulta completa
-- This query calculates a custom 'suitability score' for different areas in the Las Vegas -- metropolitan area to identify prime commercial zones. It uses a weighted model based -- on the density of specific business types that are open during a target time window. -- Step 1: Pre-filter the dataset to only include relevant places. -- This CTE finds all places in our target localities (Las Vegas, Spring Valley, etc.) and -- adds a boolean flag 'is_open_monday_window' for those open during the target time. WITH PlacesInTargetAreaWithOpenFlag AS ( SELECT point, types, EXISTS( SELECT 1 FROM UNNEST(regular_opening_hours.monday) AS monday_hours WHERE monday_hours.start_time <= TIME '10:00:00' AND monday_hours.end_time >= TIME '14:00:00' ) AS is_open_monday_window FROM `places_insights___us.places` WHERE EXISTS ( SELECT 1 FROM UNNEST(locality_names) AS locality WHERE locality IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester') ) AND administrative_area_level_1_name = 'Nevada' ), -- Step 2: Aggregate the filtered places into H3 cells and calculate the suitability score. -- Each place's location is converted to an H3 index (at resolution 8). The query then -- calculates a weighted 'suitability_score' and individual counts for each business type -- within that cell. TileScores AS ( SELECT WITH AGGREGATION_THRESHOLD -- Convert each place's geographic point into an H3 cell index. `carto-os.carto.H3_FROMGEOGPOINT`(point, 8) AS h3_index, -- Calculate the weighted score based on the count of places of each type -- that are open during the target window. ( COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 + COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 + COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 + COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 + COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7 ) AS suitability_score, -- Also return the individual counts for each category for detailed analysis. COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) AS restaurant_count, COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) AS convenience_store_count, COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) AS bar_count, COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) AS tourist_attraction_count, COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) AS casino_count FROM -- CHANGED: This now references the CTE with the expanded area. PlacesInTargetAreaWithOpenFlag -- Group by the H3 index to ensure all calculations are per-cell. GROUP BY h3_index ), -- Step 3: Find the maximum suitability score across all cells. -- This value is used in the next step to normalize the scores to a consistent scale (e.g., 0-10). MaxScore AS ( SELECT MAX(suitability_score) AS max_score FROM TileScores ) -- Step 4: Assemble the final results. -- This joins the scored tiles with the max score, calculates the normalized score, -- generates the H3 cell's polygon geometry for mapping, and orders the results. SELECT ts.h3_index, -- Generate the hexagonal polygon for the H3 cell for visualization. `carto-os.carto.H3_BOUNDARY`(ts.h3_index) AS h3_geography, ts.restaurant_count, ts.convenience_store_count, ts.bar_count, ts.tourist_attraction_count, ts.casino_count, ts.suitability_score, -- Normalize the score to a 0-10 scale for easier interpretation. ROUND( CASE WHEN ms.max_score = 0 THEN 0 ELSE (ts.suitability_score / ms.max_score) * 10 END, 2 ) AS normalized_suitability_score FROM -- A cross join is efficient here as MaxScore contains only one row. TileScores ts, MaxScore ms -- Display the highest-scoring locations first. ORDER BY normalized_suitability_score DESC;
La visualización de estas puntuaciones en un mapa revela ubicaciones ganadoras claras. Los mosaicos de color morado más oscuro, principalmente cerca del Strip de Las Vegas y el centro de la ciudad, son las áreas con el mayor potencial para nuestra nueva cafetería.
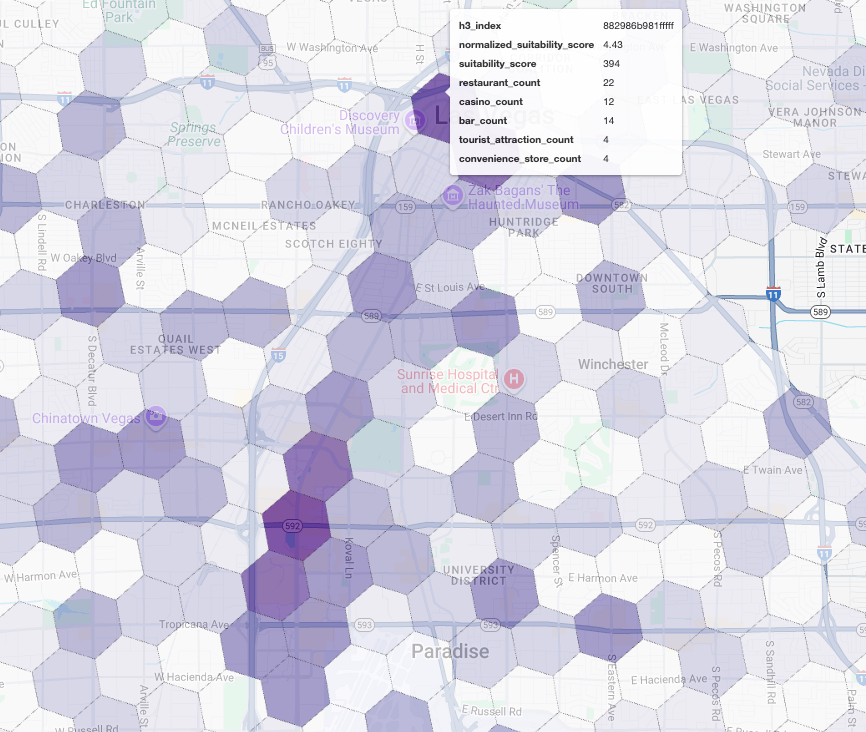
Análisis de la competencia: Identifica las cafeterías existentes
Nuestro modelo de idoneidad identificó correctamente las zonas más prometedoras, pero una puntuación alta por sí sola no garantiza el éxito. Ahora debemos superponer esta información con los datos de la competencia. La ubicación ideal es un área con alto potencial y baja densidad de cafeterías existentes, ya que buscamos una brecha de mercado clara.
Para lograrlo, usamos la función PLACES_COUNT_PER_H3. Esta función está diseñada para devolver de manera eficiente los recuentos de lugares dentro de una ubicación geográfica especificada, por celda H3.
Primero, definimos de forma dinámica la geografía de toda el área metropolitana de Las Vegas.
En lugar de depender de una sola localidad, consultamos el conjunto de datos públicos de Overture Maps para obtener los límites de Las Vegas y sus principales localidades circundantes, y los combinamos en un solo polígono con ST_UNION_AGG. Luego, pasamos esta área a la función y le pedimos que cuente todas las cafeterías operativas.
Esta consulta define el área metropolitana y llama a la función para obtener los recuentos de cafeterías en celdas H3:
-- Define a variable to hold the combined geography for the Las Vegas metro area.
DECLARE las_vegas_metro_area GEOGRAPHY;
-- Set the variable by fetching the shapes for the five localities from Overture Maps
-- and merging them into a single polygon using ST_UNION_AGG.
SET las_vegas_metro_area = (
SELECT
ST_UNION_AGG(geometry)
FROM
`bigquery-public-data.overture_maps.division_area`
WHERE
country = 'US'
AND region = 'US-NV'
AND names.primary IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester')
);
-- Call the PLACES_COUNT_PER_H3 function with our defined area and parameters.
SELECT
*
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
-- Use the metro area geography we just created.
'geography', las_vegas_metro_area,
-- Specify 'coffee_shop' as the place type to count.
'types', ["coffee_shop"],
-- Best practice: Only count places that are currently operational.
'business_status', ['OPERATIONAL'],
-- Set the H3 grid resolution to 8.
'h3_resolution', 8
)
);
La función devuelve una tabla que incluye el índice de la celda H3, su geometría, el recuento total de cafeterías y una muestra de sus IDs de lugar:

Si bien el recuento agregado es útil, es fundamental ver a los competidores reales.
Aquí es donde hacemos la transición del conjunto de datos de Places Insights a la API de Places. Si extraemos el sample_place_ids de las celdas con la puntuación de idoneidad normalizada más alta, podemos llamar a la API de Place Details para recuperar detalles enriquecidos de cada competidor, como su nombre, dirección, calificación y ubicación.
Esto requiere comparar los resultados de la búsqueda anterior, en la que se generó la puntuación de idoneidad, y la búsqueda PLACES_COUNT_PER_H3. El índice de celda H3 se puede usar para obtener los recuentos y los IDs de las cafeterías de las celdas con la puntuación de idoneidad normalizada más alta.
Este código de Python muestra cómo se podría realizar esta comparación.
# Isolate the Top 5 Most Suitable H3 Cells
top_suitability_cells = gdf_suitability.head(5)
# Extract the 'h3_index' values from these top 5 cells into a list.
top_h3_indexes = top_suitability_cells['h3_index'].tolist()
print(f"The top 5 H3 indexes are: {top_h3_indexes}")
# Now, we find the rows in our DataFrame where the
# 'h3_cell_index' matches one of the indexes from our top 5 list.
coffee_counts_in_top_zones = gdf_coffee_shops[
gdf_coffee_shops['h3_cell_index'].isin(top_h3_indexes)
]
Ahora que tenemos la lista de IDs de lugar de las cafeterías que ya existen en las celdas H3 con la puntuación de adecuación más alta, se pueden solicitar más detalles sobre cada lugar.
Esto se puede hacer enviando una solicitud directamente a la API de Place Details para cada ID de lugar o usando una biblioteca cliente para realizar la llamada. Recuerda establecer el parámetro FieldMask para solicitar solo los datos que necesitas.
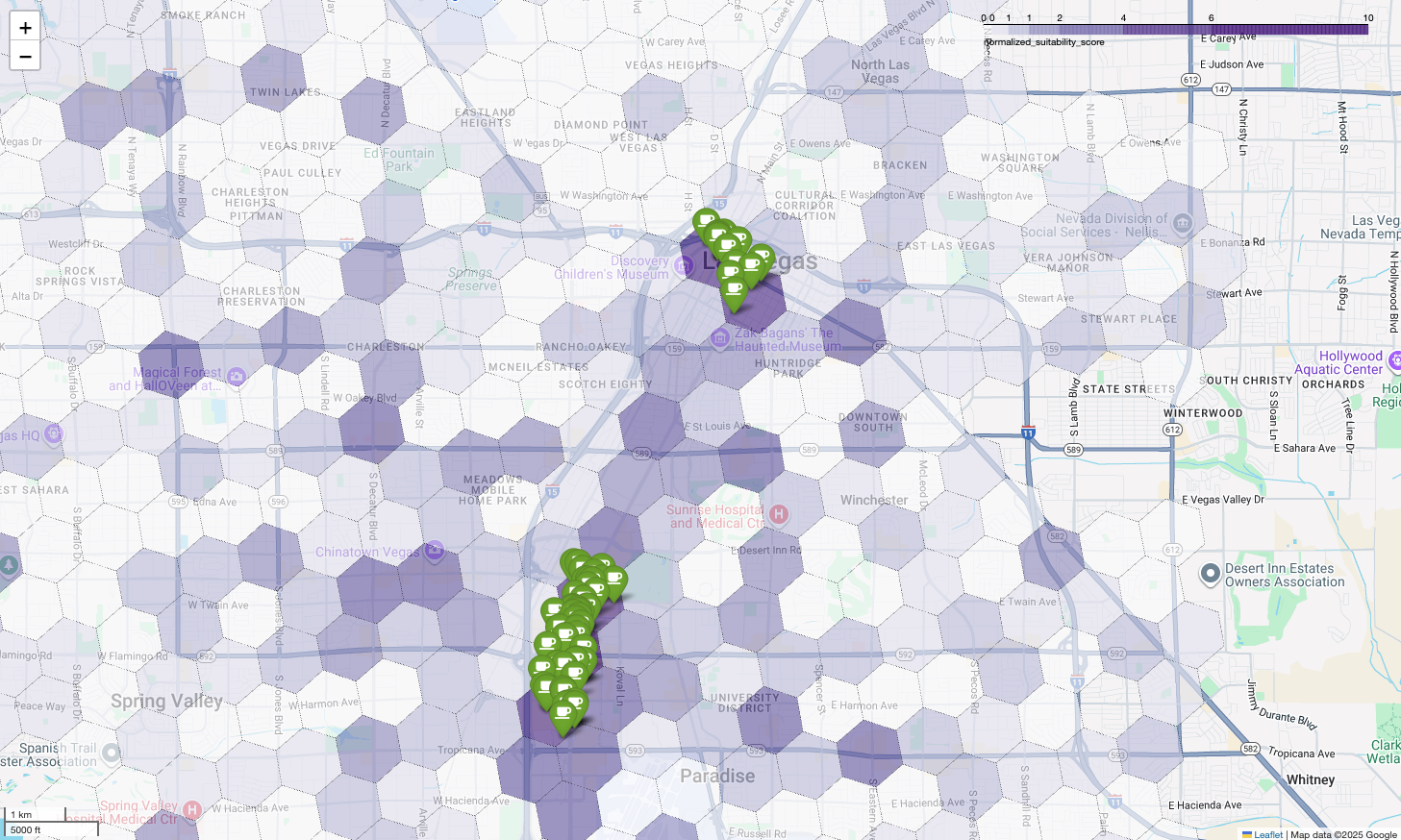
Por último, combinamos todo en una sola visualización potente. Trazamos nuestro mapa coropletas de idoneidad morado como la capa base y, luego, agregamos marcadores para cada cafetería individual recuperada de la API de Places. Este mapa final proporciona una vista general que sintetiza todo nuestro análisis: las áreas de color púrpura oscuro muestran el potencial y los pines verdes muestran la realidad del mercado actual.

Si buscamos celdas de color púrpura oscuro con pocos o ningún pin, podemos identificar con precisión las áreas exactas que representan la mejor oportunidad para nuestra nueva ubicación.

Las dos celdas anteriores tienen una puntuación de idoneidad alta, pero algunos espacios claros que podrían ser ubicaciones potenciales para nuestra nueva cafetería.
Conclusión
En este documento, pasamos de una pregunta a nivel estatal sobre dónde expandirnos a una respuesta local respaldada por datos. Si superpones diferentes conjuntos de datos y aplicas una lógica empresarial personalizada, puedes reducir de forma sistemática el riesgo asociado a una decisión empresarial importante. Este flujo de trabajo, que combina la escala de BigQuery, la riqueza de Places Insights y el detalle en tiempo real de la API de Places, proporciona una plantilla eficaz para cualquier organización que desee usar la inteligencia de ubicación para el crecimiento estratégico.
Próximos pasos
- Adapta este flujo de trabajo con tu propia lógica empresarial, las ubicaciones geográficas objetivo y los conjuntos de datos propietarios.
- Explora otros campos de datos en el conjunto de datos de Estadísticas de Lugares, como los recuentos de opiniones, los niveles de precios y las calificaciones de los usuarios, para enriquecer aún más tu modelo.
- Automatiza este proceso para crear un panel interno de selección de sitios que se pueda usar para evaluar mercados nuevos de forma dinámica.
Obtén más información en la documentación:
- Descripción general de Estadísticas de Places
- Funciones de Estadísticas de Lugares
- Análisis geoespacial de BigQuery
- API de Places
Colaboradores
Henrik Valve | Ingeniero de DevX