Wprowadzenie
W tym dokumencie opisujemy, jak stworzyć rozwiązanie do wyboru lokalizacji, łącząc zbiór danych Statystyki miejsc, publiczne dane geoprzestrzenne w BigQuery i interfejs Places Details API.
Jest on oparty na demonstracji przedstawionej na konferencji Google Cloud Next 2025, którą można obejrzeć w YouTube.
Wyzwanie biznesowe
Wyobraź sobie, że jesteś właścicielem dobrze prosperującej sieci kawiarni i chcesz rozszerzyć działalność na nowy stan, np. Nevadę, w którym nie masz jeszcze żadnej placówki. Otwarcie nowej lokalizacji to poważna inwestycja, dlatego podejmowanie decyzji na podstawie danych ma kluczowe znaczenie dla sukcesu. Od czego zacząć?
Ten przewodnik przeprowadzi Cię przez wielowarstwową analizę, która pomoże Ci znaleźć optymalną lokalizację dla nowej kawiarni. Zaczniemy od widoku obejmującego całe województwo, stopniowo zawężając wyszukiwanie do konkretnego powiatu i strefy handlowej, a na koniec przeprowadzimy analizę hiperlokalną, aby ocenić poszczególne obszary i zidentyfikować luki rynkowe poprzez wyznaczenie konkurencji.
Przepływ pracy rozwiązania
Ten proces przebiega zgodnie z logicznym schematem, zaczynając od szerokiego zakresu i stopniowo zwiększając szczegółowość, aby zawęzić obszar wyszukiwania i zwiększyć pewność co do ostatecznego wyboru witryny.
Wymagania wstępne i konfiguracja środowiska
Zanim przejdziesz do analizy, musisz mieć środowisko z kilkoma kluczowymi funkcjami. W tym przewodniku opisujemy implementację z użyciem SQL i Pythona, ale ogólne zasady można stosować w przypadku innych stosów technologii.
Wymagania wstępne:
- wykonywać zapytania w BigQuery;
- Dostęp do Statystyk miejsc – więcej informacji znajdziesz w sekcji Konfigurowanie Statystyk miejsc.
- Subskrybuj publiczne zbiory danych z
bigquery-public-datai US Census Bureau County Population Totals.
Musisz też mieć możliwość wizualizacji danych geoprzestrzennych na mapie, co jest kluczowe dla interpretacji wyników każdego etapu analizy. Możesz to zrobić na wiele sposobów. Możesz używać narzędzi BI, takich jak Looker Studio, które łączą się bezpośrednio z BigQuery, lub języków do analizy danych, takich jak Python.
Analiza na poziomie stanu: znajdź najlepsze hrabstwo
Pierwszym krokiem jest przeprowadzenie szerokiej analizy, aby zidentyfikować najbardziej obiecujące hrabstwo w Nevadzie. Obiecujące miejsce to takie, które ma dużą populację i dużą gęstość istniejących restauracji, co wskazuje na silną kulturę gastronomiczną.
Nasze zapytanie BigQuery osiąga ten cel, wykorzystując wbudowane komponenty adresu dostępne w zbiorze danych Statystyki miejsc. Zapytanie zlicza restauracje, najpierw filtrując dane, aby uwzględnić tylko miejsca w stanie Nevada, za pomocą pola administrative_area_level_1_name. Następnie zawęża ten zbiór, aby uwzględniał tylko miejsca, w których tablica typów zawiera wartość „restaurant”. Na koniec grupuje te wyniki według nazwy hrabstwa (administrative_area_level_2_name), aby uzyskać liczbę dla każdego hrabstwa. To podejście wykorzystuje wbudowaną, wstępnie indeksowaną strukturę adresów w zbiorze danych.
Ten fragment pokazuje, jak łączymy geometrię hrabstw z informacjami o miejscach i filtrujemy je pod kątem określonego typu miejsca, restaurant:
SELECT WITH AGGREGATION_THRESHOLD
administrative_area_level_2_name,
COUNT(*) AS restaurant_count
FROM
`places_insights___us.places`
WHERE
-- Filter for the state of Nevada
administrative_area_level_1_name = 'Nevada'
-- Filter for places that are restaurants
AND 'restaurant' IN UNNEST(types)
-- Filter for operational places only
AND business_status = 'OPERATIONAL'
-- Exclude rows where the county name is null
AND administrative_area_level_2_name IS NOT NULL
GROUP BY
administrative_area_level_2_name
ORDER BY
restaurant_count DESC
Sama liczba restauracji nie wystarczy. Musimy ją zrównoważyć z danymi o populacji, aby uzyskać prawdziwy obraz nasycenia rynku i możliwości. Będziemy korzystać z danych o populacji z amerykańskiego biura ewidencji ludności (US Census Bureau).
Aby porównać te 2 bardzo różne rodzaje danych (liczbę miejsc z dużą liczbą ludności), stosujemy normalizację min-max. Ta technika skaluje oba rodzaje danych do wspólnego zakresu (od 0 do 1). Następnie łączymy je w jeden wskaźniknormalized_score, przypisując każdemu z nich wagę 50% w celu uzyskania zrównoważonego porównania.
Ten fragment pokazuje podstawową logikę obliczania wyniku. Łączy on znormalizowaną liczbę mieszkańców i restauracji:
(
-- Normalize restaurant count (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(restaurant_count - min_restaurants, max_restaurants - min_restaurants) * 0.5
+
-- Normalize population (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(population_2023 - min_pop, max_pop - min_pop) * 0.5
) AS normalized_score
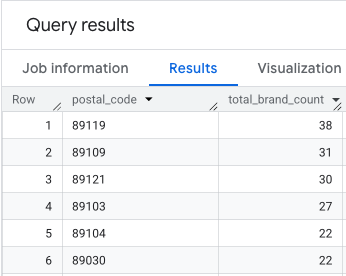
Po uruchomieniu pełnego zapytania zwracana jest lista hrabstw, liczba restauracji, populacja i znormalizowany wynik. Sortowanie według normalized_score
DESC pokazuje, że Hrabstwo Clark jest zdecydowanym zwycięzcą, który wymaga dalszej analizy jako główny kandydat.

Ten zrzut ekranu pokazuje 4 najlepsze hrabstwa według wyniku znormalizowanego. W tym przykładzie celowo pominięto liczbę nieprzetworzonych danych o populacji.
Analiza na poziomie hrabstwa: znajdź najbardziej ruchliwe strefy handlowe
Po zidentyfikowaniu hrabstwa Clark kolejnym krokiem jest powiększenie widoku, aby znaleźć kody pocztowe o największej aktywności komercyjnej. Na podstawie danych z naszych obecnych kawiarni wiemy, że lepsze wyniki osiągają te, które znajdują się w pobliżu wielu znanych marek. Dlatego wykorzystamy to jako wskaźnik dużego natężenia ruchu pieszego.
To zapytanie korzysta z tabeli brands w ramach Statystyk miejsc, która zawiera informacje o konkretnych markach. Tę tabelę można przeszukiwać, aby znaleźć listę obsługiwanych marek. Najpierw definiujemy listę docelowych marek, a następnie łączymy ją z głównym zbiorem danych Statystyk miejsc, aby policzyć, ile konkretnych sklepów znajduje się w poszczególnych kodach pocztowych w hrabstwie Clark.
Najskuteczniejszym sposobem na to jest dwuetapowe podejście:
- Najpierw przeprowadzimy szybką agregację bez odniesienia do przestrzeni geograficznej, aby zliczyć marki w każdym kodzie pocztowym.
- Następnie połączymy te wyniki z publicznym zbiorem danych, aby uzyskać granice mapy do wizualizacji.
Zliczanie marek za pomocą pola postal_code_names
To pierwsze zapytanie wykonuje podstawową logikę zliczania. Filtruje miejsca w hrabstwie Clark, a następnie rozpakowuje tablicę postal_code_names, aby pogrupować liczbę wystąpień marki według kodu pocztowego.
WITH brand_names AS (
-- First, select the chains we are interested in by name
SELECT
id,
name
FROM
`places_insights___us.brands`
WHERE
name IN ('7-Eleven', 'CVS', 'Walgreens', 'Subway Restaurants', "McDonald's")
)
SELECT WITH AGGREGATION_THRESHOLD
postal_code,
COUNT(*) AS total_brand_count
FROM
`places_insights___us.places` AS places_table,
-- Unnest the built-in postal code and brand ID arrays
UNNEST(places_table.postal_code_names) AS postal_code,
UNNEST(places_table.brand_ids) AS brand_id
JOIN
brand_names
ON brand_names.id = brand_id
WHERE
-- Filter directly on the administrative area fields in the places table
places_table.administrative_area_level_2_name = 'Clark County'
AND places_table.administrative_area_level_1_name = 'Nevada'
GROUP BY
postal_code
ORDER BY
total_brand_count DESC
Wynikiem jest tabela kodów pocztowych i odpowiadających im liczb marek.
Dołączanie geometrii kodów pocztowych do mapowania
Teraz, gdy mamy już liczby, możemy uzyskać kształty wielokątów potrzebne do wizualizacji. To drugie zapytanie wykorzystuje pierwsze zapytanie, umieszcza je w zapytaniu CTE (Common Table Expression) o nazwie brand_counts_by_zip i złącza jego wyniki z publiczną tabelą geo_us_boundaries.zip_codes table. Dzięki temu możemy skutecznie przypisywać geometrię do wstępnie obliczonych wartości.
WITH brand_counts_by_zip AS (
-- This will be the entire query from the previous step, without the final ORDER BY (excluded for brevity).
. . .
)
-- Now, join the aggregated results to the boundaries table
SELECT
counts.postal_code,
counts.total_brand_count,
-- Simplify the geometry for faster rendering in maps
ST_SIMPLIFY(zip_boundaries.zip_code_geom, 100) AS geography
FROM
brand_counts_by_zip AS counts
JOIN
`bigquery-public-data.geo_us_boundaries.zip_codes` AS zip_boundaries
ON counts.postal_code = zip_boundaries.zip_code
ORDER BY
counts.total_brand_count DESC
Wynikiem jest tabela kodów pocztowych, odpowiadających im liczb marek i geometrii kodów pocztowych.

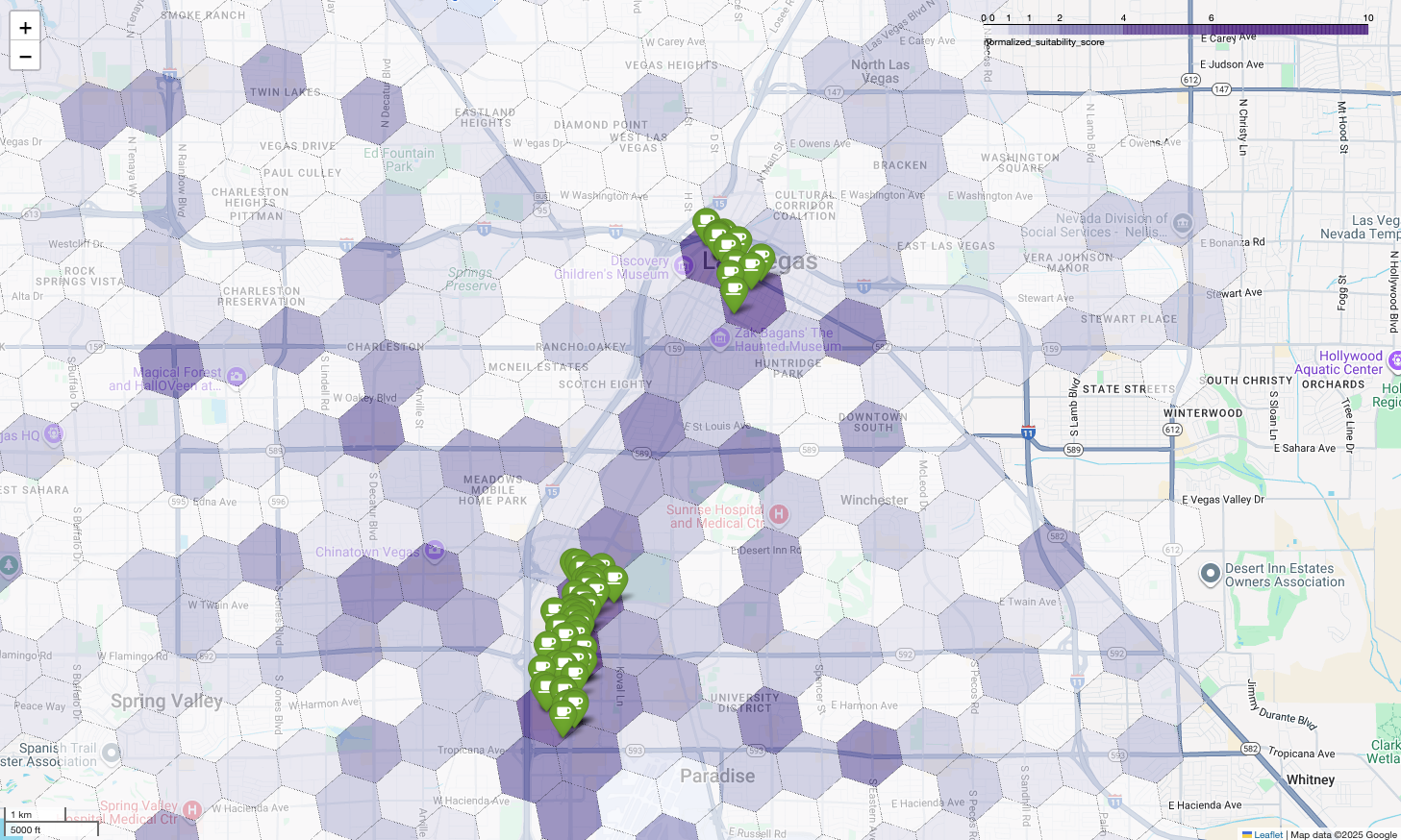
Możemy wizualizować te dane w postaci mapy termicznej. Ciemniejsze czerwone obszary wskazują większe zagęszczenie naszych docelowych marek, co kieruje nas do najbardziej komercyjnych stref w Las Vegas.

Analiza hiperlokalna: ocena poszczególnych obszarów siatki
Po określeniu ogólnego obszaru Las Vegas czas na szczegółową analizę. W tym miejscu dodajemy naszą specjalistyczną wiedzę biznesową. Wiemy, że dobra kawiarnia dobrze prosperuje w pobliżu innych firm, które są oblegane w godzinach szczytu, np. późnym rankiem i w porze lunchu.
Następne zapytanie jest bardzo konkretne. Zaczyna się od utworzenia szczegółowej siatki sześciokątnej nad obszarem metropolitalnym Las Vegas przy użyciu standardowego indeksu geoprzestrzennego H3 (w rozdzielczości 8), aby analizować obszar na poziomie mikro. Zapytanie najpierw identyfikuje wszystkie firmy uzupełniające, które są otwarte w godzinach szczytu (poniedziałek, 10:00–14:00).
Następnie przypisujemy do każdego typu miejsca ważoną ocenę. Pobliska restauracja jest dla nas bardziej wartościowa niż sklep ogólnospożywczy, dlatego otrzymuje wyższy mnożnik. Dzięki temu w przypadku każdego małego obszaru uzyskujemy niestandardowy suitability_score.
Ten fragment zawiera logikę ważonego oceniania, która odwołuje się do wstępnie obliczonej flagi (is_open_monday_window) sprawdzania godzin otwarcia:
. . .
(
COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 +
COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 +
COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 +
COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 +
COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7
) AS suitability_score
. . .
Rozwiń, aby wyświetlić pełne zapytanie
-- This query calculates a custom 'suitability score' for different areas in the Las Vegas -- metropolitan area to identify prime commercial zones. It uses a weighted model based -- on the density of specific business types that are open during a target time window. -- Step 1: Pre-filter the dataset to only include relevant places. -- This CTE finds all places in our target localities (Las Vegas, Spring Valley, etc.) and -- adds a boolean flag 'is_open_monday_window' for those open during the target time. WITH PlacesInTargetAreaWithOpenFlag AS ( SELECT point, types, EXISTS( SELECT 1 FROM UNNEST(regular_opening_hours.monday) AS monday_hours WHERE monday_hours.start_time <= TIME '10:00:00' AND monday_hours.end_time >= TIME '14:00:00' ) AS is_open_monday_window FROM `places_insights___us.places` WHERE EXISTS ( SELECT 1 FROM UNNEST(locality_names) AS locality WHERE locality IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester') ) AND administrative_area_level_1_name = 'Nevada' ), -- Step 2: Aggregate the filtered places into H3 cells and calculate the suitability score. -- Each place's location is converted to an H3 index (at resolution 8). The query then -- calculates a weighted 'suitability_score' and individual counts for each business type -- within that cell. TileScores AS ( SELECT WITH AGGREGATION_THRESHOLD -- Convert each place's geographic point into an H3 cell index. `carto-os.carto.H3_FROMGEOGPOINT`(point, 8) AS h3_index, -- Calculate the weighted score based on the count of places of each type -- that are open during the target window. ( COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 + COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 + COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 + COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 + COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7 ) AS suitability_score, -- Also return the individual counts for each category for detailed analysis. COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) AS restaurant_count, COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) AS convenience_store_count, COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) AS bar_count, COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) AS tourist_attraction_count, COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) AS casino_count FROM -- CHANGED: This now references the CTE with the expanded area. PlacesInTargetAreaWithOpenFlag -- Group by the H3 index to ensure all calculations are per-cell. GROUP BY h3_index ), -- Step 3: Find the maximum suitability score across all cells. -- This value is used in the next step to normalize the scores to a consistent scale (e.g., 0-10). MaxScore AS ( SELECT MAX(suitability_score) AS max_score FROM TileScores ) -- Step 4: Assemble the final results. -- This joins the scored tiles with the max score, calculates the normalized score, -- generates the H3 cell's polygon geometry for mapping, and orders the results. SELECT ts.h3_index, -- Generate the hexagonal polygon for the H3 cell for visualization. `carto-os.carto.H3_BOUNDARY`(ts.h3_index) AS h3_geography, ts.restaurant_count, ts.convenience_store_count, ts.bar_count, ts.tourist_attraction_count, ts.casino_count, ts.suitability_score, -- Normalize the score to a 0-10 scale for easier interpretation. ROUND( CASE WHEN ms.max_score = 0 THEN 0 ELSE (ts.suitability_score / ms.max_score) * 10 END, 2 ) AS normalized_suitability_score FROM -- A cross join is efficient here as MaxScore contains only one row. TileScores ts, MaxScore ms -- Display the highest-scoring locations first. ORDER BY normalized_suitability_score DESC;
Wyświetlenie tych wyników na mapie ujawnia wyraźnie zwycięskie lokalizacje. Najciemniejsze fioletowe kafelki, znajdujące się głównie w pobliżu Las Vegas Strip i Downtown, to obszary o największym potencjale dla naszej nowej kawiarni.
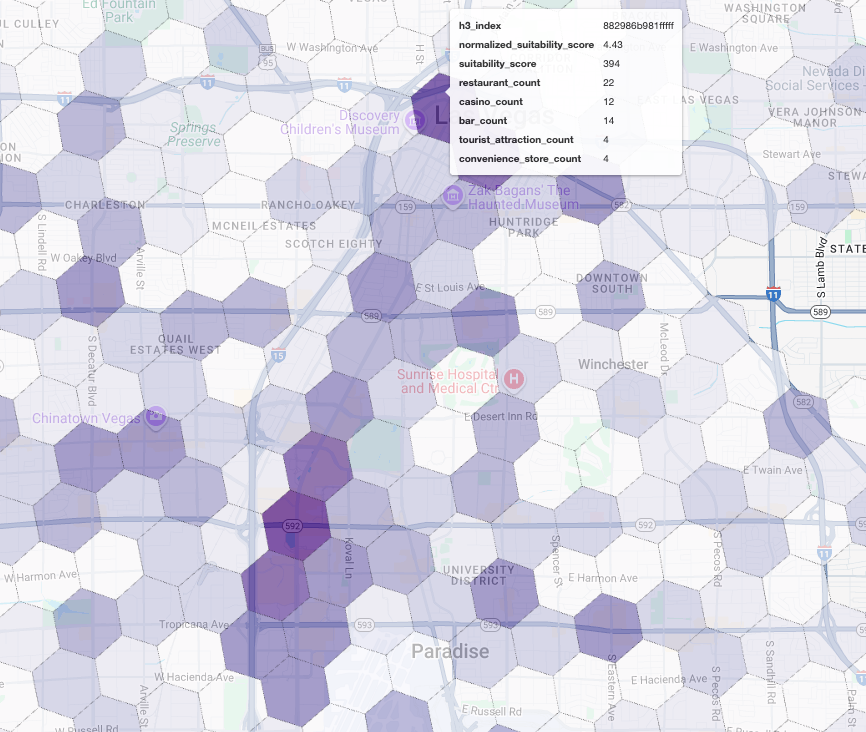
Analiza konkurencji: identyfikacja istniejących kawiarni
Nasz model przydatności skutecznie zidentyfikował najbardziej obiecujące strefy, ale sam wysoki wynik nie gwarantuje sukcesu. Musimy teraz nałożyć na to dane konkurencji. Idealna lokalizacja to obszar o dużym potencjale i niskiej gęstości istniejących kawiarni, ponieważ szukamy wyraźnej luki na rynku.
W tym celu używamy funkcjiPLACES_COUNT_PER_H3. Ta funkcja została zaprojektowana tak, aby skutecznie zwracać liczbę miejsc w określonym obszarze geograficznym według komórki H3.
Najpierw dynamicznie określamy obszar metropolitalny Las Vegas.
Zamiast polegać na jednej lokalizacji, wysyłamy zapytanie do publicznego zbioru danych Overture Maps, aby uzyskać granice Las Vegas i jego najważniejszych okolicznych miejscowości, i łączymy je w jeden wielokąt z ST_UNION_AGG. Następnie przekazujemy ten obszar do funkcji, prosząc ją o policzenie wszystkich działających kawiarni.
To zapytanie definiuje obszar metropolitalny i wywołuje funkcję, aby uzyskać liczbę kawiarni w komórkach H3:
-- Define a variable to hold the combined geography for the Las Vegas metro area.
DECLARE las_vegas_metro_area GEOGRAPHY;
-- Set the variable by fetching the shapes for the five localities from Overture Maps
-- and merging them into a single polygon using ST_UNION_AGG.
SET las_vegas_metro_area = (
SELECT
ST_UNION_AGG(geometry)
FROM
`bigquery-public-data.overture_maps.division_area`
WHERE
country = 'US'
AND region = 'US-NV'
AND names.primary IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester')
);
-- Call the PLACES_COUNT_PER_H3 function with our defined area and parameters.
SELECT
*
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
-- Use the metro area geography we just created.
'geography', las_vegas_metro_area,
-- Specify 'coffee_shop' as the place type to count.
'types', ["coffee_shop"],
-- Best practice: Only count places that are currently operational.
'business_status', ['OPERATIONAL'],
-- Set the H3 grid resolution to 8.
'h3_resolution', 8
)
);
Funkcja zwraca tabelę zawierającą indeks komórki H3, jej geometrię, łączną liczbę kawiarni i przykładowe identyfikatory miejsc:

Łączna liczba jest przydatna, ale zobaczenie rzeczywistych konkurentów jest niezbędne.
W tym momencie przechodzimy z zbioru danych Statystyk miejsc na Places API. Wyodrębniając sample_place_ids z komórek o najwyższym znormalizowanym wyniku dopasowania, możemy wywołać interfejs Places Details API, aby pobrać szczegółowe informacje o każdym konkurentcie, takie jak nazwa, adres, ocena i lokalizacja.
Wymaga to porównania wyników poprzedniego zapytania, w którym wygenerowano wynik dopasowania, z wynikami zapytania PLACES_COUNT_PER_H3. Indeks komórki H3 może służyć do uzyskiwania liczby kawiarni i ich identyfikatorów z komórek o najwyższym znormalizowanym wyniku dopasowania.
Ten kod w Pythonie pokazuje, jak można przeprowadzić takie porównanie.
# Isolate the Top 5 Most Suitable H3 Cells
top_suitability_cells = gdf_suitability.head(5)
# Extract the 'h3_index' values from these top 5 cells into a list.
top_h3_indexes = top_suitability_cells['h3_index'].tolist()
print(f"The top 5 H3 indexes are: {top_h3_indexes}")
# Now, we find the rows in our DataFrame where the
# 'h3_cell_index' matches one of the indexes from our top 5 list.
coffee_counts_in_top_zones = gdf_coffee_shops[
gdf_coffee_shops['h3_cell_index'].isin(top_h3_indexes)
]
Mamy już listę identyfikatorów miejsc dla kawiarni, które już istnieją w komórkach H3 o najwyższym wyniku dopasowania. Możemy poprosić o dodatkowe informacje o każdym z tych miejsc.
Możesz to zrobić, wysyłając żądanie bezpośrednio do interfejsu API Szczegóły miejsca dla każdego identyfikatora miejsca lub używając biblioteki klienta do wykonania wywołania. Pamiętaj, aby ustawić parametr
FieldMask
tak, aby żądać tylko potrzebnych danych.
Na koniec łączymy wszystko w jedną, zaawansowaną wizualizację. Na warstwie podstawowej umieszczamy naszą mapę tematyczną z odcieniami fioletu, a następnie dodajemy pinezki dla każdej kawiarni pobranej z interfejsu Places API. Ta mapa końcowa zawiera podsumowanie całej naszej analizy: ciemnofioletowe obszary pokazują potencjał, a zielone pinezki – rzeczywistość obecnego rynku.

Szukając ciemnofioletowych komórek z niewielką liczbą pinezek lub bez nich, możemy z dużą pewnością wskazać dokładne obszary, które stanowią najlepszą okazję do otwarcia nowej lokalizacji.
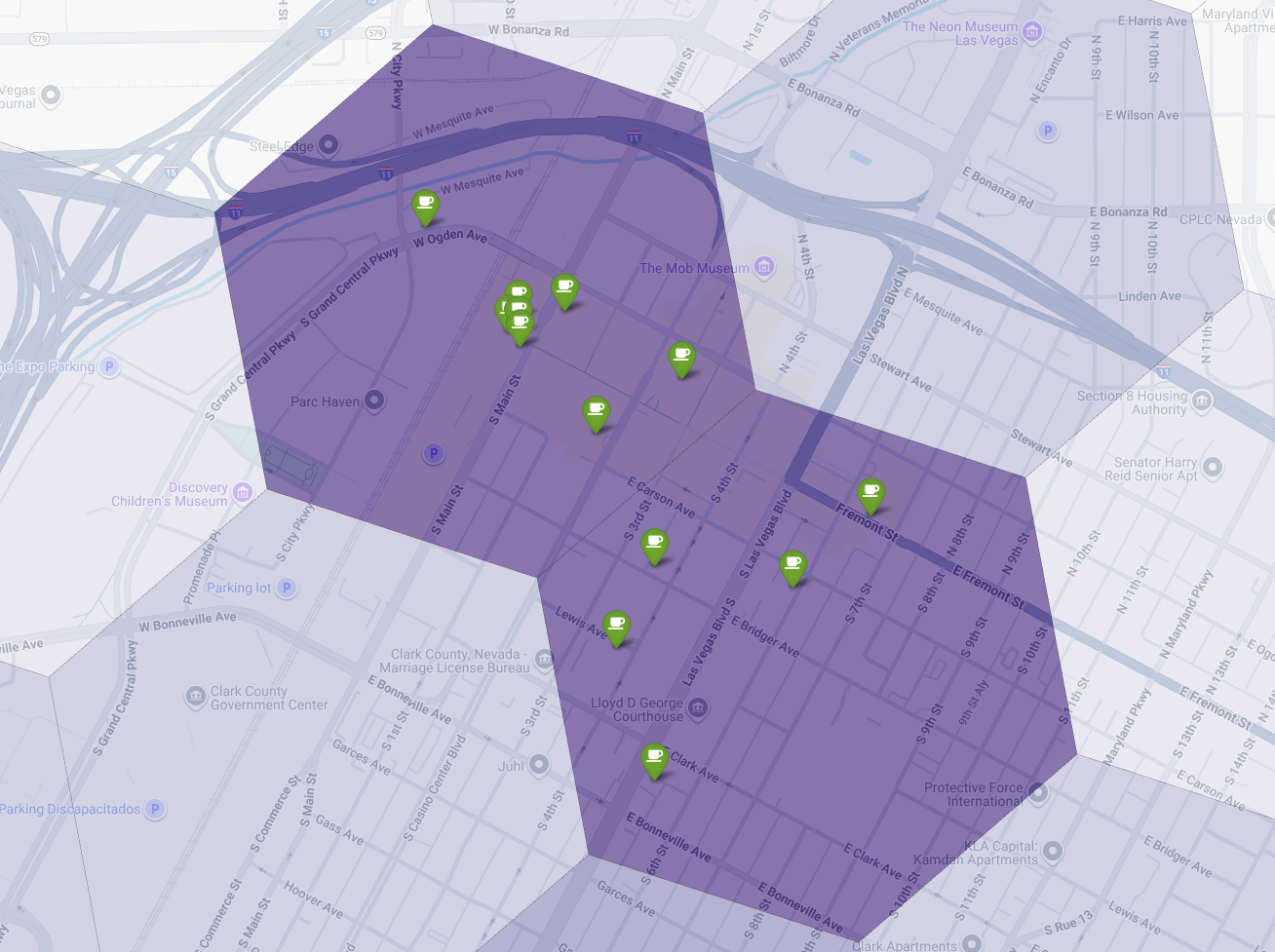
Powyższe 2 komórki mają wysoki wynik dopasowania, ale widać w nich pewne luki, które mogą być potencjalnymi lokalizacjami naszej nowej kawiarni.
Podsumowanie
W tym dokumencie przeszliśmy od pytania o to, gdzie rozszerzyć działalność, na poziomie całego stanu do odpowiedzi opartej na danych lokalnych. Łącząc różne zbiory danych i stosując niestandardową logikę biznesową, możesz systematycznie zmniejszać ryzyko związane z podejmowaniem ważnych decyzji biznesowych. Ten przepływ pracy, który łączy skalę BigQuery, bogactwo Statystyk miejsc i szczegółowość w czasie rzeczywistym interfejsu Places API, stanowi zaawansowany szablon dla każdej organizacji, która chce wykorzystywać informacje o lokalizacji do strategicznego rozwoju.
Dalsze kroki
- Dostosuj ten przepływ pracy do własnej logiki biznesowej, docelowych obszarów geograficznych i własnych zbiorów danych.
- Aby jeszcze bardziej wzbogacić model, zapoznaj się z innymi polami danych w zbiorze danych Places Insights, takimi jak liczba opinii, poziomy cen i oceny użytkowników.
- Zautomatyzuj ten proces, aby utworzyć wewnętrzny panel wyboru lokalizacji, który można wykorzystać do dynamicznej oceny nowych rynków.
Więcej informacji znajdziesz w dokumentacji:
Współtwórcy
Henrik Valve | Inżynier DevX