מבוא
במאמר הזה נסביר איך ליצור פתרון לבחירת מיקום על ידי שילוב של מערך הנתונים Places Insights, נתונים גיאוגרפיים ציבוריים ב-BigQuery ו-Place Details API.
הוא מבוסס על הדגמה שניתנה ב-Google Cloud Next 2025, שזמינה לצפייה ב-YouTube. יש גם דוגמה ל-Notebook של Colab, שכוללת את הקוד של התהליך שמתואר במסמך, בפורמט מוכן להפעלה.
האתגר העסקי
נניח שיש לכם רשת מצליחה של בתי קפה ואתם רוצים להתרחב למדינה חדשה, כמו נבדה, שבה אין לכם נוכחות. פתיחת מיקום חדש היא השקעה משמעותית, וקבלת החלטה שמבוססת על נתונים היא קריטית להצלחה. מאיפה מתחילים?
במדריך הזה נסביר איך לבצע ניתוח רב-שכבתי כדי לזהות את המיקום האופטימלי לפתיחת בית קפה חדש. נתחיל בתצוגה של כל המדינה, נצמצם בהדרגה את החיפוש למחוז ספציפי ולאזור מסחרי, ולבסוף נבצע ניתוח מקומי מאוד כדי לתת ציון לאזורים ספציפיים ולזהות פערים בשוק על ידי מיפוי המתחרים.
תהליך העבודה של הפתרון
התהליך הזה מתבצע לפי משפך לוגי, שמתחיל בחיפוש רחב ונעשה יותר ויותר ספציפי כדי לדייק את אזור החיפוש ולהגדיל את רמת הסמך בבחירת האתר הסופית.
דרישות מוקדמות והגדרת הסביבה
לפני שמתחילים בניתוח, צריך סביבה עם כמה יכולות מרכזיות. במדריך הזה נסביר איך להטמיע את הפתרון באמצעות SQL ו-Python, אבל אפשר ליישם את העקרונות הכלליים גם בטכנולוגיות אחרות.
כדרישה מוקדמת, צריך לוודא שהסביבה שלכם יכולה:
- הפעלת שאילתות ב-BigQuery.
- גישה למדדים של מקומות. מידע נוסף זמין במאמר הגדרת מדדים של מקומות.
- הרשמה למערכי נתונים ציבוריים מ-
bigquery-public-dataומ-US Census Bureau County Population Totals
צריך גם להיות מסוגלים להציג נתונים גיאוספציאליים בתרשים, וזה חיוני כדי לפרש את התוצאות של כל שלב בניתוח. יש הרבה דרכים לעשות את זה. אפשר להשתמש בכלים לבינה עסקית כמו Looker Studio שמתחברים ישירות ל-BigQuery, או בשפות של מדעי הנתונים כמו Python.
ניתוח ברמת המדינה: מציאת המחוז הטוב ביותר
השלב הראשון הוא ניתוח רחב כדי לזהות את המחוז המבטיח ביותר בנבאדה. אנחנו נגדיר מבטיח כשילוב של אוכלוסייה גדולה וצפיפות גבוהה של מסעדות קיימות, שמעיד על תרבות חזקה של מזון ומשקאות.
השאילתה שלנו ב-BigQuery עושה זאת באמצעות רכיבי הכתובת המובנים שזמינים במערך הנתונים Places Insights. השאילתה סופרת מסעדות אחרי סינון הנתונים כך שיכללו רק מקומות במדינת נבאדה, באמצעות השדה administrative_area_level_1_name. לאחר מכן, הוא מצמצם את קבוצת התוצאות כך שיכללו רק מקומות שבהם המערך types מכיל את הערך 'restaurant'. לבסוף, הוא מקבץ את התוצאות לפי שם המחוז (administrative_area_level_2_name) כדי ליצור ספירה לכל מחוז. הגישה הזו מתבססת על מבנה הכתובות המובנה והמאונדקס מראש של מערך הנתונים.
בקטע הזה אפשר לראות איך אנחנו משלבים גיאומטריות של מחוזות עם נתוני תובנות לגבי מקומות ומסננים
לפי סוג מקום ספציפי, restaurant:
SELECT WITH AGGREGATION_THRESHOLD
administrative_area_level_2_name,
COUNT(*) AS restaurant_count
FROM
`places_insights___us.places`
WHERE
-- Filter for the state of Nevada
administrative_area_level_1_name = 'Nevada'
-- Filter for places that are restaurants
AND 'restaurant' IN UNNEST(types)
-- Filter for operational places only
AND business_status = 'OPERATIONAL'
-- Exclude rows where the county name is null
AND administrative_area_level_2_name IS NOT NULL
GROUP BY
administrative_area_level_2_name
ORDER BY
restaurant_count DESC
ספירה גולמית של מסעדות לא מספיקה. אנחנו צריכים לאזן אותה עם נתוני אוכלוסייה כדי לקבל תמונה אמיתית של רוויית השוק וההזדמנויות בו. אנחנו נשתמש בנתוני אוכלוסייה מתוך הנתונים הכוללים של אוכלוסיית המחוזות של לשכת מפקד האוכלוסין בארה"ב.
כדי להשוות בין שני המדדים השונים מאוד האלה (מספר מקומות לעומת מספר גדול של אוכלוסייה), אנחנו משתמשים בנורמליזציה של מינימום-מקסימום. בטכניקה הזו, שני המדדים מותאמים לטווח משותף (0 עד 1). לאחר מכן אנחנו משלבים אותם במדד יחיד normalized_score, ונותנים לכל מדד משקל של 50% כדי להשוות בצורה מאוזנת.
בקטע הזה מוצגת הלוגיקה הבסיסית לחישוב הניקוד. הוא משלב בין נתונים מנורמלים של אוכלוסייה ומספר מסעדות:
(
-- Normalize restaurant count (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(restaurant_count - min_restaurants, max_restaurants - min_restaurants) * 0.5
+
-- Normalize population (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(population_2023 - min_pop, max_pop - min_pop) * 0.5
) AS normalized_score
אחרי שמריצים את השאילתה המלאה, מוחזרת רשימה של המחוזות, מספר המסעדות, האוכלוסייה והציון המנורמל. המיון לפי normalized_score
DESC מראה שמחוז קלארק הוא המנצח הברור, ולכן כדאי להמשיך לחקור אותו.
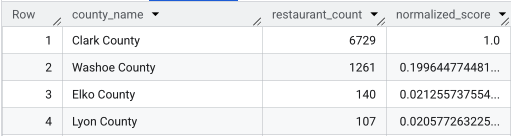
בצילום המסך הזה מוצגים 4 המחוזות המובילים לפי הציון המנורמל. במכוון לא צוין בדוגמה הזו מספר האכלוס הגולמי.
ניתוח ברמת המחוז: איתור האזורים המסחריים העמוסים ביותר
אחרי שזיהינו את מחוז קלארק, השלב הבא הוא להתקרב כדי למצוא את המיקודים עם הפעילות המסחרית הכי גבוהה. על סמך נתונים מבתי הקפה הקיימים שלנו, אנחנו יודעים שהביצועים טובים יותר כשהמיקום הוא ליד ריכוז גבוה של מותגים מובילים, ולכן נשתמש בזה כאינדיקטור למיקום עם תנועת לקוחות גבוהה.
השאילתה הזו משתמשת בטבלה brands בתובנות לגבי מקומות, שמכילה מידע על מותגים ספציפיים. אפשר להריץ שאילתות על הטבלה הזו כדי לראות את רשימת המותגים הנתמכים. קודם כל אנחנו מגדירים רשימה של המותגים שאנחנו רוצים לטרגט, ואז משלבים אותה עם מערך הנתונים הראשי של Places Insights כדי לספור כמה מהחנויות הספציפיות האלה נמצאות בכל מיקוד במחוז קלארק.
הדרך היעילה ביותר לעשות זאת היא באמצעות גישה דו-שלבית:
- קודם כל, נבצע צבירה מהירה ללא מיקום גיאוגרפי כדי לספור את המותגים בכל מיקוד.
- בשלב השני, נצרף את התוצאות האלה למערך נתונים ציבורי כדי לקבל את גבולות המפה לצורך ויזואליזציה.
ספירת מותגים באמצעות השדה postal_code_names
השאילתה הראשונה הזו מבצעת את הלוגיקה הבסיסית של הספירה. הוא מסנן מקומות במחוז קלארק ואז מבטל את הקינון של מערך postal_code_names כדי לקבץ את ספירת המותגים לפי מיקוד.
WITH brand_names AS (
-- First, select the chains we are interested in by name
SELECT
id,
name
FROM
`places_insights___us.brands`
WHERE
name IN ('7-Eleven', 'CVS', 'Walgreens', 'Subway Restaurants', "McDonald's")
)
SELECT WITH AGGREGATION_THRESHOLD
postal_code,
COUNT(*) AS total_brand_count
FROM
`places_insights___us.places` AS places_table,
-- Unnest the built-in postal code and brand ID arrays
UNNEST(places_table.postal_code_names) AS postal_code,
UNNEST(places_table.brand_ids) AS brand_id
JOIN
brand_names
ON brand_names.id = brand_id
WHERE
-- Filter directly on the administrative area fields in the places table
places_table.administrative_area_level_2_name = 'Clark County'
AND places_table.administrative_area_level_1_name = 'Nevada'
GROUP BY
postal_code
ORDER BY
total_brand_count DESC
הפלט הוא טבלה של מיקודים ומספר המותגים התואם.
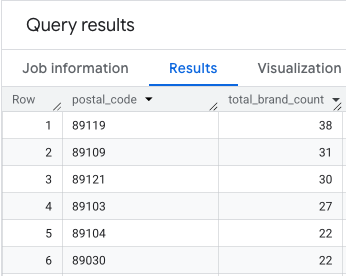
צירוף גיאומטריות של מיקוד למיפוי
עכשיו, אחרי שיש לנו את המספרים, אנחנו יכולים לקבל את צורות המצולעים שדרושות להצגה חזותית. השאילתה השנייה מתבססת על השאילתה הראשונה, היא עוטפת אותה בביטוי טבלה משותף (CTE) בשם brand_counts_by_zip ומצמידה את התוצאות שלה לטבלה הציבורית geo_us_boundaries.zip_codes table. כך מצורפת הגיאומטריה בצורה יעילה למספרים שחישבנו מראש.
WITH brand_counts_by_zip AS (
-- This will be the entire query from the previous step, without the final ORDER BY (excluded for brevity).
. . .
)
-- Now, join the aggregated results to the boundaries table
SELECT
counts.postal_code,
counts.total_brand_count,
-- Simplify the geometry for faster rendering in maps
ST_SIMPLIFY(zip_boundaries.zip_code_geom, 100) AS geography
FROM
brand_counts_by_zip AS counts
JOIN
`bigquery-public-data.geo_us_boundaries.zip_codes` AS zip_boundaries
ON counts.postal_code = zip_boundaries.zip_code
ORDER BY
counts.total_brand_count DESC
הפלט הוא טבלה של מיקודים, מספר המותגים התואם לכל מיקוד והגיאומטריה של המיקוד.

אנחנו יכולים להציג את הנתונים האלה בצורה ויזואלית כמפת חום. האזורים באדום כהה מציינים ריכוז גבוה יותר של המותגים שאנחנו רוצים למשוך, ומצביעים על האזורים עם הצפיפות המסחרית הגבוהה ביותר בלאס וגאס.

ניתוח היפר-לוקאלי: ניקוד של אזורים ספציפיים ברשת
אחרי שזיהינו את האזור הכללי של לאס וגאס, הגיע הזמן לניתוח מפורט. כאן אנחנו משלבים את הידע העסקי הספציפי שלנו. אנחנו יודעים שבית קפה מצליח צריך להיות קרוב לעסקים אחרים שפעילים בשעות השיא שלנו, כמו שעות הבוקר המאוחרות והצהריים.
השאילתה הבאה שלנו מאוד ספציפית. התהליך מתחיל ביצירת רשת משושים מפורטת מעל האזור המטרופוליני של לאס וגאס באמצעות אינדקס גיאוגרפי מרחבי רגיל של H3 (ברזולוציה 8) כדי לנתח את האזור ברמת המיקרו. השאילתה מזהה קודם את כל העסקים המשלימים שפתוחים במהלך חלון הזמן העמוס שלנו (יום שני, 10:00 עד 14:00).
לאחר מכן אנחנו משתמשים בניקוד משוקלל לכל סוג מקום. מסעדה בקרבת מקום חשובה לנו יותר מחנות נוחות, ולכן היא מקבלת מכפיל גבוה יותר. כך אנחנו מקבלים suitability_score בהתאמה אישית לכל אזור קטן.
בקטע הזה מודגשת הלוגיקה של הניקוד המשוקלל, שמתייחס לדגל שחושב מראש (is_open_monday_window) לבדיקת שעות הפתיחה:
. . .
(
COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 +
COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 +
COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 +
COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 +
COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7
) AS suitability_score
. . .
הרחבה להצגת השאילתה המלאה
-- This query calculates a custom 'suitability score' for different areas in the Las Vegas -- metropolitan area to identify prime commercial zones. It uses a weighted model based -- on the density of specific business types that are open during a target time window. -- Step 1: Pre-filter the dataset to only include relevant places. -- This CTE finds all places in our target localities (Las Vegas, Spring Valley, etc.) and -- adds a boolean flag 'is_open_monday_window' for those open during the target time. WITH PlacesInTargetAreaWithOpenFlag AS ( SELECT point, types, EXISTS( SELECT 1 FROM UNNEST(regular_opening_hours.monday) AS monday_hours WHERE monday_hours.start_time <= TIME '10:00:00' AND monday_hours.end_time >= TIME '14:00:00' ) AS is_open_monday_window FROM `places_insights___us.places` WHERE EXISTS ( SELECT 1 FROM UNNEST(locality_names) AS locality WHERE locality IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester') ) AND administrative_area_level_1_name = 'Nevada' ), -- Step 2: Aggregate the filtered places into H3 cells and calculate the suitability score. -- Each place's location is converted to an H3 index (at resolution 8). The query then -- calculates a weighted 'suitability_score' and individual counts for each business type -- within that cell. TileScores AS ( SELECT WITH AGGREGATION_THRESHOLD -- Convert each place's geographic point into an H3 cell index. `carto-os.carto.H3_FROMGEOGPOINT`(point, 8) AS h3_index, -- Calculate the weighted score based on the count of places of each type -- that are open during the target window. ( COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 + COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 + COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 + COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 + COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7 ) AS suitability_score, -- Also return the individual counts for each category for detailed analysis. COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) AS restaurant_count, COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) AS convenience_store_count, COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) AS bar_count, COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) AS tourist_attraction_count, COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) AS casino_count FROM -- CHANGED: This now references the CTE with the expanded area. PlacesInTargetAreaWithOpenFlag -- Group by the H3 index to ensure all calculations are per-cell. GROUP BY h3_index ), -- Step 3: Find the maximum suitability score across all cells. -- This value is used in the next step to normalize the scores to a consistent scale (e.g., 0-10). MaxScore AS ( SELECT MAX(suitability_score) AS max_score FROM TileScores ) -- Step 4: Assemble the final results. -- This joins the scored tiles with the max score, calculates the normalized score, -- generates the H3 cell's polygon geometry for mapping, and orders the results. SELECT ts.h3_index, -- Generate the hexagonal polygon for the H3 cell for visualization. `carto-os.carto.H3_BOUNDARY`(ts.h3_index) AS h3_geography, ts.restaurant_count, ts.convenience_store_count, ts.bar_count, ts.tourist_attraction_count, ts.casino_count, ts.suitability_score, -- Normalize the score to a 0-10 scale for easier interpretation. ROUND( CASE WHEN ms.max_score = 0 THEN 0 ELSE (ts.suitability_score / ms.max_score) * 10 END, 2 ) AS normalized_suitability_score FROM -- A cross join is efficient here as MaxScore contains only one row. TileScores ts, MaxScore ms -- Display the highest-scoring locations first. ORDER BY normalized_suitability_score DESC;
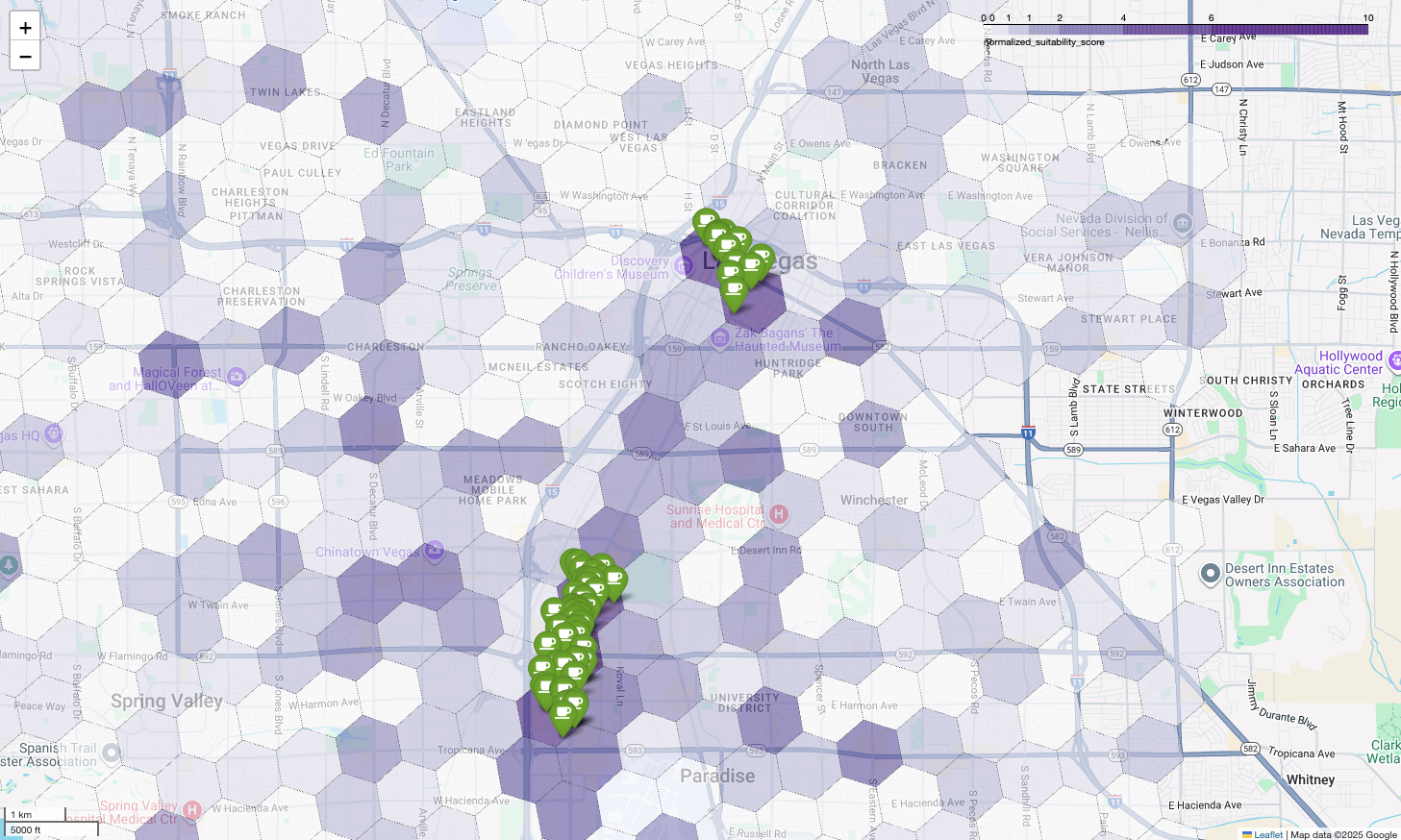
הצגת הנתונים האלה במפה מאפשרת לראות בבירור את המיקומים המומלצים. המשבצות הסגולות הכהות ביותר, בעיקר ליד הסטריפ של לאס וגאס ובמרכז העיר, הן האזורים עם הפוטנציאל הכי גבוה לפתיחת בית קפה חדש.

ניתוח של המתחרים: זיהוי בתי קפה קיימים
המודל שלנו לזיהוי אזורים מתאימים זיהה בהצלחה את האזורים המבטיחים ביותר, אבל ציון גבוה כשלעצמו לא מבטיח הצלחה. עכשיו אנחנו צריכים להוסיף לזה נתונים של המתחרים. המיקום האידיאלי הוא אזור עם פוטנציאל גבוה וצפיפות נמוכה של בתי קפה קיימים, כי אנחנו מחפשים פער ברור בשוק.
כדי לעשות את זה, אנחנו משתמשים בפונקציה PLACES_COUNT_PER_H3. הפונקציה הזו נועדה להחזיר ביעילות את מספר המקומות באזור גיאוגרפי מוגדר, לפי תא H3.
קודם כל, אנחנו מגדירים באופן דינמי את המיקום הגיאוגרפי של כל אזור המטרופולין של לאס וגאס.
במקום להסתמך על אזור מקומי יחיד, אנחנו שולחים שאילתה למערך הנתונים הציבורי של Overture Maps כדי לקבל את הגבולות של לאס וגאס ושל האזורים המקומיים העיקריים שמסביב, וממזגים אותם למצולע יחיד עם ST_UNION_AGG. לאחר מכן מעבירים את האזור הזה לפונקציה ומבקשים ממנה לספור את כל בתי הקפה הפעילים.
השאילתה הזו מגדירה את האזור המטרופוליטני ומפעילה את הפונקציה כדי לקבל את מספר בתי הקפה בתאי H3:
-- Define a variable to hold the combined geography for the Las Vegas metro area.
DECLARE las_vegas_metro_area GEOGRAPHY;
-- Set the variable by fetching the shapes for the five localities from Overture Maps
-- and merging them into a single polygon using ST_UNION_AGG.
SET las_vegas_metro_area = (
SELECT
ST_UNION_AGG(geometry)
FROM
`bigquery-public-data.overture_maps.division_area`
WHERE
country = 'US'
AND region = 'US-NV'
AND names.primary IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester')
);
-- Call the PLACES_COUNT_PER_H3 function with our defined area and parameters.
SELECT
*
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
-- Use the metro area geography we just created.
'geography', las_vegas_metro_area,
-- Specify 'coffee_shop' as the place type to count.
'types', ["coffee_shop"],
-- Best practice: Only count places that are currently operational.
'business_status', ['OPERATIONAL'],
-- Set the H3 grid resolution to 8.
'h3_resolution', 8
)
);
הפונקציה מחזירה טבלה שכוללת את אינדקס התא של H3, את הגיאומטריה שלו, את המספר הכולל של בתי הקפה ודוגמה של מזהי המקומות שלהם:

הספירה המצטברת שימושית, אבל חשוב לראות את המתחרים בפועל.
כאן אנחנו עוברים ממערך הנתונים של Places Insights אל Places API. על ידי חילוץ ה-sample_place_ids מהתאים עם ציון ההתאמה המנורמל הגבוה ביותר, אפשר להפעיל את Place Details
API כדי לאחזר פרטים מפורטים על כל מתחרה, כמו השם, הכתובת, הדירוג והמיקום שלו.
לשם כך צריך להשוות בין התוצאות של השאילתה הקודמת, שבה נוצר ציון ההתאמה, לבין השאילתה PLACES_COUNT_PER_H3. אפשר להשתמש באינדקס של תאי H3 כדי לקבל את מספר בתי הקפה ואת המזהים שלהם מהתאים עם ציון ההתאמה המנורמל הגבוה ביותר.
קוד Python הזה מדגים איך אפשר לבצע את ההשוואה הזו.
# Isolate the Top 5 Most Suitable H3 Cells
top_suitability_cells = gdf_suitability.head(5)
# Extract the 'h3_index' values from these top 5 cells into a list.
top_h3_indexes = top_suitability_cells['h3_index'].tolist()
print(f"The top 5 H3 indexes are: {top_h3_indexes}")
# Now, we find the rows in our DataFrame where the
# 'h3_cell_index' matches one of the indexes from our top 5 list.
coffee_counts_in_top_zones = gdf_coffee_shops[
gdf_coffee_shops['h3_cell_index'].isin(top_h3_indexes)
]
עכשיו יש לנו רשימה של מזהי מקומות של בתי קפה שכבר קיימים בתאי H3 עם ציון ההתאמה הכי גבוה. אפשר לבקש פרטים נוספים על כל מקום.
אפשר לעשות את זה בשתי דרכים: לשלוח בקשה ישירות אל Place Details API לכל מזהה מקום, או להשתמש ב-Client Library כדי לבצע את הקריאה. חשוב לזכור להגדיר את הפרמטר
FieldMask
כך שרק הנתונים שאתם צריכים ייכללו בבקשה.
בסוף, אנחנו משלבים את הכול להמחשה אחת עוצמתית. אנחנו יוצרים מפת קורופלת סגולה של מידת ההתאמה כשכבת הבסיס, ואז מוסיפים סיכות לכל בית קפה בנפרד שאוחזר מ-Places API. המפה הסופית הזו מספקת מבט מהיר שמסכם את כל הניתוח שלנו: האזורים הסגולים הכהים מראים את הפוטנציאל, והסיכות הירוקות מראות את המצב בפועל בשוק הנוכחי.

אם מחפשים תאים בצבע סגול כהה עם מעט סיכות או ללא סיכות, אפשר לזהות בוודאות את האזורים המדויקים שמייצגים את ההזדמנות הטובה ביותר למיקום החדש שלנו.
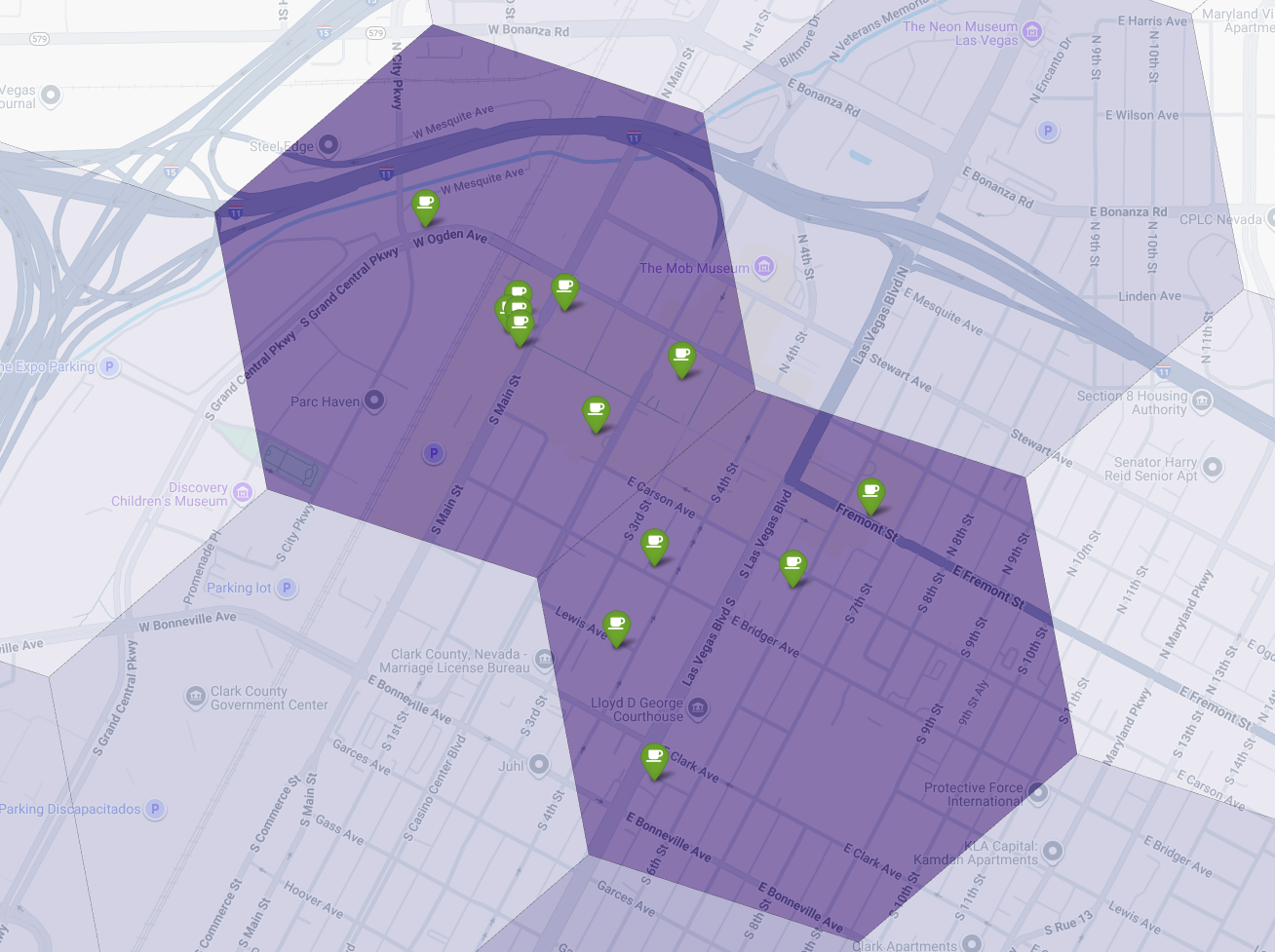
לשני התאים שלמעלה יש ציון התאמה גבוה, אבל יש בהם כמה פערים ברורים שיכולים להיות מיקומים פוטנציאליים לבית הקפה החדש שלנו.
סיכום
במסמך הזה, עברנו משאלה כללית לגבי המיקום שבו כדאי להרחיב את העסק לתשובה מקומית שמבוססת על נתונים. באמצעות שילוב של מערכי נתונים שונים והחלת לוגיקה עסקית מותאמת אישית, אפשר לצמצם באופן שיטתי את הסיכון שקשור להחלטה עסקית חשובה. תהליך העבודה הזה, שמשלב את היכולות של BigQuery, את המידע המפורט של Places Insights ואת הנתונים בזמן אמת של Places API, מספק תבנית יעילה לכל ארגון שרוצה להשתמש במידע על מיקום לצורך צמיחה אסטרטגית.
השלבים הבאים
- אפשר להתאים את תהליך העבודה הזה ללוגיקה העסקית שלכם, למיקומים הגיאוגרפיים ולמערכי הנתונים הקנייניים שלכם.
- כדי להעשיר עוד יותר את המודל, אפשר לעיין בשדות נתונים אחרים במערך הנתונים של תובנות לגבי מקומות, כמו מספר הביקורות, רמות המחירים ודירוגי המשתמשים.
- אפשר להפוך את התהליך הזה לאוטומטי כדי ליצור מרכז בקרה פנימי לבחירת אתרים, שבעזרתו אפשר להעריך שווקים חדשים באופן דינמי.
מידע נוסף זמין במסמכי התיעוד:
- סקירה כללית של תובנות לגבי מקומות
- פונקציות של Places Insights
- ניתוח נתונים גיאוגרפיים ב-BigQuery
- Places API
תורמים
Henrik Valve | DevX Engineer